1. Dynamic Scaling Policies là gì?
Dynamic Scaling Policies trong Auto Scaling Groups (ASG) là các chính sách tự động điều chỉnh kích thước của ASG dựa trên các ngưỡng mức yêu cầu về tài nguyên. Các chính sách này được thiết lập để đáp ứng các yêu cầu về tải của hệ thống mà ASG đang phục vụ.
Các chính sách này hoạt động bằng cách đưa ra các quyết định tự động để thêm hoặc giảm số lượng các EC2 instances vào trong ASG, giúp đáp ứng yêu cầu về tải. Chính sách này sử dụng các thông số cấu hình như các ngưỡng cho phép CPU sử dụng, bộ nhớ, số lượng yêu cầu đang xử lý và thời gian đáp ứng để quyết định cần thêm hoặc giảm bao nhiêu EC2 instances.
Dynamic Scaling Policies giúp đảm bảo rằng hệ thống của bạn luôn có đủ tài nguyên để đáp ứng yêu cầu của người dùng mà không bị quá tải hoặc lãng phí tài nguyên.
2. Các tính năng.
– Target Tracking Scaling.
Trong Auto Scaling Group, “Target Tracking Scaling” là một loại chính sách động để tự động điều chỉnh số lượng instances trên ASG để đạt được một mục tiêu hiệu suất xác định. Với chính sách Target Tracking Scaling, bạn chỉ cần đặt một mục tiêu về giá trị của một chỉ số hiệu suất (ví dụ: tỷ lệ sử dụng CPU trung bình) và hệ thống sẽ tự động tăng hoặc giảm số lượng instances để giữ cho chỉ số hiệu suất ở mức giá trị đó.
Ví dụ, nếu bạn muốn đảm bảo rằng tỷ lệ sử dụng CPU trung bình của tất cả các instances trong ASG không vượt quá 40%, bạn có thể sử dụng chính sách Target Tracking Scaling để tự động tăng hoặc giảm số lượng instances dựa trên giá trị của chỉ số này. Khi giá trị chỉ số vượt quá mức 40%, hệ thống sẽ tự động tăng số lượng instances để giảm tải và giữ cho chỉ số ở mức giá trị mong muốn, và khi giá trị chỉ số giảm xuống, hệ thống sẽ tự động giảm số lượng instances để tiết kiệm chi phí.
– Simple / Step Scaling.
- Simple scaling là một loại policy trong AWS Auto Scaling, cho phép người dùng đơn giản hóa việc tự động scale up hoặc scale down số lượng instances dựa trên một chỉ số đơn giản, chẳng hạn như CPU usage, network traffic, hay số lượng request đang được xử lý. Khi giá trị của chỉ số đạt tới một ngưỡng được xác định trước, policy sẽ thực hiện hành động scale up hoặc scale down dựa trên cấu hình được định sẵn. Simple scaling được sử dụng để xử lý các tình huống đơn giản mà không cần đến sự phân tích phức tạp của các policy khác.
- Step Scaling: Tự động tăng hoặc giảm số lượng EC2 instances trong Auto Scaling group dựa trên các bước điều chỉnh định sẵn (ví dụ tăng 2 instances nếu CPU utilization vượt quá 70%, giảm 1 instance nếu CPU utilization thấp hơn 30%).
– Scheduled Actions.
Scheduled Actions là một loại chính sách tăng giảm tự động trong AWS Auto Scaling cho phép bạn thiết lập các hành động tăng giảm tự động sẽ xảy ra vào các thời điểm cụ thể trong tương lai. Loại chính sách này có thể hữu ích khi bạn dự đoán sự thay đổi trong các mô hình lưu lượng của ứng dụng của mình, chẳng hạn như tăng lưu lượng trong một sự kiện khuyến mãi hoặc thời kỳ bán hàng mùa.
Ví dụ, bạn có thể tạo một scheduled action để tăng dung lượng tối thiểu của nhóm Auto Scaling lên 10 phiên bản vào mỗi thứ sáu lúc 5 giờ chiều để chuẩn bị cho một sự kiện lưu lượng cao. Như vậy, các phiên bản thêm vào sẽ được chạy đúng lúc để đáp ứng với lượng truy cập tăng lên trong thời điểm đó.
