1. Amazon Aurora là gì?
Aurora là một công nghệ độc quyền từ AWS (không được open source). Nó hỗ trợ Postgres và MySQL như là một cơ sở dữ liệu Aurora (điều đó có nghĩa là trình điều khiển của bạn sẽ hoạt động như Aurora là một cơ sở dữ liệu Postgres hoặc MySQL). Aurora được tối ưu hóa cho đám mây AWS và khẳng định tăng hiệu suất lên 5 lần so với MySQL trên RDS, hơn 3 lần hiệu suất của Postgres trên RDS. Lưu trữ Aurora tăng tự động theo khoảng cách 10GB, lên đến 128TB. Aurora có thể có tối đa 15 bản sao (replica) trong khi MySQL chỉ có 5, và quá trình sao chép dữ liệu nhanh hơn (sub 10ms replica lag). Failover trong Aurora là tức thì, nó có tính sẵn có cao (HA – High Availability). Aurora có giá thành cao hơn RDS (tăng khoảng 20%) nhưng hiệu suất tốt hơn.
2. Aurora High Availability and Read Scaling.
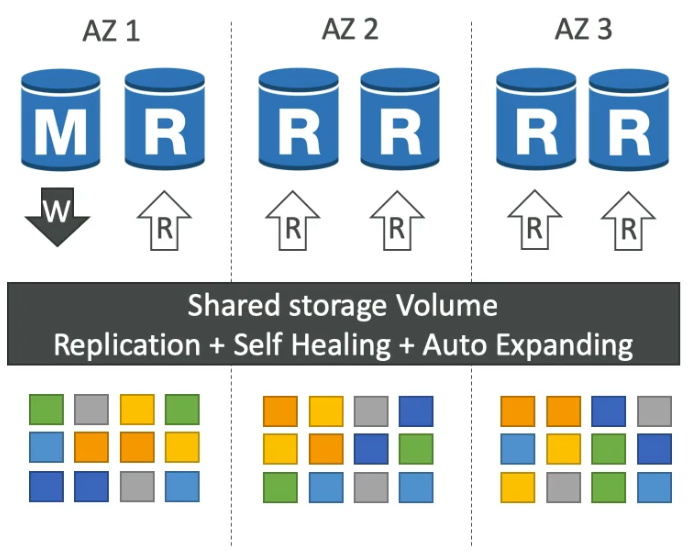
- Aurora lưu 6 bản sao dữ liệu của bạn trên 3 khu vực khác nhau (AZ).
- Đối với việc ghi dữ liệu, cần ít nhất 4 bản sao trong 6 bản sao được tạo ra.
- Đối với việc đọc dữ liệu, chỉ cần ít nhất 3 bản sao trong 6 bản sao được tạo ra.
- Aurora tự động chữa trị lỗi bằng cách sao chép dữ liệu giữa các bản sao trong các khu vực khác nhau.
- Aurora lưu trữ dữ liệu trên hàng trăm ổ đĩa khác nhau.
- Một Aurora Instance (master) sẽ nhận việc ghi dữ liệu.
- Trong trường hợp gặp sự cố, Aurora tự động chuyển vị trí ghi dữ liệu tới một replica khác trong vòng 30 giây.
- Bạn có thể sử dụng lên đến 15 bản sao (Aurora Read Replicas) để đọc dữ liệu.
- Bạn có thể sao chép dữ liệu giữa các khu vực khác nhau bằng tính năng Cross Region Replication.
3. Aurora DB Cluster.
Amazon Aurora DB Cluster là một dịch vụ quản lý cơ sở dữ liệu quan hệ của Amazon Web Services (AWS). Nó cung cấp hiệu suất và khả năng mở rộng cao hơn so với các cơ sở dữ liệu quan hệ truyền thống khác, chẳng hạn như MySQL và PostgreSQL, đồng thời cũng tích hợp một số tính năng bảo mật, khả năng sao lưu, khôi phục và tự động mở rộng.
Aurora DB Cluster sử dụng một kiến trúc mạng phân tán để sao chép dữ liệu trên các máy chủ trong cùng một khu vực hoặc khu vực khác. Với Aurora, các bản sao dữ liệu được lưu trữ trên ít nhất 3 zone khác nhau trong một khu vực, đảm bảo rằng dữ liệu được bảo vệ an toàn và sẵn sàng để phục hồi khi cần thiết.
Aurora cũng hỗ trợ đọc và ghi đồng thời trên các bản sao dữ liệu, cung cấp hiệu suất đọc/ghi tốt hơn cho các ứng dụng đòi hỏi tốc độ xử lý cao. Nó cũng cho phép tạo các bản sao đọc để phục vụ các yêu cầu đọc mà không ảnh hưởng đến bản gốc. Aurora cũng có khả năng tự động phát hiện lỗi và khởi động lại các bản sao dữ liệu nếu cần thiết.
