Redshift Overview
Redshift là một dịch vụ lưu trữ dữ liệu và phân tích dữ liệu trực tuyến (OLAP) do Amazon cung cấp. Nó được xây dựng dựa trên cơ sở dữ liệu quan hệ PostgreSQL, nhưng không được sử dụng cho các hoạt động xử lý giao dịch trực tuyến (OLTP). Thay vào đó, nó được sử dụng cho các tác vụ phân tích và xử lý dữ liệu lớn.
Redshift cung cấp hiệu suất gấp 10 lần so với các data warehouse khác và có thể mở rộng lên đến hàng Petabyte dữ liệu. Nó lưu trữ dữ liệu theo cột thay vì theo hàng và sử dụng một hệ thống truy vấn song song để tăng tốc độ truy vấn. Điều này cho phép Redshift xử lý các truy vấn, các thao tác kết nối và tính tổng các bộ dữ liệu lớn một cách nhanh chóng và hiệu quả hơn.
Redshift cung cấp giao diện SQL cho phép người dùng truy vấn dữ liệu một cách dễ dàng. Nó tích hợp với nhiều công cụ Business Intelligence (BI) như Amazon QuickSight hoặc Tableau để giúp người dùng dễ dàng trực quan hóa dữ liệu và tạo các báo cáo phân tích.
So với dịch vụ Athena của Amazon, Redshift cho phép thực hiện các truy vấn, các thao tác kết nối và tính tổng các bộ dữ liệu lớn một cách nhanh chóng hơn nhờ sử dụng các chỉ mục (indexes) giúp tăng tốc độ truy vấn. Athena, ngược lại, là dịch vụ truy vấn trực tiếp dữ liệu lưu trữ trên Amazon S3 và không có khả năng tạo chỉ mục, do đó không thể đạt được hiệu suất truy vấn cao như Redshift.
Redshift Cluster
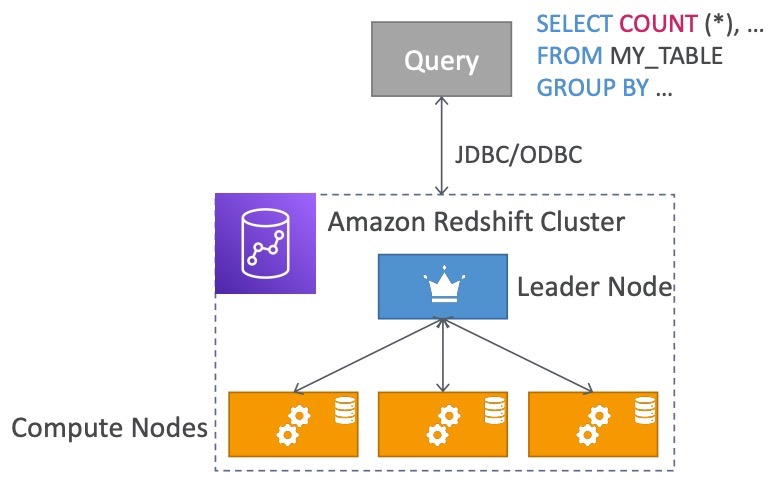
Hệ thống này bao gồm hai loại node chính: Leader node và Compute node.
Leader node có trách nhiệm quản lý, phân tích kế hoạch truy vấn và tổng hợp kết quả truy vấn. Trong khi đó, Compute node sẽ xử lý truy vấn và gửi kết quả trả về cho Leader node.
Trong quá trình triển khai, kích thước của các node được cấu hình trước. Ngoài ra, người dùng cũng có thể sử dụng Reserved Instances để giảm chi phí sử dụng hệ thống.