– Predictive scaling.
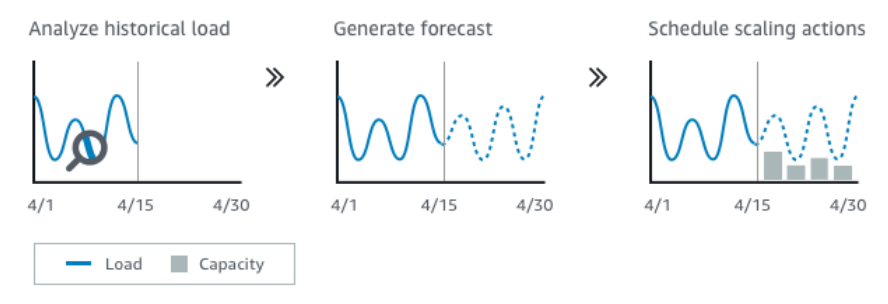
Predictive scaling là tính năng trong Auto Scaling Group cho phép dự đoán tải trước và lên lịch tự động scale-up hoặc scale-down tùy thuộc vào tải dự đoán. Để sử dụng tính năng này, AWS sẽ thu thập dữ liệu về các yếu tố ảnh hưởng đến tải như thời tiết, sự kiện, xu hướng, … sau đó phân tích để đưa ra dự đoán về tải cho những phút, giờ hoặc ngày tiếp theo. Khi tải dự đoán cao, Auto Scaling Group sẽ tự động scale-up, tăng số lượng instances để đáp ứng tải mà không gây trễ, chậm hoặc downtime cho ứng dụng. Tính năng này có thể giúp cho việc quản lý tài nguyên và chi phí hiệu quả hơn, đảm bảo cho ứng dụng luôn được sẵn sàng hoạt động một cách ổn định và linh hoạt.
3. Một số số liệu tốt để scale hệ thống.
- CPUUtilization: là độ sử dụng CPU trung bình trên các instances của Auto Scaling Group. Đây là một metrics thường được sử dụng để mở rộng và thu nhỏ kích thước của nhóm.
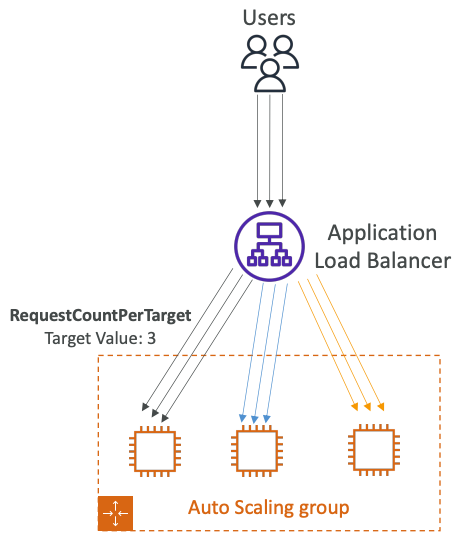
- RequestCountPerTarget: đo lường số lượng yêu cầu đang được xử lý bởi từng instance trong nhóm, để đảm bảo số lượng yêu cầu của từng instance ổn định.
- Average Network In / Out: đo lường lưu lượng mạng trung bình đến và từ các instance trong nhóm. Nếu ứng dụng của bạn chịu tải nặng về mặt mạng, thì đây là một metrics hữu ích để mở rộng kích thước nhóm.
- Custom metric: là một metrics tùy chỉnh mà bạn có thể tự định nghĩa và gửi dữ liệu đến CloudWatch. Những metrics này có thể đo lường bất kỳ thành phần nào trong ứng dụng của bạn mà bạn muốn mở rộng hoặc thu nhỏ kích thước nhóm.
4. Auto Scaling Groups – Scaling Cooldowns là gì?
Sau khi thực hiện một hoạt động tự động điều chỉnh tỉ lệ tự động trong Auto Scaling Group, hệ thống sẽ vào giai đoạn cooldown trong một khoảng thời gian mặc định là 300 giây (5 phút). Trong giai đoạn này, hệ thống sẽ không tạo thêm hoặc xóa bất kỳ máy chủ nào khác trong Auto Scaling Group, nhằm cho phép các thông số đo lường ổn định trước khi thực hiện những tác động tiếp theo.
