1. Tổng quan về 2 loại pool trong Ceph.
Độ bền dữ liệu (data durability) là khả năng duy trì dữ liệu ngay cả khi một hoặc nhiều OSD bị hỏng. Trong Ceph, dữ liệu được lưu trữ trong các pool và có hai loại pool chính:

- Replicated Pool (Sao chép dữ liệu): Đây là kiểu lưu trữ mặc định của Ceph, nơi mỗi object được sao chép từ một OSD chính sang một hoặc nhiều OSD phụ.
- Erasure-coded Pool (Mã xóa dữ liệu): Loại pool này giúp tiết kiệm dung lượng lưu trữ hơn so với replication nhưng đòi hỏi nhiều tài nguyên CPU và RAM hơn để truy xuất hoặc khôi phục dữ liệu.
Sự khác biệt giữa Replicated Pool và Erasure-coded Pool
Replicated Pool
- Mỗi object được sao chép n lần (thông thường là 3x mặc định trong Ceph).
- Đòi hỏi dung lượng lưu trữ lớn hơn, vì dữ liệu được nhân bản theo tỷ lệ n.
- Ít tiêu tốn tài nguyên hệ thống hơn khi đọc/ghi dữ liệu.
- Phù hợp với các workload yêu cầu hiệu suất đọc cao, như database hoặc máy ảo.
Erasure-coded Pool
- Dữ liệu được chia thành k mảnh và thêm m mảnh mã hóa để đảm bảo khả năng phục hồi.
- Hiệu quả sử dụng dung lượng cao hơn: Ví dụ, với k=4, m=2, chỉ cần 1.5 lần dung lượng lưu trữ thay vì 3 lần như replication.
- Đòi hỏi tài nguyên CPU và RAM cao hơn khi khôi phục dữ liệu.
- Phù hợp cho các hệ thống lưu trữ dữ cold storage với các dữ liệu ít truy cập.
2. Cách hoạt động của Erasure Coding trong Ceph
Mã xóa (erasure coding) chia nhỏ một object thành k mảnh dữ liệu và m mảnh mã hóa, sau đó phân tán chúng lên nhiều OSD khác nhau. Nếu một OSD bị lỗi, Ceph có thể tái tạo lại dữ liệu bằng cách sử dụng các mảnh còn lại thông qua thuật toán mã xóa.
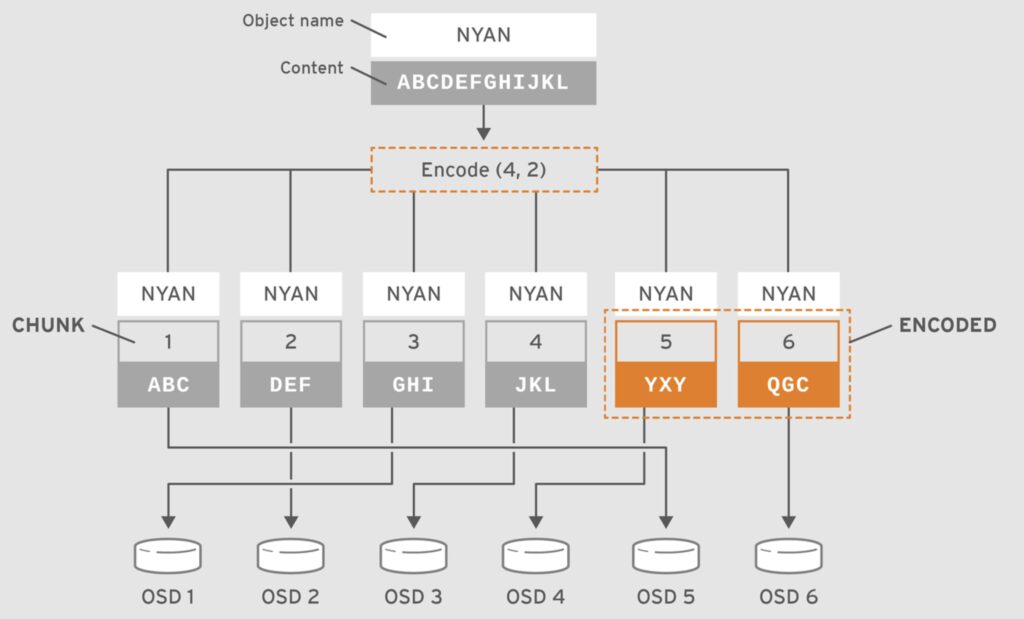
Ví dụ bạn có 8 node OSD, mỗi node có 22 OSD, tổng cộng 176 OSD.
