DynamoDB Accelerator (DAX)
Dịch vụ “Fully-managed, highly available, seamless inmemory cache for DynamoDB” là một dịch vụ quản lý bộ nhớ đệm cho DynamoDB, hoạt động trên nền tảng AWS (Amazon Web Services). Dịch vụ này giúp giải quyết vấn đề tắc nghẽn khi đọc dữ liệu trên DynamoDB bằng cách lưu trữ các dữ liệu phổ biến vào bộ nhớ đệm. Khi có yêu cầu đọc dữ liệu, hệ thống sẽ truy vấn bộ nhớ đệm trước để lấy dữ liệu, giảm thiểu số lượng truy vấn đọc vào DynamoDB, giảm thiểu thời gian truy vấn và tăng hiệu suất cho các ứng dụng đọc dữ liệu từ DynamoDB.
Bộ nhớ đệm cho DynamoDB sử dụng công nghệ inmemory cache, giúp tăng tốc độ truy vấn và thời gian phản hồi. Thời gian đọc dữ liệu từ bộ nhớ đệm chỉ mất vài micro giây, so với đọc từ DynamoDB mất vài mili giây.
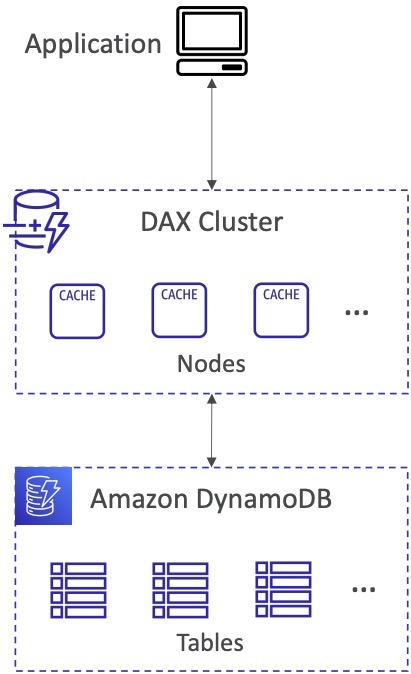
Dịch vụ này không yêu cầu sửa đổi logic ứng dụng, có thể sử dụng được với các API hiện có của DynamoDB. Ngoài ra, bộ nhớ đệm này còn có tính năng tự động cập nhật dữ liệu, giúp đồng bộ hóa dữ liệu mới nhất từ DynamoDB vào bộ nhớ đệm.
Mặc định, thời gian sống của các dữ liệu lưu trữ trong bộ nhớ đệm là 5 phút (TTL – Time To Live). Nếu dữ liệu không được truy vấn trong khoảng thời gian này, nó sẽ tự động bị xóa khỏi bộ nhớ đệm để giải phóng tài nguyên và tránh lãng phí bộ nhớ. Tuy nhiên, TTL có thể được cấu hình lại để phù hợp với yêu cầu của ứng dụng.
DynamoDB Accelerator (DAX) vs. ElastiCache
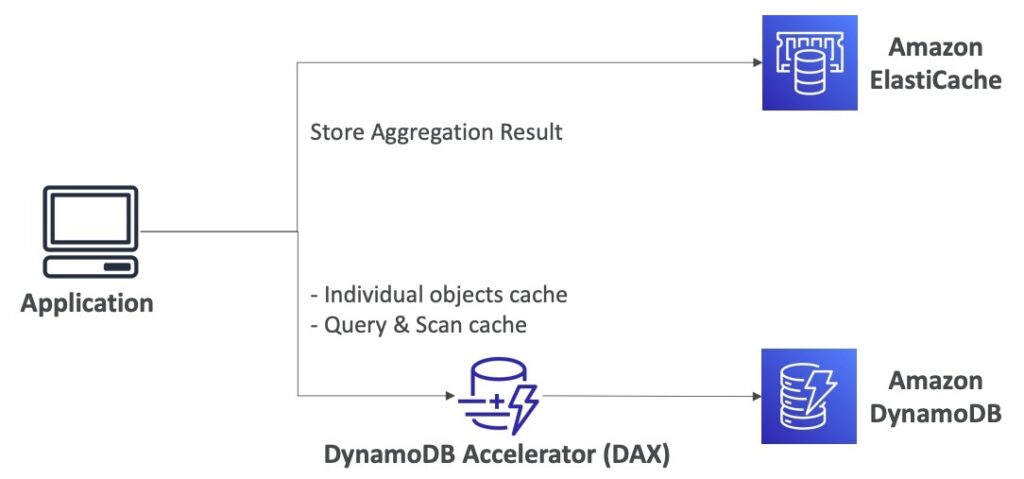
Amazon ElastiCache và Amazon DynamoDB Accelerator (DAX) là những dịch vụ của Amazon Web Services (AWS) được thiết kế để giải quyết vấn đề về hiệu suất và tăng tốc độ truy vấn trên DynamoDB.