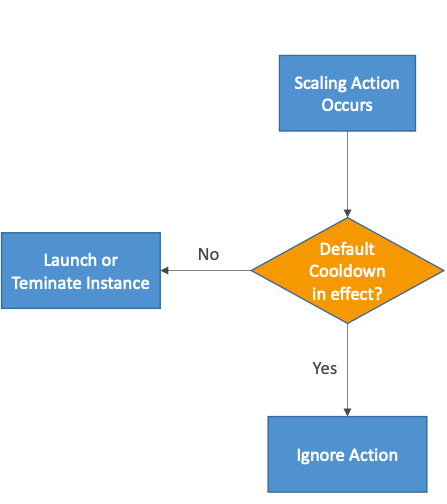
Trong thời gian cooldown, Auto Scaling Group (ASG) sẽ không khởi chạy thêm hoặc huỷ bỏ các instances (thực hiện scale out hoặc scale in) để cho các metrics ổn định. Điều này đảm bảo rằng hệ thống đã ổn định trước khi ASG tiếp tục thực hiện các hoạt động tự động tiếp theo, giúp tránh các thay đổi không mong muốn và hệ thống hoạt động một cách ổn định.
Tại thời điểm khởi tạo một EC2 instance mới, bạn cần phải cấu hình một AMI (Amazon Machine Image) để xác định hệ điều hành, phần mềm và cấu hình của EC2 instance đó. Việc tạo một AMI tùy chỉnh từ đầu có thể mất nhiều thời gian và công sức. Vì vậy, tốt hơn là sử dụng một AMI sẵn có đã được chuẩn bị trước đó để tạo instance mới. Khi sử dụng AMI sẵn có, bạn có thể tạo các instance nhanh hơn và giảm thiểu thời gian cần thiết để cấu hình chúng, điều này sẽ giúp cho bạn phục vụ các yêu cầu nhanh hơn và giảm thiểu thời gian cooldown.
5. Thực hành.
Như các bạn thấy, chúng ta có 3 tính năng Dynamic Scaling Policies đó là Dynamic scaling policies, Predictive scaling policies và Scheduled actions.
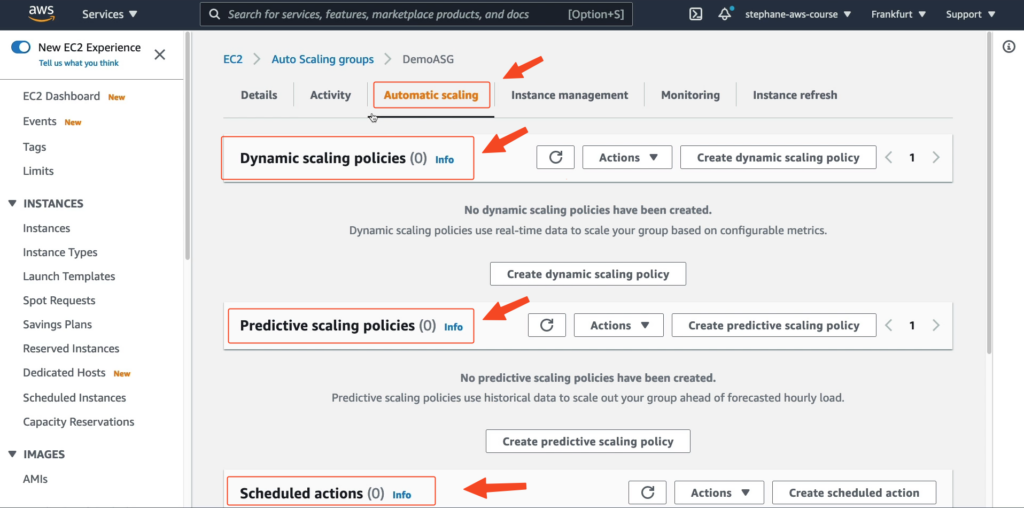
– Scheduled actions.
Hãy bấm vào Create scheduled action để tạo 1 scheduled action.

Tại phần name bạn có thể đặt tên cho nó. Trong các Scheduled Action của Auto Scaling, bạn phải cung cấp ít nhất một giá trị cho Desired, Min hoặc Max Capacity.
