Disaster Recovery Overview
Disaster Recovery (DR) là quá trình chuẩn bị và phục hồi sau một thảm họa bất kỳ gây ảnh hưởng tiêu cực đến khả năng liên tục hoạt động kinh doanh hoặc tài chính của một công ty. DR có thể xảy ra ở nhiều dạng khác nhau, bao gồm:
- On-premise => On-premise: DR truyền thống trên nền tảng on-premise, tuy nhiên rất đắt đỏ.
- On-premise => AWS Cloud: phục hồi hybrid trên đám mây AWS.
- AWS Cloud Region A => AWS Cloud Region B: phục hồi trong cùng đám mây AWS giữa hai khu vực khác nhau. Để triển khai DR, cần định nghĩa hai thuật ngữ sau:
- Recovery Point Objective (RPO): là thời điểm gần nhất mà dữ liệu phải được phục hồi để đảm bảo giảm thiểu mất mát dữ liệu trong trường hợp xảy ra sự cố. RPO càng thấp, thì sự mất mát dữ liệu càng ít nhưng chi phí cũng càng cao.
- Recovery Time Objective (RTO): là thời gian tối đa cho phép để phục hồi lại các hệ thống, dịch vụ hoặc ứng dụng sau khi xảy ra sự cố. RTO càng thấp, thì thời gian gián đoạn hoạt động càng ít nhưng chi phí cũng càng cao.
RPO and RTO
RPO (Recovery Point Objective) và RTO (Recovery Time Objective) là hai khái niệm quan trọng trong kế hoạch phục hồi sau thảm họa (disaster recovery) của một doanh nghiệp.
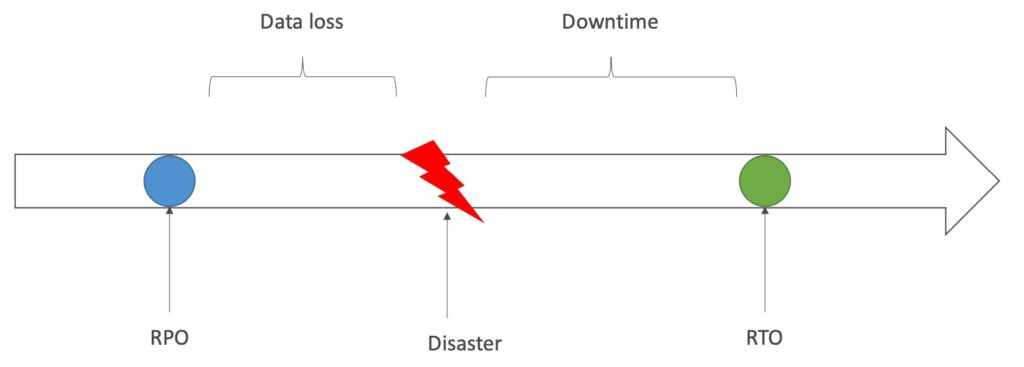
RPO đề cập đến khoảng thời gian tối đa giữa các điểm phục hồi dữ liệu. Nó thể hiện khoảng thời gian tối đa giữa các lần sao lưu dữ liệu. Ví dụ: nếu doanh nghiệp đặt RPO của mình là 1 giờ, nghĩa là dữ liệu được sao lưu ít nhất mỗi giờ một lần. Nếu xảy ra sự cố, dữ liệu bị mất không được sao lưu trong khoảng thời gian đó sẽ không thể khôi phục được.
RTO đề cập đến khoảng thời gian tối đa mà một hệ thống phải được khôi phục lại sau khi một sự cố xảy ra. RTO thể hiện thời gian cần thiết để phục hồi hệ thống từ trạng thái bị sự cố đến trạng thái bình thường hoạt động trở lại. Ví dụ: Nếu doanh nghiệp đặt RTO của mình là 4 giờ, nghĩa là trong trường hợp xảy ra sự cố, hệ thống phải được khôi phục lại trong vòng 4 giờ để tránh tình trạng gián đoạn hoạt động quá lâu gây thiệt hại cho doanh nghiệp.
RPO và RTO là hai yếu tố quan trọng trong kế hoạch phục hồi sau thảm họa. Việc xác định RPO và RTO phù hợp sẽ giúp doanh nghiệp đưa ra kế hoạch phục hồi hiệu quả và nhanh chóng trong trường hợp xảy ra sự cố.