Aurora DB Cluster cũng cung cấp tính năng tăng tốc độ đọc và ghi, hỗ trợ cho các ứng dụng đòi hỏi tốc độ xử lý cao. Nó cũng cung cấp tính năng sao lưu và khôi phục dữ liệu tự động, giúp giảm thiểu tác động của lỗi hệ thống và giúp phục hồi dữ liệu nhanh chóng.
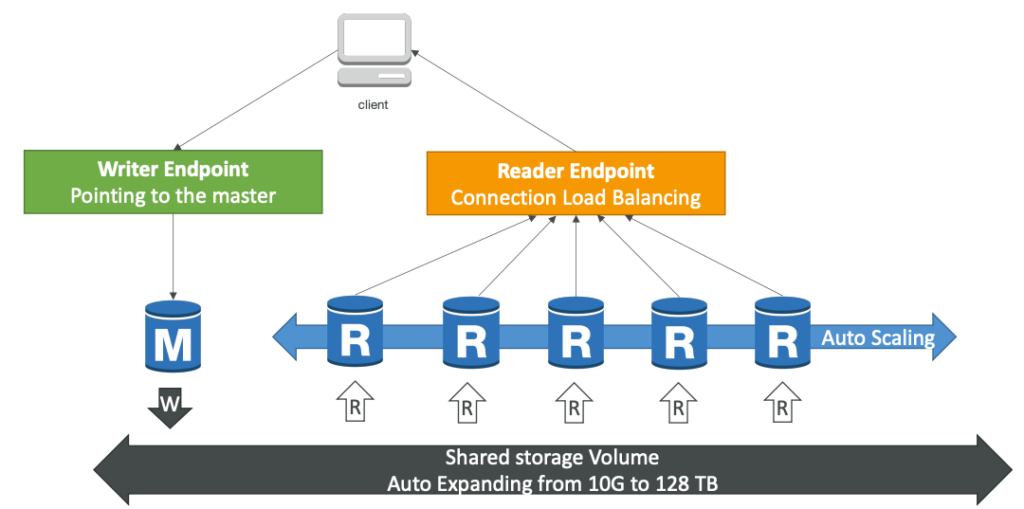
Với Aurora DB Cluster, người dùng có thể tạo nhiều bản sao dữ liệu để phục vụ các yêu cầu đọc, đồng thời có khả năng sao lưu và khôi phục dữ liệu tự động để giảm thiểu tác động của lỗi hệ thống và giúp phục hồi dữ liệu nhanh chóng. Aurora cũng có khả năng sao chép dữ liệu trên nhiều khu vực khác nhau và hỗ trợ tính năng cross-region replication, giúp tăng tính sẵn sàng và khả năng chịu lỗi của hệ thống.
4. Các tính năng của Amazon Aurora.
- Automatic fail-over: Aurora cung cấp khả năng tự động chuyển đổi sang các replica trong vòng 30 giây nếu master instance gặp sự cố, để đảm bảo khả năng hoạt động liên tục và tránh mất dữ liệu.
- Backup and Recovery: Aurora thực hiện sao lưu dữ liệu tự động và cung cấp khả năng phục hồi tự động, cho phép phục hồi dữ liệu tại bất kỳ điểm nào trong quá khứ trong vòng 5 năm.
- Isolation and security: Aurora sử dụng VPC để cô lập các instance và bảo vệ chúng bằng các tường lửa và các biện pháp bảo mật khác.
- Industry compliance: Aurora đáp ứng các yêu cầu bảo mật và tuân thủ các quy định như HIPAA, PCI, SOC và ISO.
- Push-button scaling: Aurora cung cấp khả năng tăng hoặc giảm quy mô các instance để đáp ứng nhu cầu của ứng dụng một cách linh hoạt.
- Automated Patching with Zero Downtime: Aurora cập nhật bảo mật và khắc phục các lỗi tự động và không gây ảnh hưởng đến khả năng hoạt động của ứng dụng.
- Advanced Monitoring: Aurora cung cấp công cụ giám sát tập trung để theo dõi hiệu suất và khả năng sẵn sàng của các instance.
- Routine Maintenance: Aurora cung cấp các tính năng quản lý thường xuyên để đảm bảo hoạt động ổn định và hiệu quả của hệ thống.
- Backtrack: Aurora cho phép người dùng phục hồi dữ liệu tại bất kỳ điểm nào trong quá khứ mà không cần phải sử dụng các bản sao lưu, giúp tiết kiệm thời gian và tài nguyên.