- Desired Capacity là số lượng máy ảo mong muốn sẽ chạy tại bất kỳ thời điểm nào.
- Min Capacity là số lượng máy ảo tối thiểu cần phải chạy bất kỳ lúc nào để đảm bảo hiệu suất và khả năng sẵn sàng.
- Max Capacity là số lượng máy ảo tối đa mà bạn cho phép trong một nhóm tự động.
Khi bạn lập lịch cho một hoạt động, bạn cần cung cấp giá trị cho một trong số các tham số này để Auto Scaling biết mục tiêu của bạn cho việc tăng giảm quy mô. Nếu bạn không cung cấp bất kỳ giá trị nào cho các tham số này, Scheduled Action sẽ không thực hiện bất kỳ thay đổi quy mô nào.
Recurrence được sử dụng để lên lịch cho các hành động được thực hiện định kỳ theo thời gian. Nó cho phép bạn cấu hình các hành động để thực hiện vào các ngày, tuần, tháng cụ thể, tại một thời điểm nhất định hoặc tần suất nhất định. Ví dụ, bạn có thể lên lịch cho việc tắt các EC2 instances vào cuối tuần hoặc thực hiện việc sao lưu vào mỗi đầu ngày. Recurrence giúp tối ưu hóa việc quản lý tài nguyên và tự động hóa các tác vụ định kỳ trong môi trường đám mây AWS.
Tùy chọn “Specific start time” trong các Scheduled Action của Amazon EC2 Auto Scaling cho phép bạn chỉ định một thời điểm cụ thể để bắt đầu thực hiện hoạt động tự động. Điều này giúp bạn dễ dàng lên kế hoạch cho các hoạt động quy mô trước đó, chẳng hạn như khởi động lại các instance vào thời điểm không bận rộn để giảm thiểu ảnh hưởng đến người dùng hoặc chuyển đổi sang các instance mới vào giờ cao điểm để đảm bảo hiệu suất và sẵn sàng cao nhất.

– Predictive scaling policies
“Scale based on forecast” là tính năng của AWS Auto Scaling giúp tự động điều chỉnh dung lượng EC2 instance một cách dựa trên dự báo nhu cầu tài nguyên trong tương lai. Nếu tính năng này bị tắt, AWS Auto Scaling chỉ tính toán và dự báo nhu cầu tài nguyên mà không thực hiện bất kỳ hành động điều chỉnh dung lượng nào. Chỉ có một predictive scaling policy được phép bật tính năng này một lúc.
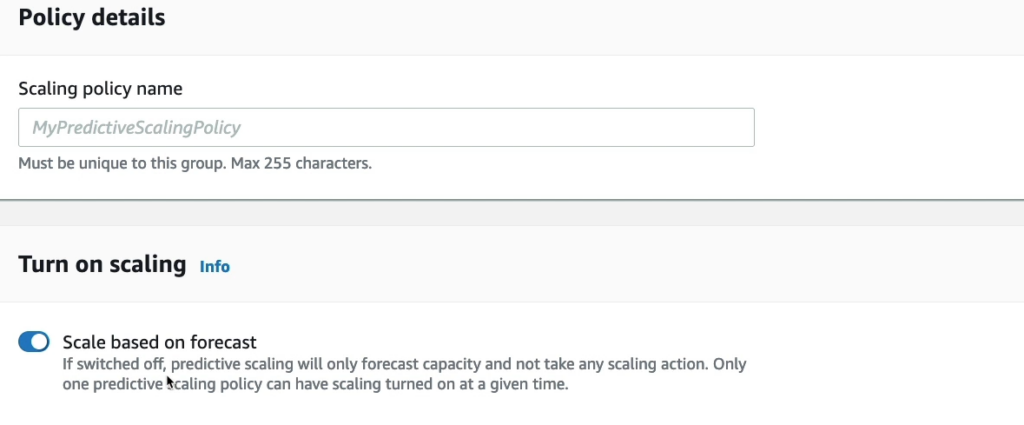
Nếu bật Scale based on forecast thì nó sẽ xem xét 1 số yếu tố để scale do mình chỉ định như dưới đây.