Disaster Recovery Strategies
Các chiến lược phục hồi sau thiên tai:
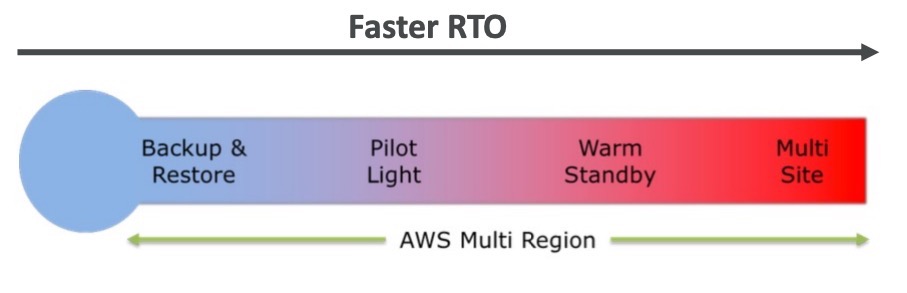
- Backup và Restore: Chiến lược này bao gồm sao lưu tất cả các dữ liệu và hệ thống để phục hồi sau thiên tai. Thông thường, các tập tin sao lưu được lưu trữ ngoài địa điểm của các hệ thống cơ bản. Khi xảy ra sự cố, các tập tin này được phục hồi trở lại để khôi phục hệ thống.
- Pilot Light: Đây là một kiểu dự phòng mà chỉ cần bật chế độ tối thiểu của các hệ thống để duy trì sự hoạt động cơ bản. Các dịch vụ được giữ ở chế độ tiết kiệm năng lượng để giảm chi phí và được bật lại trong trường hợp xảy ra thiên tai.
- Warm Standby: Chiến lược này yêu cầu duy trì một số lượng lớn hơn các tài nguyên dự phòng so với Pilot Light. Một phần của hệ thống được giữ ở chế độ sẵn sàng để phục hồi dữ liệu và các chức năng chính. Khi xảy ra sự cố, các tài nguyên dự phòng được kích hoạt để đáp ứng nhu cầu của người dùng.
- Hot Site / Multi Site Approach: Chiến lược này yêu cầu việc triển khai một trung tâm dữ liệu thứ hai, được duy trì liên tục. Dữ liệu được đồng bộ hóa giữa hai trung tâm dữ liệu để đảm bảo rằng người dùng sẽ không bị gián đoạn khi có sự cố xảy ra tại một trong các trung tâm dữ liệu. Các kỹ thuật như tải cân bằng tải và kiến trúc trung tâm dữ liệu phân tán được sử dụng để đảm bảo sự khả dụng của hệ thống.
Backup and Restore (High RPO)
Phương pháp sao lưu và khôi phục (Backup and Restore) là một chiến lược phục hồi thảm họa trong đó dữ liệu được sao lưu thường xuyên từ hệ thống chính và được lưu trữ ở một nơi khác. Trong trường hợp xảy ra sự cố, dữ liệu được khôi phục từ sao lưu gần nhất. Tuy nhiên, thời gian phục hồi (RTO) và khoảng thời gian giữa các lần sao lưu (RPO) có thể khá lớn và không thể chấp nhận được đối với các ứng dụng quan trọng và yêu cầu hoạt động liên tục.
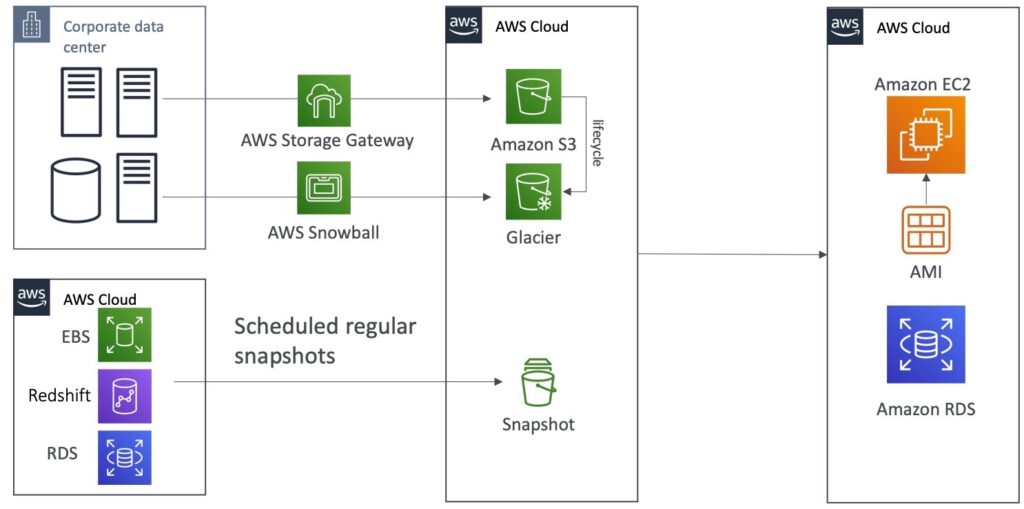
Chiến lược này được sử dụng cho các hệ thống có RPO cao (lớn hơn một ngày) và RTO lớn (từ vài giờ đến vài ngày) và thường được sử dụng cho các ứng dụng không quan trọng hoặc ít quan trọng, nơi mất mát dữ liệu trong khoảng thời gian giữa các lần sao lưu là không quan trọng hoặc có thể chấp nhận được.