Amazon ElastiCache là một dịch vụ quản lý bộ nhớ đệm (cache) trên AWS, cho phép lưu trữ tạm thời dữ liệu tính toán hoặc kết quả truy vấn, từ các ứng dụng như DynamoDB, RDS hoặc Redshift. Khi ứng dụng truy vấn dữ liệu, bộ nhớ đệm ElastiCache sẽ kiểm tra xem dữ liệu đã được lưu trữ trước đó hay chưa. Nếu có, nó sẽ lấy dữ liệu từ bộ nhớ đệm thay vì truy vấn dữ liệu từ nguồn gốc, giúp tăng tốc độ truy vấn và giảm tải cho cơ sở dữ liệu.
Amazon DynamoDB Accelerator (DAX) là một dịch vụ cache được tích hợp sẵn trên DynamoDB. Nó cung cấp các tính năng cache cho các truy vấn và scan, giúp tăng tốc độ truy vấn và giảm tải cho DynamoDB. Với DAX, các kết quả truy vấn sẽ được lưu trữ trong cache, giảm thiểu số lượng truy vấn vào DynamoDB. DAX còn hỗ trợ cache cho các đối tượng riêng lẻ, giúp giảm tải cho các truy vấn đọc, giúp tăng hiệu suất cho các ứng dụng truy vấn dữ liệu từ DynamoDB.
Cả ElastiCache và DAX đều giúp giảm thiểu số lượng truy vấn vào DynamoDB, giúp tăng hiệu suất và giảm tải cho cơ sở dữ liệu. Tuy nhiên, điều quan trọng là phải cân nhắc kích thước bộ nhớ đệm và kích thước cụm để đảm bảo tính khả dụng và khả năng mở rộng của hệ thống.
DynamoDB – Stream Processing
DynamoDB Streams và Kinesis Data Streams là hai dịch vụ của Amazon Web Services (AWS) được thiết kế để xử lý và xem xét các sự thay đổi dữ liệu trên DynamoDB.
DynamoDB Streams là một luồng sự kiện được sắp xếp theo thứ tự của các thay đổi tại mức độ mục, bao gồm các sự kiện tạo, cập nhật và xóa. Nó cho phép các ứng dụng xử lý các sự kiện này và phản hồi trong thời gian thực, chẳng hạn như gửi email chào mừng đến người dùng mới đăng ký hoặc thống kê sử dụng thời gian thực. Các ứng dụng cũng có thể sử dụng DynamoDB Streams để thêm hoặc cập nhật các bảng phụ hoặc triển khai sao chép đến các khu vực khác. DynamoDB Streams có thể được xử lý bằng cách sử dụng AWS Lambda Triggers hoặc DynamoDB Stream Kinesis adapter. DynamoDB Streams giữ lại sự kiện trong vòng 24 giờ và hỗ trợ một số lượng giới hạn người tiêu thụ.
Kinesis Data Streams là một dịch vụ xử lý dữ liệu phân tán được cung cấp bởi AWS, cho phép người dùng xử lý và phân tích luồng dữ liệu lớn từ nhiều nguồn khác nhau trong thời gian thực. Kinesis Data Streams có thể được sử dụng để xử lý và phản hồi các sự kiện được tạo ra bởi DynamoDB Streams hoặc các nguồn khác nhau. Nó giữ lại dữ liệu trong vòng 1 năm và hỗ trợ một số lượng lớn người tiêu thụ. Các ứng dụng có thể xử lý dữ liệu từ Kinesis Data Streams bằng cách sử dụng các dịch vụ như AWS Lambda, Kinesis Data Analytics, Kinesis Data Firehose hoặc AWS Glue Streaming ETL.