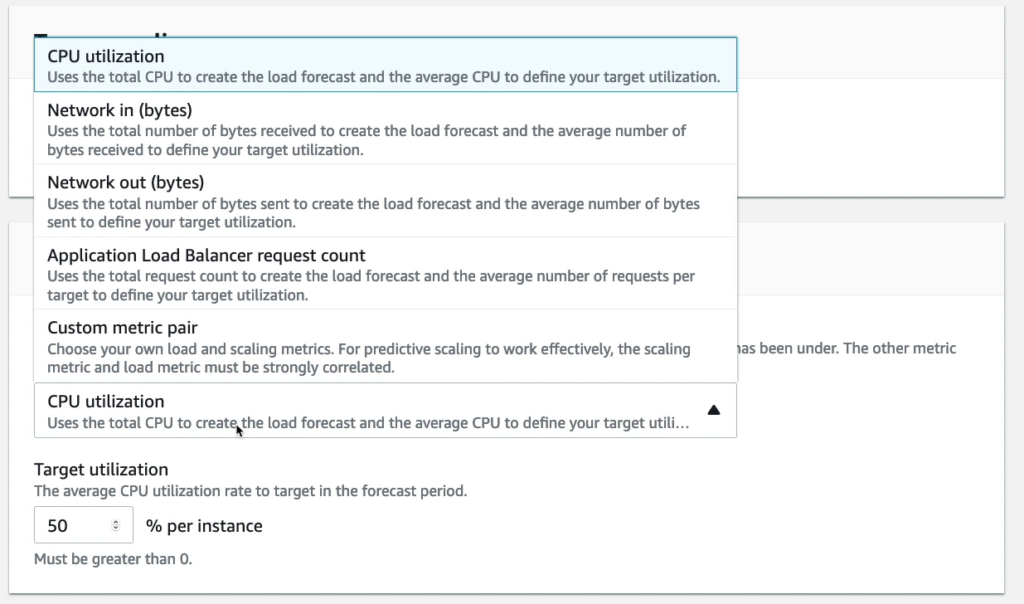
Ví dụ mình setup 50% ở phần Target utilization tức là khi CPU bị vượt ngưỡng 50% nó sẽ tạo ra thêm instance để cân bằng lại 50% mức sử dụng CPU.
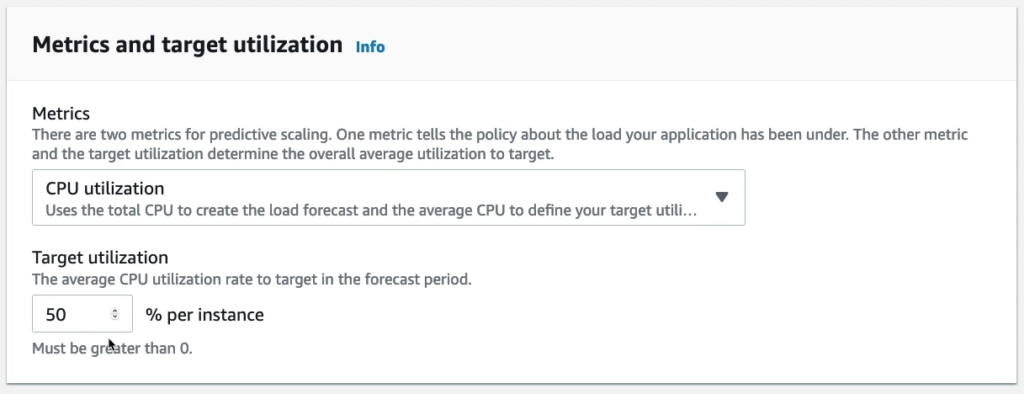
Tiếp theo là một số thành phần bổ sung, mình sẽ không thay đổi nó.