Redshift – Snapshots & DR
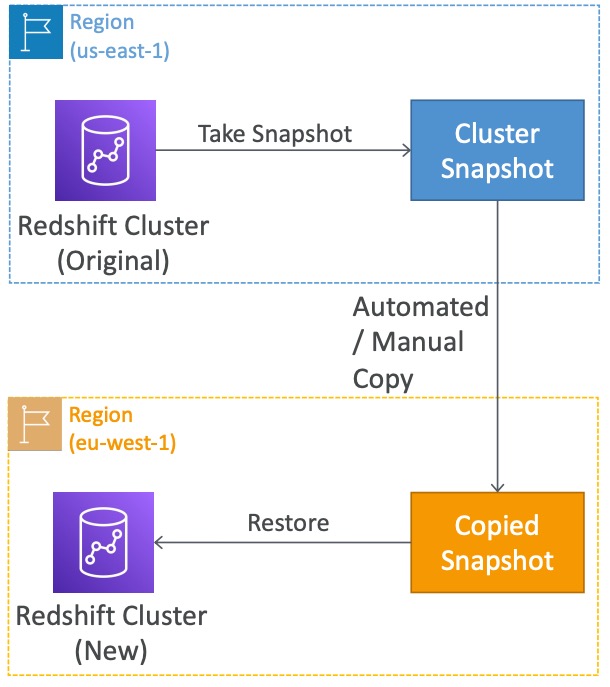
Các tính năng về backup và recovery trong Amazon Redshift:
- Redshift cung cấp chế độ “Multi-AZ” cho một số cluster, cho phép sao lưu đồng bộ dữ liệu sang nhiều khu vực khác nhau để đảm bảo sẵn sàng cao và chống lại sự cố khu vực.
- Redshift hỗ trợ tính năng snapshot, cho phép sao lưu dữ liệu của một cluster tại một thời điểm nhất định và lưu trữ trên S3. Snapshot chỉ lưu lại các phần đã thay đổi từ lần sao lưu trước, giúp tiết kiệm tài nguyên lưu trữ.
- Snapshot có thể được khôi phục để tạo ra một cluster mới.
- Redshift cung cấp tính năng sao chép tự động các snapshot của một cluster sang một khu vực khác trong AWS. Bạn có thể thiết lập sao chép tự động cho các snapshot được tạo bằng cách định cấu hình theo lịch trình hoặc theo dung lượng (mỗi 5 GB hoặc 8 giờ). Bạn có thể thiết lập thời gian giữ lại từ 1 đến 35 ngày cho các snapshot. Bên cạnh đó, bạn có thể tạo snapshot thủ công và giữ chúng trong bất kỳ khoảng thời gian nào cho đến khi bạn xóa chúng.
Loading data into Redshift: Large inserts are MUCH better
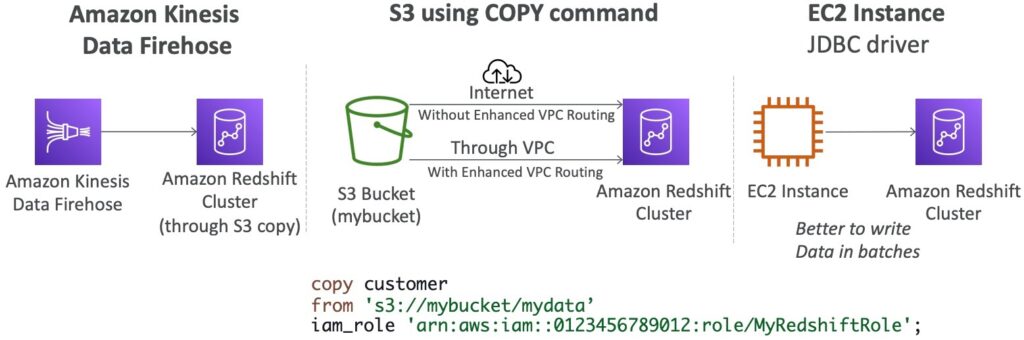
Đây là các phương pháp để di chuyển dữ liệu vào Amazon Redshift, một hệ thống cơ sở dữ liệu quan hệ mạnh mẽ, được thiết kế để phân tích dữ liệu lớn và thực hiện các truy vấn phức tạp.