Tổng quan, DynamoDB Streams và Kinesis Data Streams đều cho phép xử lý và phản hồi các sự kiện dữ liệu trong thời gian thực, nhưng có sự khác biệt về khả năng lưu trữ dữ liệu, số lượng người tiêu thụ và các dịch vụ xử lý dữ liệu được hỗ trợ.
DynamoDB Streams
Trong kiến trúc của Amazon DynamoDB, sử dụng DynamoDB Streams và Kinesis Data Streams để ghi lại các thay đổi của các mục trong bảng DynamoDB. Điều này cho phép các ứng dụng lắng nghe và xử lý các thay đổi này để thực hiện các hoạt động như thông báo, phân tích và lưu trữ dữ liệu.
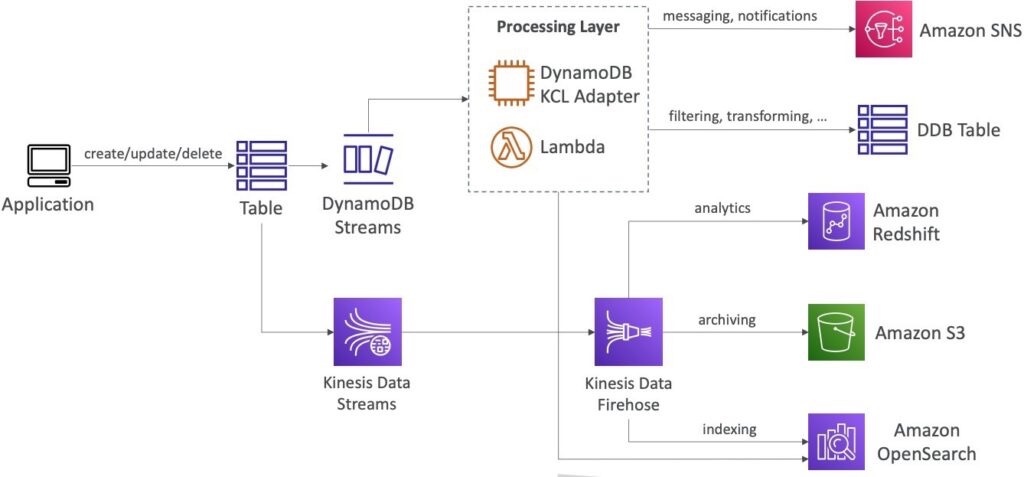
Trong trường hợp sử dụng DynamoDB Streams, các thay đổi được lưu trữ trong 24 giờ và giới hạn số lượng người tiêu dùng. Các thay đổi có thể được xử lý bằng cách sử dụng các AWS Lambda Triggers hoặc DynamoDB Stream Kinesis adapter. Các thay đổi này có thể được chuyển tiếp đến các hệ thống khác, chẳng hạn như Amazon OpenSearch, thông qua lớp xử lý (processing layer) bao gồm DynamoDB KCL Adapter và Lambda.
Cũng tương tự như DynamoDB Streams, trong trường hợp sử dụng Kinesis Data Streams, các thay đổi được lưu trữ trong 1 năm và hỗ trợ số lượng người tiêu dùng cao hơn. Các thay đổi này được xử lý bằng cách sử dụng các dịch vụ như AWS Lambda, Kinesis Data Analytics, Kinesis Data Firehose và AWS Glue Streaming ETL. Dữ liệu được xử lý và lưu trữ trong các hệ thống khác như Amazon Redshift để phân tích hoặc Amazon S3 để lưu trữ dữ liệu lâu dài. Ngoài ra, các dữ liệu có thể được tìm kiếm và truy vấn thông qua Amazon OpenSearch.