5. Thực hành.
Vào phần tạo Database.
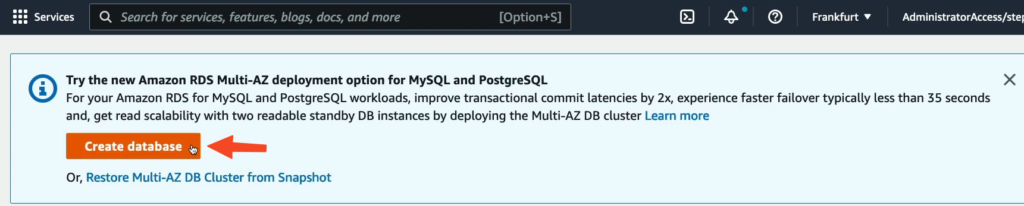
Phần Engine type chọn Amazon Aurora.
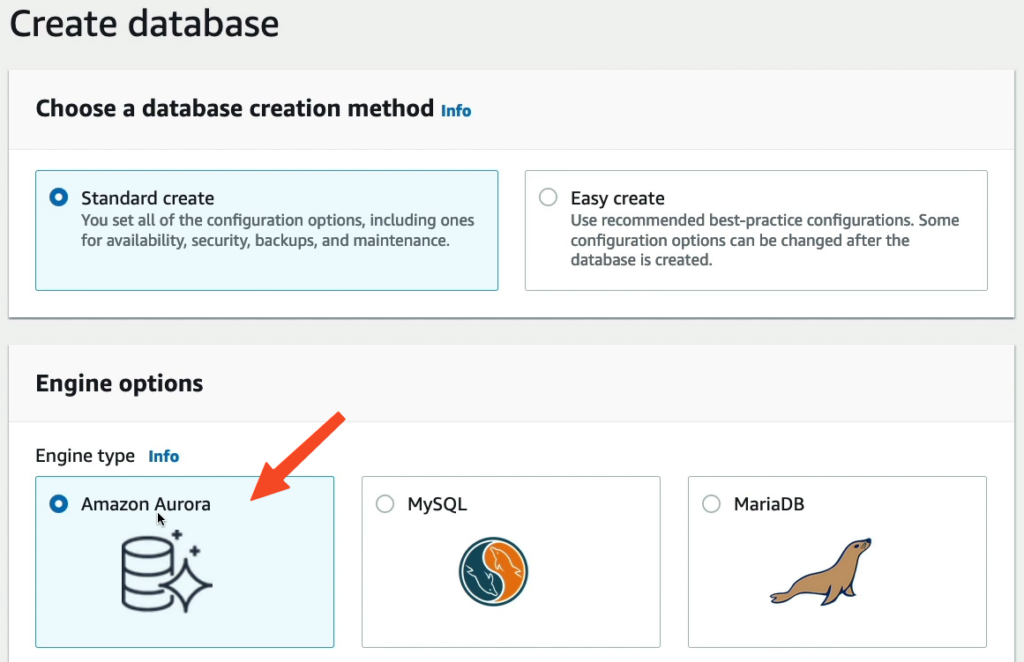
Các thành phần này liên quan đến việc hiển thị phiên bản của hệ thống cơ sở dữ liệu và các tính năng hỗ trợ của AWS RDS.
- “Show versions that support the global database feature” (Hiển thị phiên bản hỗ trợ tính năng cơ sở dữ liệu toàn cầu): cho phép người dùng chọn các phiên bản của hệ quản trị cơ sở dữ liệu (DBMS) hỗ trợ tính năng cơ sở dữ liệu toàn cầu (Global Database), giúp đồng bộ dữ liệu giữa các khu vực AWS.
- “Show versions that support the parallel query feature” (Hiển thị phiên bản hỗ trợ tính năng truy vấn song song): cho phép người dùng chọn các phiên bản DBMS hỗ trợ tính năng truy vấn song song, giúp tăng tốc độ truy vấn cho các cơ sở dữ liệu lớn.
- “Show versions that support Serverless v2” (Hiển thị phiên bản hỗ trợ Serverless v2): cho phép người dùng chọn các phiên bản của hệ quản trị cơ sở dữ liệu hỗ trợ tính năng Serverless v2, cho phép khởi động và sử dụng cơ sở dữ liệu mà không cần quản lý các máy chủ hoặc instances riêng biệt, giúp tối ưu hóa chi phí.
Phần này tôi chọn Amazon Aurora MySQL-Compatible Edition và sẽ không có tuỳ chọn bổ sung.