- Amazon Kinesis Data Firehose là một dịch vụ quản lý dữ liệu trực tuyến (streaming data) của AWS, cho phép lấy dữ liệu từ nhiều nguồn, xử lý và chuyển đến các đích như S3, Redshift, Elasticsearch… Khi sử dụng Kinesis Data Firehose để gửi dữ liệu vào Redshift, ta có thể sử dụng COPY command để di chuyển dữ liệu vào Redshift một cách tự động và hiệu quả.
- S3 using COPY command là một phương pháp khác để di chuyển dữ liệu vào Redshift. Ta có thể đưa dữ liệu vào S3, sau đó sử dụng COPY command để di chuyển dữ liệu từ S3 vào Redshift.
- EC2 Instance JDBC driver là một driver JDBC (Java Database Connectivity) cho phép ta truy cập và thao tác trực tiếp với Redshift từ một instance EC2. Khi sử dụng driver
Redshift Spectrum
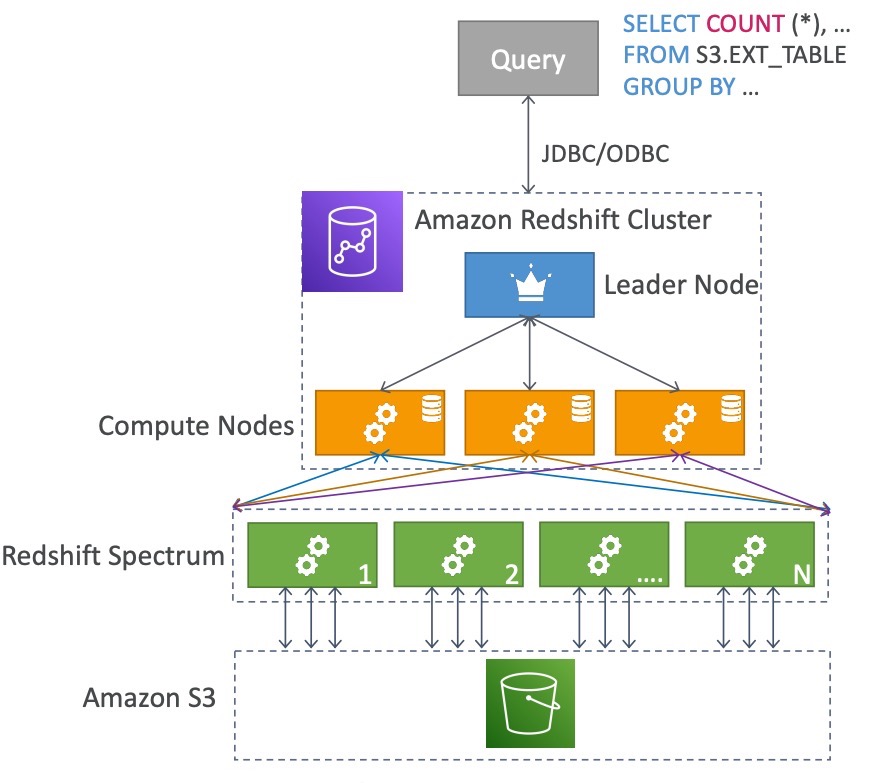
Redshift Spectrum là một tính năng của Amazon Redshift, cho phép truy vấn dữ liệu trực tiếp từ Amazon S3 mà không cần phải sao chép dữ liệu vào Redshift Cluster. Khi bạn muốn truy vấn một lượng lớn dữ liệu trong S3 mà không muốn mất thời gian di chuyển dữ liệu đó vào Redshift Cluster, bạn có thể sử dụng Redshift Spectrum. Redshift Spectrum sử dụng một loạt các nodes đặc biệt trong hệ thống để truy vấn dữ liệu trong S3 một cách nhanh chóng và hiệu quả. Để sử dụng Redshift Spectrum, bạn phải có một Redshift Cluster đã được cấu hình và sẵn sàng để tiếp nhận các truy vấn từ Spectrum.


{kind=link}