Bạn thiết lập k = 6, m = 2, nghĩa là:
- 6 phần dữ liệu (data chunks)
- 2 phần mã hóa (coding chunks)
- Tổng cộng 8 OSD sẽ tham gia lưu trữ mỗi object (k + m = 8)
Chịu lỗi tối đa bao nhiêu OSD hỏng?
- Vì m = 2, bạn có thể chịu lỗi tối đa 2 OSD hỏng mà không mất dữ liệu.
- Nếu mất hơn 2 OSD chứa các mảnh dữ liệu, Ceph không thể phục hồi toàn bộ dữ liệu và một số PG sẽ chuyển sang trạng thái
incomplete.
Chịu lỗi tối đa bao nhiêu node hỏng?
- Trường hợp 8 node với EC (k=6, m=2):
- Erasure Coding (EC) với k=6, m=2 có nghĩa là một object sẽ được chia thành 6 chunk dữ liệu + 2 chunk parity, tổng cộng là 8 chunk.
- Khi sử dụng crush-failure-domain=node, Ceph sẽ cố gắng phân tán các chunk này trên 8 node khác nhau (mỗi node chứa đúng 1 chunk của object).
- Vì vậy, nếu mất tối đa 2 node, thì vẫn còn 6 chunk, Ceph có thể phục hồi dữ liệu mà không mất mát dữ liệu.
- Vậy với 8 node, nếu không có cấu hình đặc biệt, mất hơn 1 node có thể gây mất dữ liệu.
Rủi ro chỉ xảy ra khi số node ít hơn số chunk cần lưu trữ.
- Bạn có 8 node và 8 chunk/object → Ceph cố gắng phân tán 1 chunk mỗi node.
- Trường hợp lý tưởng: Nếu 8 chunk nằm trên 8 node khác nhau, mất 2 node vẫn còn 6 chunk → an toàn.
- Nếu số node < số chunk (ví dụ: 6 node với EC 6+2)
- Một số node sẽ chứa nhiều hơn 1 chunk của cùng một object.
- Nếu một node bị mất, có thể mất hơn 2 chunk của object đó → Không đủ 6 chunk để khôi phục dữ liệu → Dữ liệu bị mất.
👉 Với 8 node, bạn vẫn an toàn khi mất 2 node. Nhưng nếu giảm xuống 7 node hoặc ít hơn, sẽ có nguy cơ mất dữ liệu vì chunk có thể bị trùng trên cùng một node.
Làm sao để kiểm tra phân bố chunk có an toàn không?
Bạn có thể kiểm tra phân bố chunk của EC bằng lệnh:
ceph osd map <pool> <object>hoặc
ceph pg dump | grep <PG_ID>Nếu bạn thấy nhiều chunk của cùng một object nằm trên một node, thì khi node đó mất, dữ liệu có thể bị mất.
Crush-failure-domain là gì?
crush-failure-domain trong Ceph xác định cấp độ phần cứng mà các chunk dữ liệu hoặc bản sao (replicas) của một object được phân tán để tối ưu độ bền và khả năng phục hồi.
Ceph hỗ trợ nhiều mức độ khác nhau để đảm bảo dữ liệu không bị mất khi có sự cố phần cứng. Các loại phổ biến gồm:
osd– Mỗi chunk được lưu trên một OSD khác nhau.- Rủi ro: Nếu một host có nhiều OSD và bị mất, có thể mất dữ liệu nếu tất cả các chunk bị mất theo.
- Phù hợp khi có nhiều node, mỗi node chỉ có vài OSD.
host– Các chunk được phân tán trên nhiều host khác nhau.- Rủi ro: Nếu một server (host) bị mất, hệ thống vẫn có thể phục hồi dữ liệu.
- Phù hợp khi mỗi host có nhiều OSD và bạn muốn chống mất dữ liệu khi mất cả một server.
chassis– Chống mất dữ liệu khi mất cả một chassis.- Phù hợp khi có nhiều server cùng đặt trong một chassis (ví dụ: blade server).
rack– Các chunk được phân tán trên nhiều rack khác nhau.- Rủi ro: Nếu mất nguyên một rack, dữ liệu vẫn có thể phục hồi.
- Phù hợp khi hệ thống có nhiều rack và cần bảo vệ chống lỗi mạng hoặc lỗi nguồn điện từng rack.
row– Chống mất dữ liệu khi mất cả một dãy (row) trong trung tâm dữ liệu.- Phù hợp khi hạ tầng có quy mô lớn, với nhiều rack trong một hàng.
datacenter– Các chunk được phân tán trên nhiều trung tâm dữ liệu khác nhau.- Rủi ro: Chỉ mất dữ liệu nếu cả hai hoặc nhiều datacenter bị mất cùng lúc.