Một lần nữa tôi sẽ chọn Templates là Production để có nhiều thành phần giới thiệu cho các bạn.
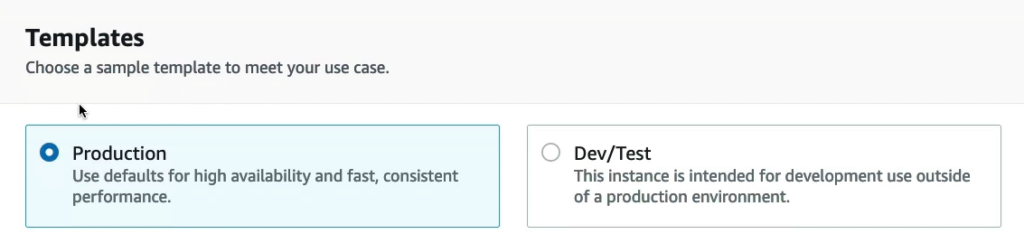
Nhập thông tin mà bạn muốn.
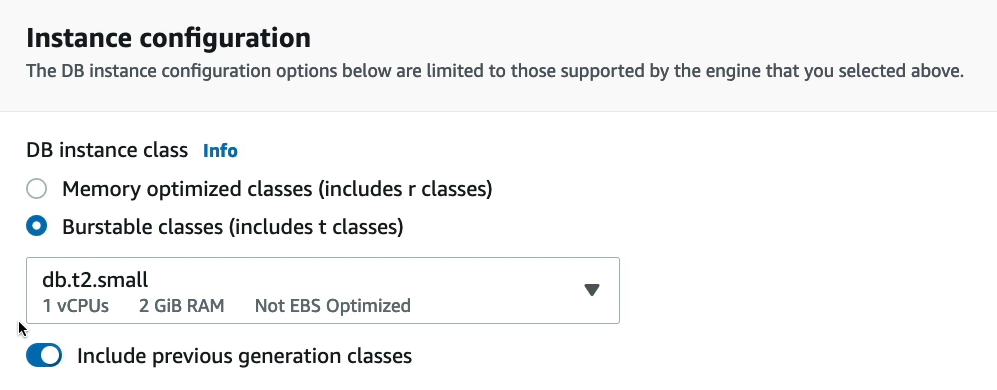
Memory optimized classes (bao gồm các lớp r) và Burstable classes (bao gồm các lớp t) là các loại máy ảo (instance types) mà bạn có thể sử dụng để chạy các cơ sở dữ liệu trên Amazon RDS.
- Memory optimized classes cung cấp khả năng xử lý và bộ nhớ cao hơn, phù hợp cho các ứng dụng đòi hỏi tính toán và bộ nhớ cao như phân tích dữ liệu, xử lý dữ liệu trực tuyến, và xử lý dữ liệu theo thời gian thực.
- Burstable classes có thể chạy với CPU thấp hơn nhưng có khả năng mở rộng động (tức là tăng hiệu suất của nó trong một khoảng thời gian ngắn) khi yêu cầu xử lý tăng lên. Loại máy ảo này thích hợp cho các ứng dụng ít tải hoặc tải biến động. Tuy nhiên, do tính chất mở rộng động, bạn cần phải chú ý đến giới hạn CPU giờ để tránh các chi phí phát sinh không mong muốn.
Include previous generation classes là một tùy chọn trong phân loại của các lớp máy ảo của Amazon RDS. Tùy chọn này cho phép bạn chọn các lớp máy ảo của thế hệ trước đó, nghĩa là các lớp được phát hành trước đó nhưng vẫn được hỗ trợ. Những lớp này có thể phù hợp với các trường hợp sử dụng cụ thể mà không cần sử dụng những tính năng mới nhất hoặc nâng cấp lớp máy ảo lên thế hệ mới hơn.
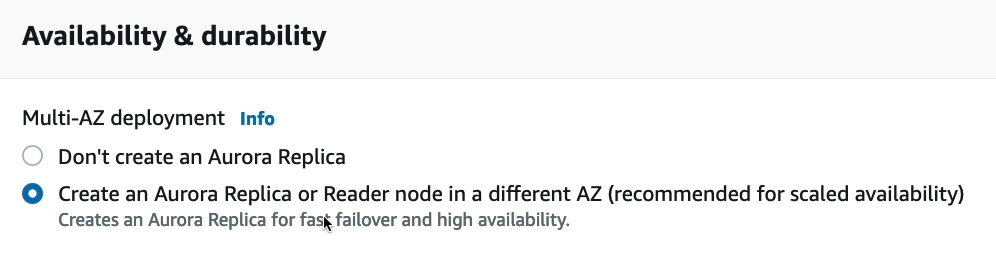
Trong Amazon Aurora, replica node được sử dụng để đảm bảo sẵn sàng và sao lưu dữ liệu. Khi tạo một Aurora cluster, bạn có thể chọn một trong hai tùy chọn sau đây:
- Don’t create an Aurora Replica: Không tạo replica node. Tùy chọn này sẽ làm cho việc sao lưu dữ liệu và khả năng sẵn sàng của database trở nên kém hơn. Nếu primary node bị lỗi, dữ liệu có thể bị mất và thời gian phục hồi có thể lâu hơn.