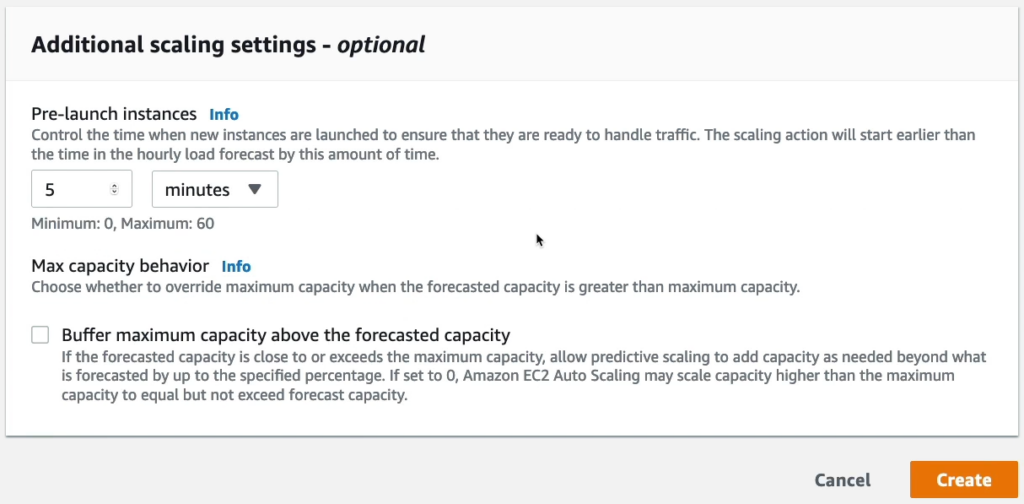
– Dynamic scaling policies.
Phần này mình sẽ demo chính sách theo dõi mục tiêu Target tracking scaling, cụ thể là CPU.
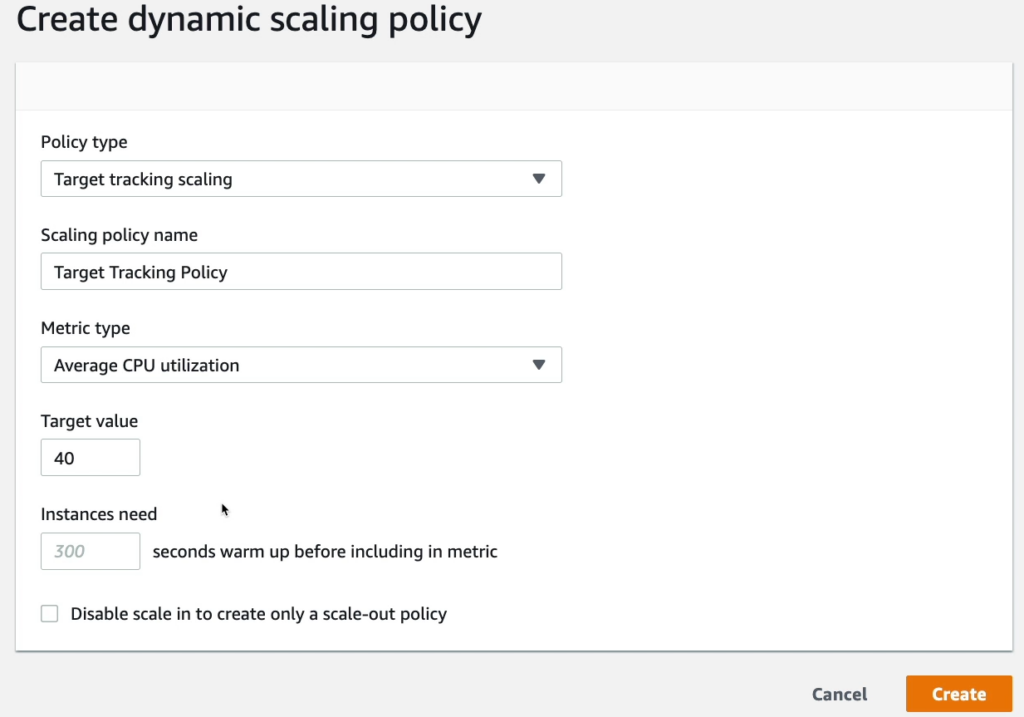
Múc tiêu của ASG này là duy trì mức sử dụng CPU đến 40%.
Để thấy điều này trong thực tế, ta cần thay đổi 1 số thông số như sau. Bấm Edit.
Mình sẽ thay đổi Maximum capacity tối đa là 3.

Tại mục Auto Scaling mọi thứ chưa có gì, do Instance của mình mới tạo.