- Phù hợp khi triển khai Ceph trên nhiều trung tâm dữ liệu để đảm bảo khả năng chống thảm họa (DR – Disaster Recovery).
region– Dữ liệu được phân tán trên nhiều khu vực địa lý khác nhau.- Phù hợp cho các tổ chức có cluster Ceph trên nhiều quốc gia hoặc châu lục.
Tóm tắt so sánh
crush-failure-domain | Chống mất dữ liệu khi mất… | Phù hợp khi |
|---|---|---|
osd | Một OSD | Cluster nhỏ, nhiều node |
host | Một server | Cluster trung bình, nhiều OSD trên mỗi host |
chassis | Một slot chassis của blade server | Hệ thống blade server |
rack | Một rack | Nhiều rack trong datacenter |
row | Một dãy rack | Trung tâm dữ liệu lớn |
datacenter | Một trung tâm dữ liệu | Hệ thống DR đa datacenter |
region | Một khu vực | Ceph trên nhiều quốc gia |
Khi nào nên chọn crush-failure-domain=node?
- Khi mỗi node có nhiều OSD, nhưng bạn muốn đảm bảo mất một node bất kỳ vẫn không mất dữ liệu thì
crush-failure-domain=nodegiúp đảm bảo rằng mất tối đa 2 node vẫn không mất dữ liệu nếu bạn cấu hình k=6, m=2 với 8 node. - Nếu bạn muốn an toàn hơn trước mất cả rack, có thể đặt
crush-failure-domain=rack.
Chịu lỗi tối đa bao nhiêu disk hỏng?
- Mỗi node có 22 OSD. Nếu các OSD chứa các chunk của cùng một object bị hỏng, dữ liệu có thể mất.
- Nếu các chunk được phân bố đồng đều, bạn có thể chịu được 2 đĩa hỏng bất kỳ, miễn là chúng không làm mất nhiều hơn 2 trong tổng số 8 chunk của object.
Dữ liệu phân tán như thế nào?
Với cấu hình k=6, m=2, mỗi object sẽ được chia thành 6 mảnh dữ liệu + 2 mảnh mã hóa, trải đều trên 8 OSD khác nhau.
Ví dụ, giả sử bạn lưu một object 100GB, nó sẽ chia ra như sau:
- 6 mảnh dữ liệu, mỗi mảnh có 100GB / 6 = 16.67GB
- 2 mảnh mã hóa, mỗi mảnh cũng 16.67GB
- Tổng dung lượng lưu trữ thực tế: 133.33GB (100GB * 8/6)
- Hiệu suất sử dụng dung lượng: 75% (so với 3x replication chỉ đạt 33%)
Ví dụ cụ thể về phân tán trên 8 node với 8 OSD chứa object:
| Node | OSD | Chunk |
|---|---|---|
| Node 1 | OSD 3 | Data 1 |
| Node 2 | OSD 5 | Data 2 |
| Node 3 | OSD 7 | Data 3 |
| Node 4 | OSD 9 | Data 4 |
| Node 5 | OSD 11 | Data 5 |
| Node 6 | OSD 13 | Data 6 |
| Node 7 | OSD 15 | Coding 1 |
| Node 8 | OSD 17 | Coding 2 |
- Nếu OSD ở Node 7 và Node 8 hỏng, Ceph vẫn phục hồi được dữ liệu.
- Nếu OSD ở Node 1, 2, 3 hỏng, Ceph mất dữ liệu.
Tóm tắt
- Chịu lỗi:
- Tối đa 2 OSD hỏng cùng một lúc mà không mất dữ liệu.
- Tối đa 1 node hỏng nếu không có cấu hình đặc biệt.
- Nếu mất >2 OSD chứa data chunks, một số PG sẽ vào trạng thái
incomplete.
- Dữ liệu phân tán:
- Dữ liệu 100GB chia thành 6 mảnh dữ liệu + 2 mảnh mã hóa, mỗi mảnh ~16.67GB.
- Tổng dung lượng lưu trữ thực tế 133.33GB (overhead 1.33x thay vì 3x của replication).
- Lưu ý quan trọng:
- Nên cấu hình crush-failure-domain=node để tránh lưu nhiều chunk của cùng một object trên cùng một node.
- Nếu mất quá 2 OSD chứa data chunks, Ceph không thể phục hồi dữ liệu.