- Create an Aurora Replica or Reader node in a different AZ (recommended for scaled availability): Tạo replica node ở vị trí khác để tăng tính sẵn sàng và khả năng sao lưu dữ liệu. Tùy chọn này được khuyến nghị để đảm bảo sẵn sàng cao hơn cho cơ sở dữ liệu Aurora. Replica node được tạo ra ở vị trí khác, đảm bảo rằng dữ liệu được sao lưu và tăng tính khả dụng khi primary node bị lỗi. Bên cạnh đó, replica node cũng có thể được sử dụng để đọc dữ liệu mà không làm giảm hiệu suất của primary node.
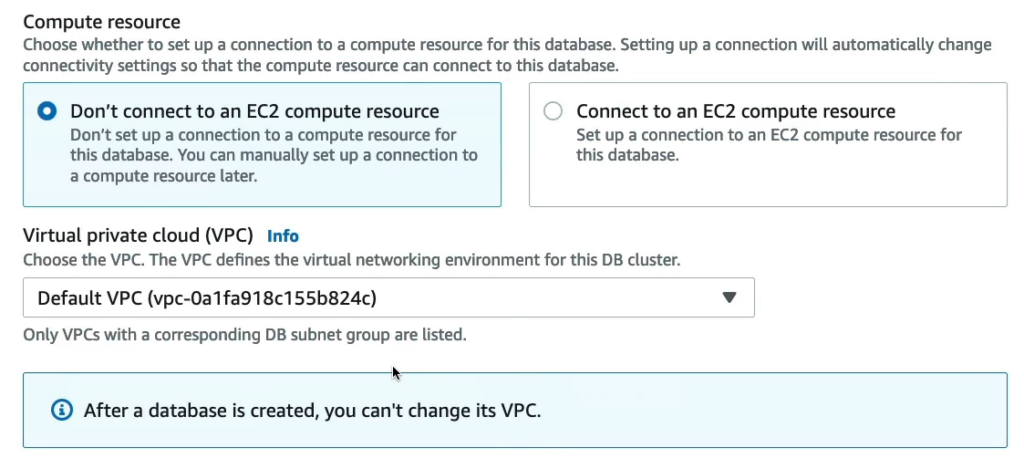
Phần Compute resource, tôi sẽ không kết nối vào một EC2 nào cả.
Public access hãy chọn Yes để các thiết bị ở ngoài có thể kết nối được.

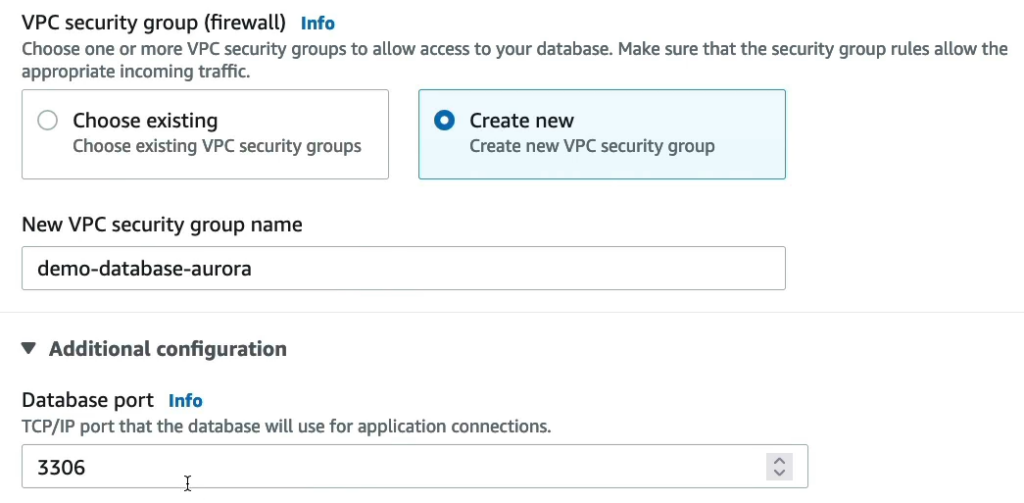
Mình sẽ tạo 1 security group mới.