Disaster Recovery – Pilot Light
Pilot Light là một phương pháp khôi phục sau thảm họa trong đó một phiên bản nhỏ của ứng dụng luôn chạy trên đám mây. Phương pháp này thường được sử dụng cho những hệ thống quan trọng (gọi là “hạt nhân quan trọng”) để giúp đảm bảo rằng nếu một thảm họa xảy ra, hệ thống có thể được khôi phục nhanh chóng.
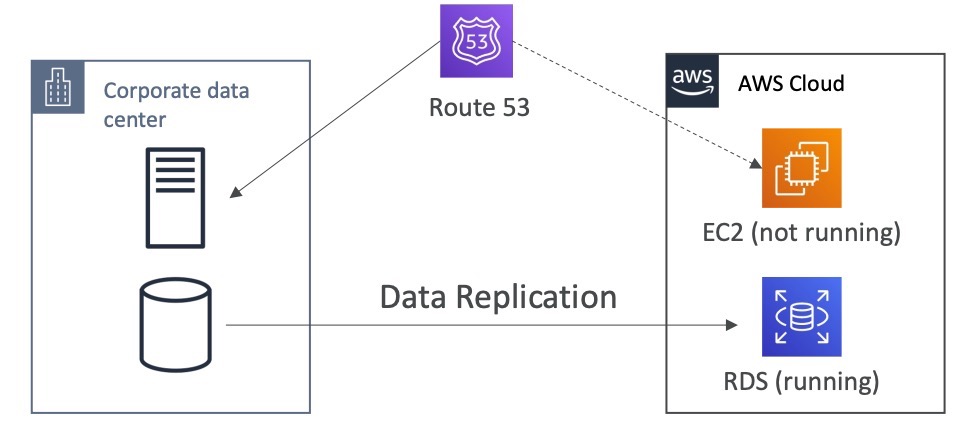
Một điểm khác biệt chính giữa Pilot Light và Backup and Restore là trong Pilot Light, những hệ thống quan trọng đã được cài đặt và sẵn sàng để sử dụng ngay lập tức, trong khi Backup and Restore phải đợi quá trình khôi phục để khởi động lại các hệ thống quan trọng. Do đó, Pilot Light có thể nhanh hơn và đáp ứng được RTO (Recovery Time Objective – Mục tiêu thời gian khôi phục) nhanh hơn.
Tuy nhiên, cần lưu ý rằng Pilot Light yêu cầu nhiều tài nguyên hơn để duy trì phiên bản nhỏ của ứng dụng luôn chạy trên đám mây, do đó chi phí cao hơn so với Backup and Restore.