3. Tại sao Coding 1 và Coding 2 có thể phục hồi dữ liệu cho bất kỳ Data nào bị mất?
Cơ chế Erasure Coding (EC) sử dụng mã hóa toán học để tạo ra các mảnh mã hóa (coding chunks), cho phép khôi phục lại bất kỳ mảnh dữ liệu nào bị mất, miễn là số lượng mảnh mất không vượt quá m.
Nguyên lý toán học đằng sau Erasure Coding như sau:
Erasure Coding hoạt động dựa trên mã Reed-Solomon, tương tự cách bảo vệ dữ liệu trên CD/DVD, RAID 6. Nó sử dụng tuyến tính đại số trên trường hữu hạn (Galois Field) để tạo ra mảnh mã hóa (coding chunks).
Với k = 6, m = 2, ta có:
- 6 mảnh dữ liệu gốc (D1, D2, D3, D4, D5, D6)
- 2 mảnh mã hóa (C1, C2)
Hệ thống tạo ra các mảnh mã hóa bằng cách sử dụng một ma trận hệ số (encoding matrix). Khi có mất mát dữ liệu, Ceph sử dụng ma trận nghịch đảo (decoding matrix) để tính lại giá trị các mảnh bị mất từ các mảnh còn lại.
Tính toán Coding Chunks
Mỗi coding chunk (C1, C2) là một tổ hợp tuyến tính của các data chunk (D1, D2, ..., D6):
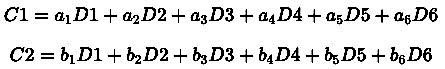
Các hệ số a1, a2, …, a6 và b1, b2, …, b6 được chọn sao cho bất kỳ 6 phần nào trong tổng số 8 phần (bao gồm dữ liệu gốc và mã hóa) cũng có thể tái tạo lại dữ liệu gốc.
Phục hồi dữ liệu khi có OSD hỏng
Giả sử D3 và D5 bị mất, nhưng còn lại D1, D2, D4, D6, C1, C2.
Hệ thống sẽ giải hệ phương trình:
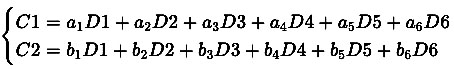
Vì ta đã biết D1, D2, D4, D6, C1, C2, hệ thống có thể tính ra D3 và D5 bằng cách giải ma trận.
- Như vậy:
- Coding 1 và Coding 2 không lưu một bản sao của bất kỳ data chunk nào, mà chứa thông tin đủ để khôi phục bất kỳ phần dữ liệu nào bị mất.
- Miễn là bạn còn 6 trong số 8 mảnh, bạn có thể tái tạo toàn bộ dữ liệu.
Vậy nên, dù mất Data 1, 2, 3, 4, 5, hay 6, ta vẫn có thể phục hồi lại nhờ Coding 1 và Coding 2.
Bạn có thể kiểm tra cách Ceph phân bố dữ liệu với lệnh sau
ceph osd map <pool> <object>
ceph pg dump
ceph osd tree
Nếu bạn cần tối ưu cấu hình, có thể chọn k=8, m=4 để tăng khả năng chịu lỗi lên 4 OSD nhưng vẫn sử dụng ít hơn so với replication.
4. Thiết lập một Erasure-coded Pool đơn giản
Tạo một pool với erasure coding (tương đương RAID5).
ceph osd pool create ecpool 50 50 erasureGhi dữ liệu vào pool:
echo ABCDEFGHI | rados --pool ecpool put NYAN -Lấy dữ liệu từ pool:
rados --pool ecpool get NYAN -Kết quả:
ABCDEFGHIErasure Code Profiles trong Ceph.
Khi tạo một erasure-coded pool, Ceph sử dụng erasure code profile để xác định cách chia nhỏ và phân tán dữ liệu. Mặc định, Ceph sử dụng k=2, m=1, nghĩa là dữ liệu sẽ được phân tán trên 3 OSD và có thể chịu mất một OSD.
Bạn có thể kiểm tra cấu hình mặc định bằng lệnh:
ceph osd erasure-code-profile get defaultKết quả:
directory=.libs
k=2
m=1
plugin=jerasure
crush-failure-domain=host
technique=reed_sol_vanTạo một profile mới để tăng độ bền dữ liệu
Giả sử cần đảm bảo dữ liệu vẫn tồn tại ngay cả khi mất 2 rack, bạn có thể tạo profile như sau:
ceph osd erasure-code-profile set myprofile \
k=4 \
m=2 \
crush-failure-domain=rackTạo pool mới với profile này:
ceph osd pool create ecpool 12 12 erasure myprofileGhi và đọc dữ liệu:
echo ABCDEFGHIJKL | rados --pool ecpool put NYAN -
rados --pool ecpool get NYAN -Kết quả:
ABCDEFGHIJKLLưu ý quan trọng khi sử dụng Erasure Coding trong Ceph
- Không sử dụng Erasure Coding cho mọi pool: Chỉ cấu hình .rgw.buckets là erasure-coded, còn các pool metadata khác nên sử dụng replication.