Tôi sử dụng phương pháp xác thực bằng mật khẩu Password authentication.
Mình không sử dụng Monitoring.
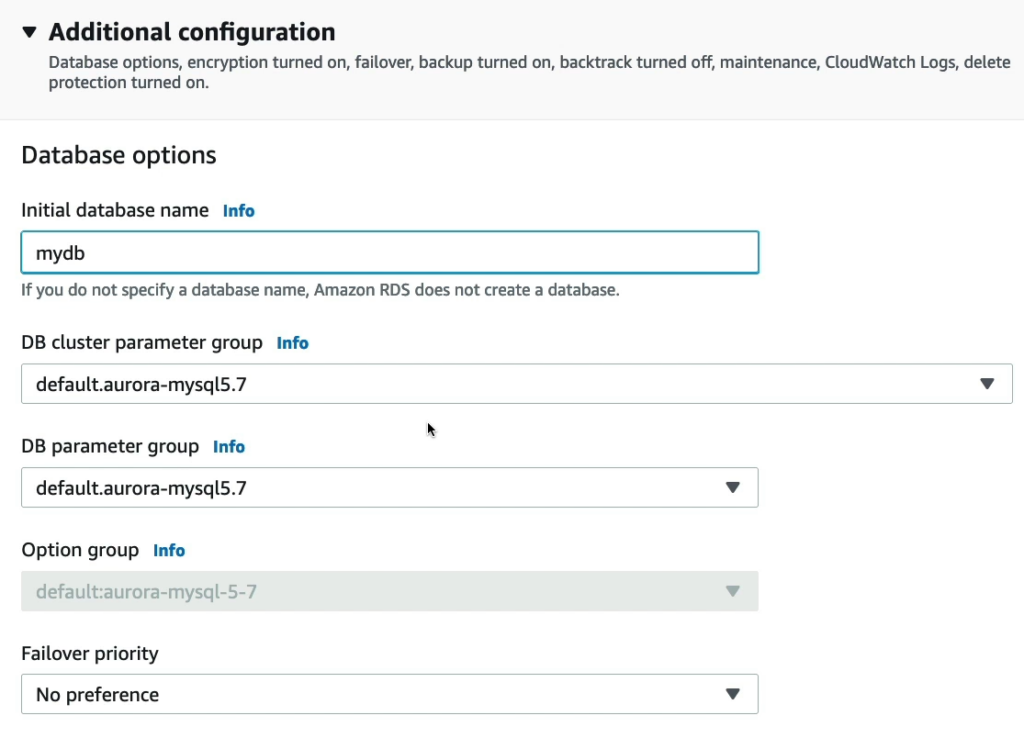
Mình sẽ khởi tạo 1 database tên mydb.
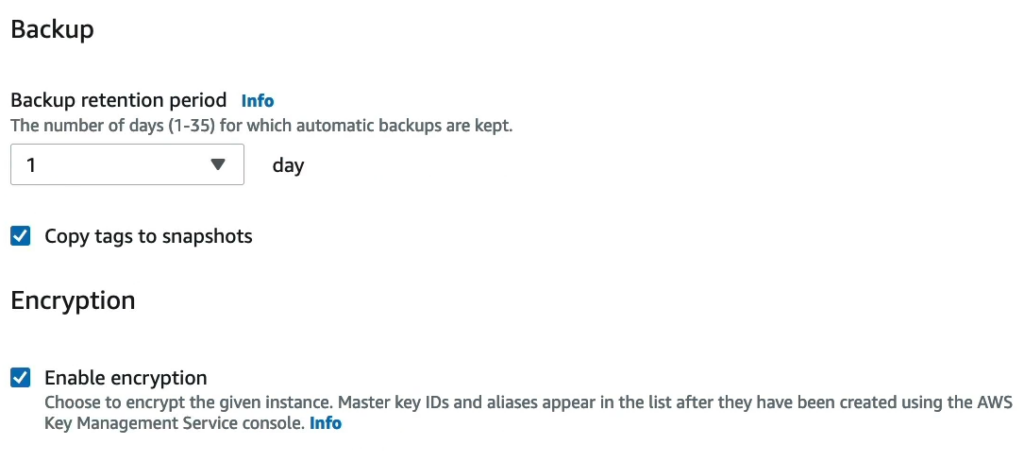
Phần backup bạn không thể tắt và tại đây bạn có thể lựa chọn mã hoá dữ liệu.