Chuyển sang tab EC2 cho thấy mức sử dụng resource cũng rất thấp.
Bây giờ hãy thử làm gì đó để đẩy mức sử dụng của instance i-0ee471418a3053191 CPU lên quá 40% để chúng ta có kết quả.
Hãy bấm vào Connect để kết nối console vào instance này.
Bấm vào connect.
Sau khi kết nối được vào instance, bạn có thể cài đặt stress để đẩy mức resource.
sudo amazon-linux-extras install epel -y
sudo yum install stress -yHãy chạy lệnh dưới để đẩy CPU tăng lên 100%
[ec2-user@ip-172-31-6-35 -]$ stress -c 4
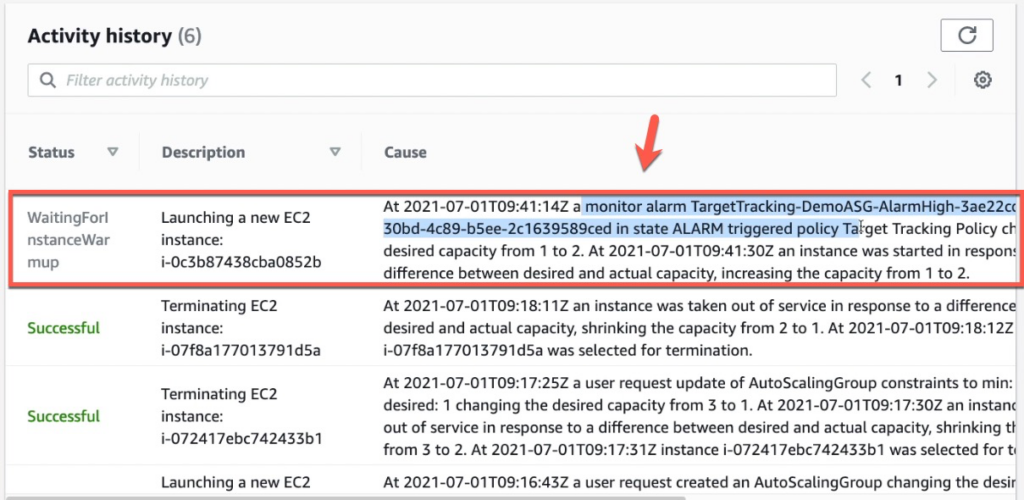
stress: info: [3920] dispatching hogs: 4 cpu, 0 io, 0 vm, 0 hddHãy vào lại Activity history chúng ta thấy có 1 báo động đã được kích hoạt.
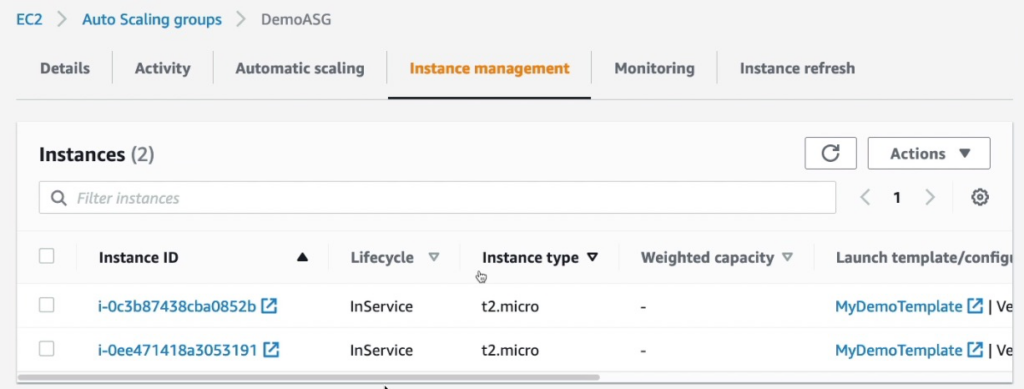
Hãy vào Instance management chúng ta đã thấy có 2 instance đang chạy.