- Không thể thay đổi erasure code profile sau khi tạo pool: Nếu muốn thay đổi, bạn cần tạo pool mới và di chuyển dữ liệu.
- Giá trị k, m và crush-failure-domain rất quan trọng: Chúng quyết định mức độ bảo vệ dữ liệu và mức sử dụng dung lượng.
- Nếu mất số lượng OSD bằng số coding chunks (m), một số placement groups sẽ chuyển sang trạng thái “incomplete”. Để khắc phục, có thể giảm tạm thời
min_sizeđể kích hoạt quá trình phục hồi.
5. Ví dụ tổng hợp về phân tích thiết kế hệ thống Ceph với k=6, m=2, 8 node, mỗi node 22 OSD (14TB/OSD).
5.1. Công thức tính dung lượng khả dụng (usable capacity)
Dung lượng khả dụng trong Erasure Coding được tính như sau:
Dung lượng khả dụng = k/(k + m) x tổng dung lượng rawVới:
- k = 6, m = 2 (Tổng số chunk per object = 8)
- Số lượng node: 8
- Mỗi node có 22 OSD
- Dung lượng mỗi OSD: 14TB
Tổng dung lượng raw của cluster:
Tổng dung lượng raw = 8×22×14 = 2,464PBDung lượng khả dụng:
Dung lượng khả dụng = 6/(6 + 2) x 2,464 = 1,848PB🟢 Dung lượng khả dụng: ~1,848PB
🔴 Dung lượng overhead (dành cho mã hóa): ~616TB
5.2. Công thức tính số lượng node và OSD có thể chịu lỗi.
Số lượng OSD chết tối đa trước khi mất dữ liệu
Mỗi object có 8 chunk (6 data chunk + 2 parity chunk) và các chunk này được trải trên 8 OSD khác nhau do crush-failure-domain=node.
- Ceph có thể mất m = 2 OSD của bất kỳ object nào mà không mất dữ liệu.
- Nếu nhiều hơn 2 OSD chứa chunk của cùng một object chết cùng lúc, object đó sẽ bị mất dữ liệu.
Số lượng node có thể chết trước khi mất dữ liệu
- Vì
crush-failure-domain=node, Ceph cố gắng đặt mỗi chunk trên một node khác nhau. - Vì bạn có 8 node, mỗi node chứa 1 chunk của một object bất kỳ.
- Nếu mất tối đa 2 node, bạn vẫn còn 6 chunk để khôi phục dữ liệu.
⚠️ Nếu mất 3 node cùng lúc, Ceph có thể mất toàn bộ 3 chunk trong số 8 chunk của một object ⇒ mất dữ liệu.
5.3. Công thức tính số lượng node, OSD để mở rộng hệ thống
Nếu bạn muốn tăng dung lượng, số node cần thêm có thể tính theo công thức:
Số lượng node tối thiểu = m + kVì bạn đã có 8 node, muốn mở rộng thì phải đảm bảo số node vẫn ≥ 8 (để giữ nguyên mức bảo vệ dữ liệu).
Nếu thêm dung lượng, bạn chỉ cần thêm OSD vào node hiện có hoặc thêm node mới (đảm bảo số node vẫn >=8 để giữ nguyên cơ chế bảo vệ).
- Nâng cấp:
- Thêm OSD vào các node hiện tại (nếu còn slot trống).
- Thêm node mới, nhưng cần đảm bảo vẫn giữ
crush-failure-domain=nodeđể tránh mất dữ liệu khi mất nhiều OSD cùng lúc.
6. Tổng kết
Ceph cung cấp nhiều tùy chọn linh hoạt cho việc quản lý dữ liệu, giúp cân bằng giữa hiệu suất và chi phí lưu trữ.
- Replication dễ triển khai, truy xuất nhanh nhưng tốn nhiều dung lượng.
- Erasure Coding tiết kiệm dung lượng, nhưng đòi hỏi nhiều tài nguyên CPU và RAM hơn.
- Lựa chọn k và m phù hợp với yêu cầu về độ bền dữ liệu và hiệu suất hệ thống.
Hy vọng bài viết này giúp bạn hiểu rõ hơn về các chiến lược lưu trữ trong Ceph và cách áp dụng erasure coding trong hệ thống thực tế. Nếu có bất kỳ thắc mắc nào, hãy để lại bình luận nhé!