Backtrack cho phép người dùng phục hồi dữ liệu tại bất kỳ điểm nào trong quá khứ mà không cần phải sử dụng các bản sao lưu, giúp tiết kiệm thời gian và tài nguyên.
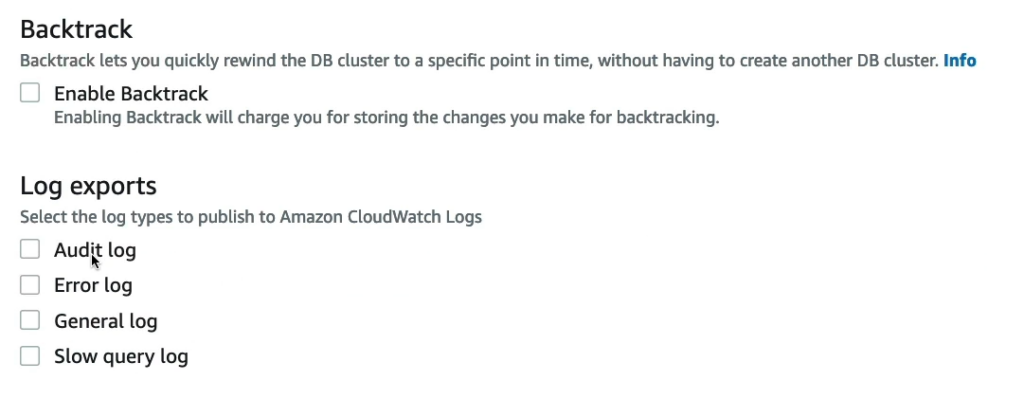
Phần Maintenance ở bài trước mình có giải thích kỹ, bạn có thể xem lại nhé (bấm vào đây để xem lại). Nếu không có gì thay đổi, bấm Create database để tạo database.
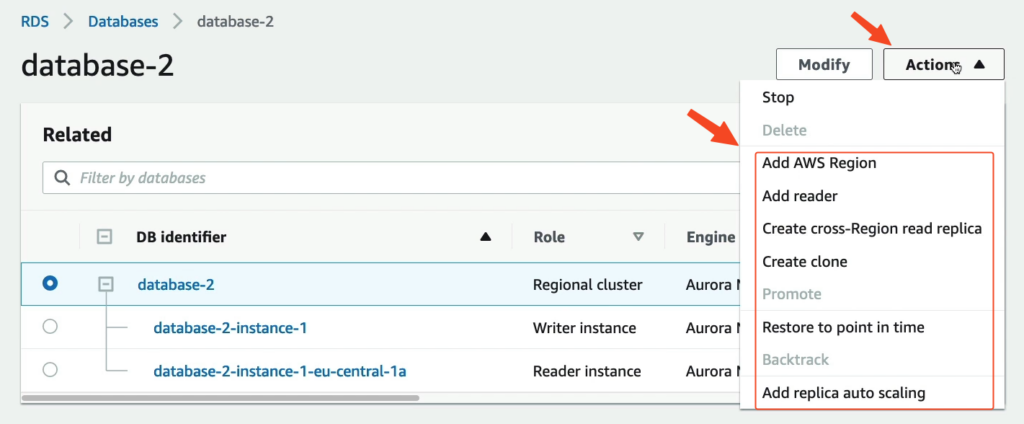
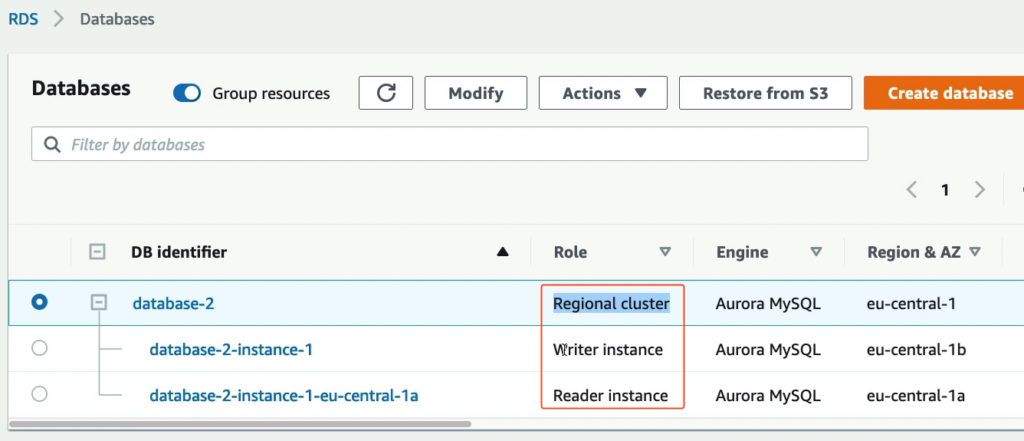
Sau khi khởi tạo bạn có thể thấy AWS thể hiện có 1 Regional cluster, Writer instance và 1 Reader instance và quan trọng ở đây là các thành phần nằm rải rác ở các AZ khác nhau.