Thông qua việc sử dụng Amazon SNS và DynamoDB Table, các thông báo và tin nhắn có thể được gửi tới các người dùng hoặc hệ thống khác để xử lý. Các bảng DynamoDB có thể được sử dụng để lọc và biến đổi dữ liệu trước khi gửi tới các hệ thống khác.
DynamoDB Global Tables
DynamoDB là một dịch vụ cơ sở dữ liệu NoSQL do Amazon cung cấp. Để làm cho bảng DynamoDB truy cập được với độ trễ thấp ở nhiều khu vực và cho phép đọc và ghi từ ứng dụng trong bất kỳ khu vực nào, ta có thể triển khai một kiến trúc sao chép hoạt động hoạt động (Active-Active replication) với DynamoDB.
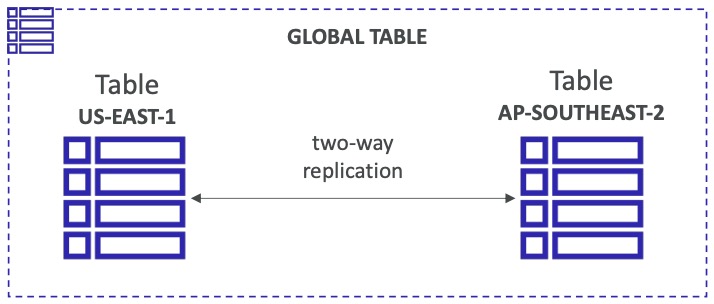
Để triển khai kiến trúc này, trước tiên ta cần bật DynamoDB Streams, đây là một tính năng của DynamoDB cho phép ta theo dõi các sự kiện thay đổi dữ liệu trên bảng. Các sự kiện này có thể được sử dụng để sao chép dữ liệu giữa các bảng DynamoDB khác nhau.
Tiếp theo, ta có thể sử dụng Kinesis Data Streams để sao chép dữ liệu giữa các bảng DynamoDB khác nhau trong các khu vực khác nhau. Kinesis Data Streams là một dịch vụ của AWS cho phép ta lưu trữ và xử lý dữ liệu dòng liên tục trong thời gian thực.
Để cho phép ứng dụng đọc và ghi vào bảng DynamoDB trong bất kỳ khu vực nào, ta có thể sử dụng một giải pháp Route 53 với tính năng định tuyến dựa trên vị trí (Geolocation Routing). Với tính năng này, Route 53 có thể định tuyến các yêu cầu đến bảng DynamoDB gần nhất với người dùng.
Với kiến trúc này, ta có thể triển khai một bảng DynamoDB truy cập được với độ trễ thấp ở nhiều khu vực và cho phép đọc và ghi từ ứng dụng trong bất kỳ khu vực nào.
DynamoDB –Time To Live (TTL)

Tự động xóa các mục sau khi đạt đến thời gian hết hạn là một phương pháp để giảm thiểu dữ liệu được lưu trữ bằng cách chỉ giữ lại các mục hiện tại và loại bỏ các mục đã hết hạn. Điều này có thể được sử dụng trong nhiều trường hợp khác nhau, bao gồm:
- Quản lý phiên web: Khi người dùng truy cập vào một trang web, một phiên được bắt đầu và thông tin phiên được lưu trữ trong cơ sở dữ liệu. Tuy nhiên, để tránh quá tải cơ sở dữ liệu, các phiên đã kết thúc hoặc hết hạn sẽ được tự động xóa khỏi cơ sở dữ liệu.
- Đáp ứng các nghĩa vụ quy định: Trong một số trường hợp, các quy định hoặc luật pháp yêu cầu các tổ chức phải xóa các thông tin cá nhân của người dùng sau một thời gian nhất định. Việc tự động xóa các mục sau khi hết hạn sẽ giúp các tổ chức này tuân thủ các quy định này một cách hiệu quả.
- Giảm thiểu dữ liệu được lưu trữ: Tự động xóa các mục sau khi hết hạn cũng là một phương pháp để giảm thiểu lượng dữ liệu được lưu trữ trong cơ sở dữ liệu của một tổ chức. Việc giữ lại chỉ các mục hiện tại sẽ giúp tối ưu hóa việc quản lý và truy xuất dữ liệu của tổ chức.