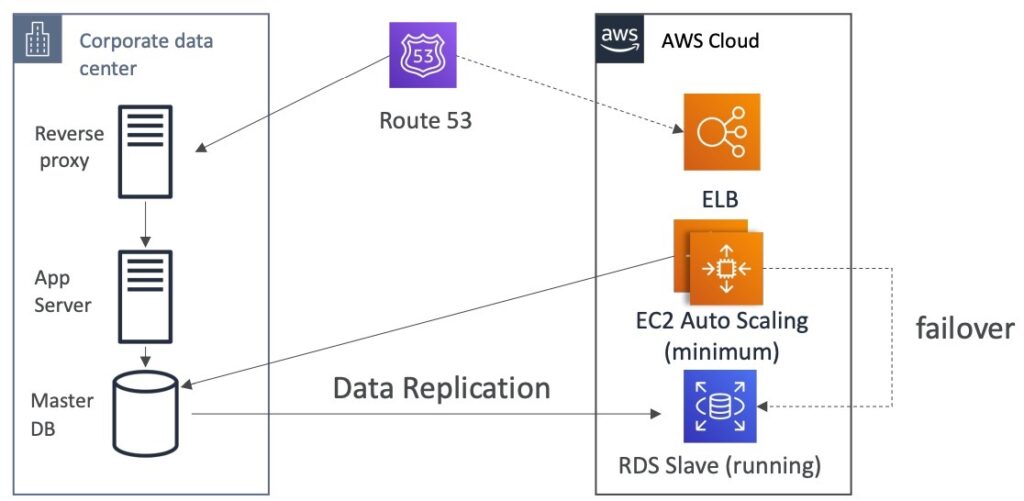
Warm Standby
Warm Standby là một chiến lược phòng chống thiên tai cho phép một phiên bản nhỏ hơn của ứng dụng luôn chạy trên đám mây. Hệ thống này hoạt động ở mức độ tối thiểu, nghĩa là chỉ có một số thiết bị được bật để tiết kiệm chi phí và tài nguyên. Khi có thảm họa xảy ra, ta có thể tăng cường kích thước của hệ thống và mở rộng quy mô đến sản xuất. So với phương pháp Backup and Restore, Warm Standby nhanh hơn do hệ thống đã sẵn sàng ở mức độ hoạt động gần với sản xuất. Tuy nhiên, chi phí cho Warm Standby thường cao hơn so với Backup and Restore do yêu cầu phải duy trì một số thiết bị luôn hoạt động.
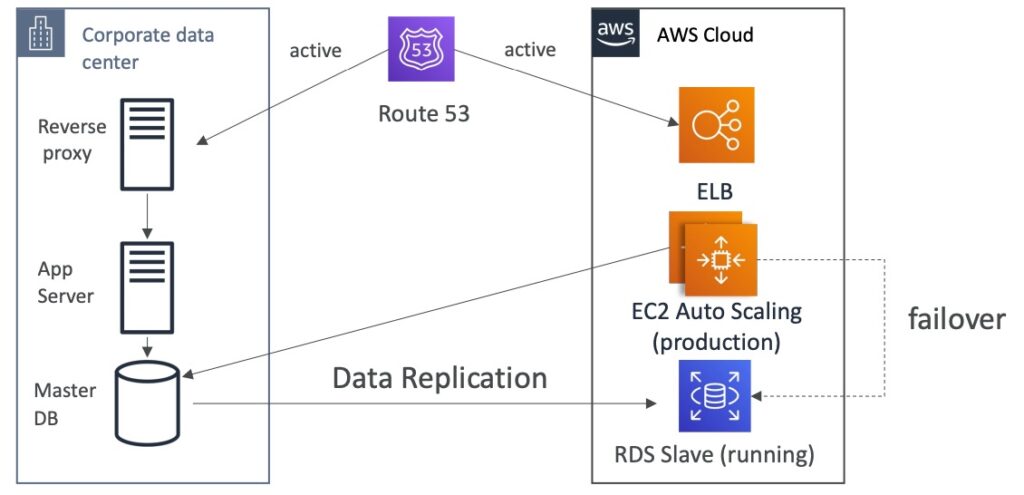
Multi Site / Hot Site Approach
Multi Site / Hot Site Approach là một chiến lược phục hồi thảm họa có RTO rất thấp (tính bằng phút hoặc giây), tuy nhiên lại rất đắt đỏ. Trong chiến lược này, toàn bộ sản phẩm đã được sản xuất sẽ được đưa vào hoạt động ở cả hai hoặc nhiều trung tâm dữ liệu AWS và trung tâm dữ liệu On-Premises. Khi xảy ra sự cố, chúng ta sẽ tự động chuyển đổi sang các trung tâm dữ liệu khác để duy trì tính khả dụng của ứng dụng. Với chiến lược này, có thể đạt được RTO rất thấp, tuy nhiên đòi hỏi chi phí đầu tư cho việc thiết lập và vận hành hạ tầng khá cao.
All AWS Multi Region
AWS Multi Region là một phương pháp triển khai hạ tầng trên nhiều khu vực khác nhau của AWS. Điều này cho phép các tổ chức triển khai ứng dụng của họ trên nhiều vị trí khác nhau trên toàn cầu, tăng tính sẵn sàng và khả năng khôi phục sau sự cố.