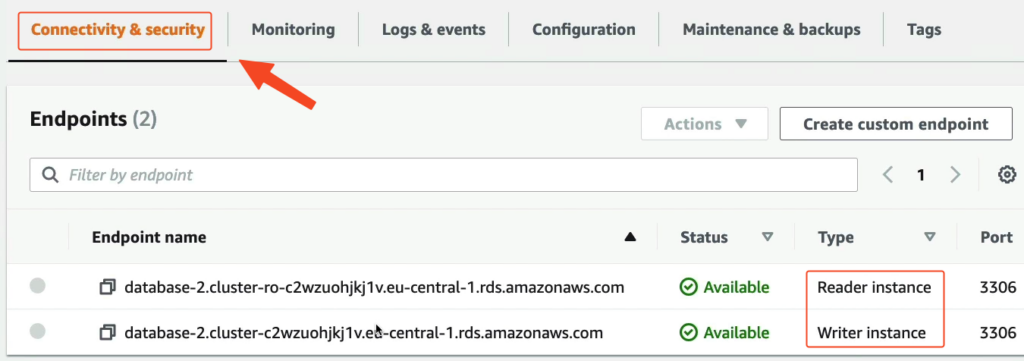
Bạn có thể nhận thấy chúng ta sẽ có 2 Endpoint đó là Endpoint chỉ đọc và Endpoint chỉ ghi.
Nhưng nếu trường hợp bạn bấm trực tiếp vào 1 EC2 nào đó.
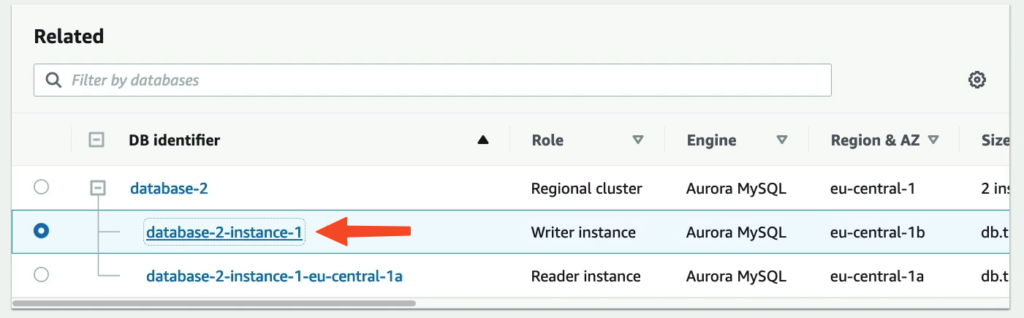
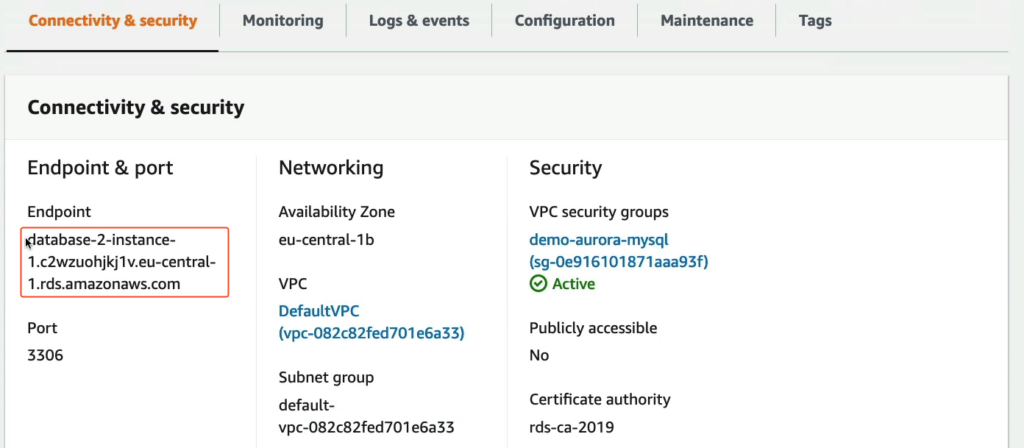
Thì nó cũng có 1 Endpoint chuyên dụng riêng.
Và nếu chúng ta bấm vào Action, chúng ta sẽ thấy có rất nhiều tính năng nữa.