DynamoDB – Backups for disaster recovery
Sao lưu liên tục sử dụng phục hồi điểm thời gian (PITR) là một cách để đảm bảo rằng dữ liệu của bạn được sao lưu đầy đủ và có thể được khôi phục lại vào bất kỳ thời điểm nào trong khoảng thời gian đã sao lưu. Khi được kích hoạt, phục hồi điểm thời gian có thể được sử dụng cho các bản sao lưu trong vòng 35 ngày gần đây nhất. Quá trình phục hồi tạo ra một bảng mới để chứa dữ liệu được khôi phục.
Bạn cũng có thể thực hiện sao lưu theo yêu cầu để lưu trữ dữ liệu tạm thời, hoặc sao lưu đầy đủ để giữ lại dữ liệu lâu dài cho đến khi được xóa. Quá trình sao lưu này không ảnh hưởng đến hiệu suất hoặc độ trễ của hệ thống.
Các tính năng này có thể được cấu hình và quản lý trong AWS Backup, cho phép bạn sao chép dữ liệu giữa các khu vực khác nhau. Quá trình phục hồi tạo ra một bảng mới để khôi phục dữ liệu và bảo đảm rằng dữ liệu gốc không bị thay đổi trong quá trình khôi phục.
Tóm lại, PITR là một phương pháp sao lưu dữ liệu liên tục, cho phép khôi phục dữ liệu tại bất kỳ thời điểm nào trong khoảng thời gian đã sao lưu. Nó không ảnh hưởng đến hiệu suất hoặc độ trễ của hệ thống và có thể được quản lý bằng AWS Backup để đảm bảo tính khả dụng và độ tin cậy của dữ liệu của bạn.
DynamoDB – Integration with Amazon S3
• Export to S3 (must enable PITR)
Export to S3 là tính năng cho phép bạn xuất dữ liệu từ DynamoDB vào S3 để thực hiện các phân tích dữ liệu hoặc lưu trữ cho mục đích kiểm toán. Tính năng này yêu cầu phải kích hoạt PITR và cho phép bạn lấy bất kỳ dữ liệu nào trong khoảng 35 ngày gần đây nhất.
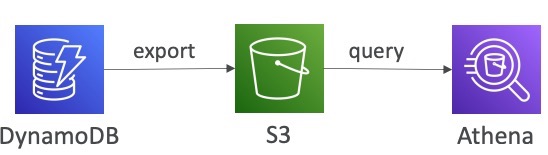
Khi xuất dữ liệu, tính năng này không ảnh hưởng đến khả năng đọc của bảng của bạn. Sau đó, bạn có thể thực hiện phân tích dữ liệu trên S3 và lưu trữ snapshot của dữ liệu này cho mục đích kiểm toán.
• Import to S3
Bạn cũng có thể thực hiện ETL (Extract, Transform, Load) trên dữ liệu trên S3 trước khi nhập lại vào DynamoDB. Dữ liệu có thể được xuất ở định dạng JSON hoặc ION và được nhập lại vào DynamoDB ở định dạng CSV, JSON hoặc ION. Quá trình nhập sẽ không tiêu tốn bất kỳ khả năng ghi nào và sẽ tạo ra một bảng mới để lưu trữ dữ liệu. Nếu có bất kỳ lỗi nào xảy ra trong quá trình nhập, chúng sẽ được ghi lại trong CloudWatch Logs để bạn có thể xem lại và sửa chữa.

Tóm lại, tính năng Export to S3 cho phép bạn xuất dữ liệu từ DynamoDB vào S3 để thực hiện phân tích dữ liệu hoặc lưu trữ cho mục đích kiểm toán. Bạn có thể thực hiện ETL trên dữ liệu trên S3 trước khi nhập lại vào DynamoDB và quá trình nhập sẽ không tiêu tốn bất kỳ khả năng ghi nào. Quá trình nhập sẽ tạo ra một bảng mới để lưu trữ dữ liệu và các lỗi nhập sẽ được ghi lại trong CloudWatch Logs để bạn có thể xem lại và sửa chữa.