Sử dụng AWS Multi Region, các tổ chức có thể triển khai tất cả các thành phần của ứng dụng trên nhiều khu vực AWS khác nhau và có khả năng đồng bộ hóa dữ liệu giữa các khu vực đó. Các tổ chức có thể triển khai các tài nguyên đến nhiều khu vực và định cấu hình dịch vụ như Amazon Route 53 và Amazon Elastic Load Balancing để phân phối tải và cân bằng tải trên các khu vực khác nhau.
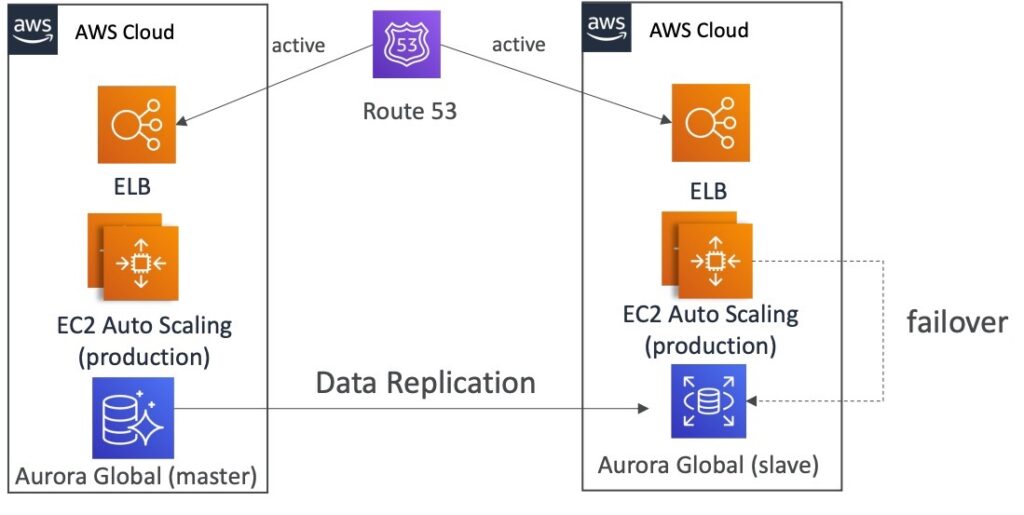
Với AWS Multi Region, các tổ chức cũng có thể sử dụng các dịch vụ như Amazon S3 và Amazon RDS để lưu trữ và quản lý cơ sở dữ liệu của họ trên nhiều khu vực khác nhau để đảm bảo tính khả dụng cao và khả năng phục hồi sau sự cố.
Disaster Recovery Tips
Dưới đây là các gợi ý về phòng chống thiên tai và phục hồi sau thiên tai trên AWS:
- Sao lưu: Sử dụng các công cụ như EBS Snapshots, RDS automated backups/Snapshots để sao lưu dữ liệu. Ngoài ra, đẩy dữ liệu thường xuyên lên S3/S3 IA/Glacier, sử dụng chính sách Lifecycle, sao chép chéo khu vực để giảm thiểu thiệt hại.
- Khả năng cao: Sử dụng các dịch vụ AWS như Route53, RDS Multi-AZ, ElastiCache Multi-AZ, EFS, S3 để tăng khả năng sẵn sàng. Sử dụng Site to Site VPN như một phương tiện khôi phục từ Direct Connect.
- Sao chép: Sử dụng các công cụ sao chép như RDS Replication (Cross Region), AWS Aurora + Cơ sở dữ liệu toàn cầu, Sao chép cơ sở dữ liệu từ on-premises sang RDS.
- Cổng Storage: Sử dụng cổng lưu trữ để kết nối dữ liệu on-premises với AWS.
- Tự động hóa: Sử dụng các công cụ tự động hóa như CloudFormation/Elastic Beanstalk để tạo lại một môi trường hoàn toàn mới. Sử dụng AWS Lambda để tạo ra các tự động hóa tùy chỉnh.
- Hỗn loạn: Tạo ra các kịch bản khẩn cấp và kiểm tra bằng cách sử dụng “simian-army” như của Netflix để ngẫu nhiên chấm dứt các EC2 để đảm bảo hệ thống có khả năng chịu đựng.


{kind=link}