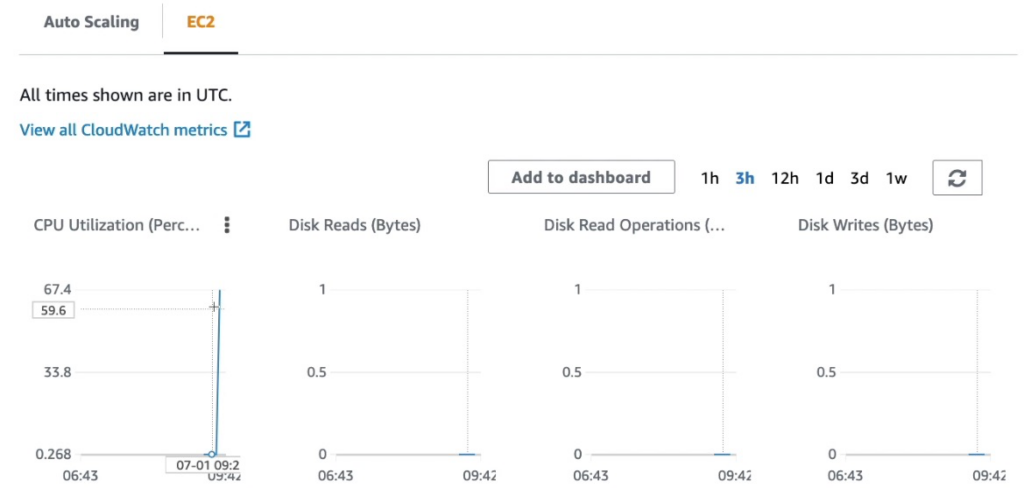
Quay lại tab monitor chúng ta có thể thấy rằng CPU đang hoạt động ở mức rất cao.
Hãy vào cloudwatch.

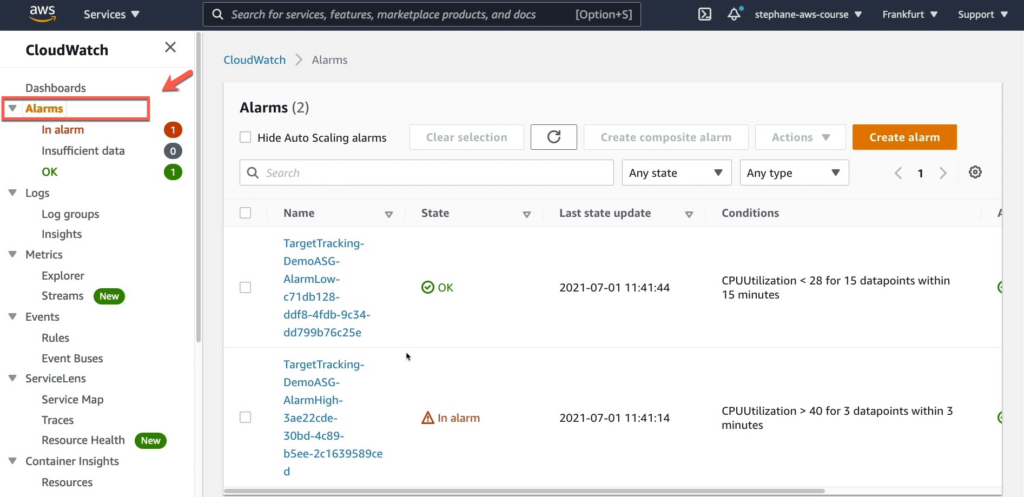
Vào tab Alams bạn có thể thấy có 2 trigger đã được tạo bởi chính sách theo dõi mục tiêu.
- Chúng ta có 1 trigger tên là TargetTracking-DemoASG-AlarmHigh-3ae22cde-30bd-4c89-b5ee-2c1639589ced đang ở trạng thái In alarm và đây là một CloudWatch alarm để giám sát hệ thống. Nó sẽ kiểm tra liệu CPU Utilization trung bình trên toàn bộ các instances trong Auto Scaling Group có vượt quá 40% hay không. Nếu có, nó sẽ theo dõi việc này trong 3 lần kiểm tra liên tiếp, mỗi lần kiểm tra cách nhau trong vòng 3 phút. Nếu số lần vượt qua ngưỡng này đủ điều kiện, nó sẽ gửi một cảnh báo và kích hoạt các hành động tự động như tăng số lượng instances trong Auto Scaling Group để đáp ứng nhu cầu tải cao hơn.
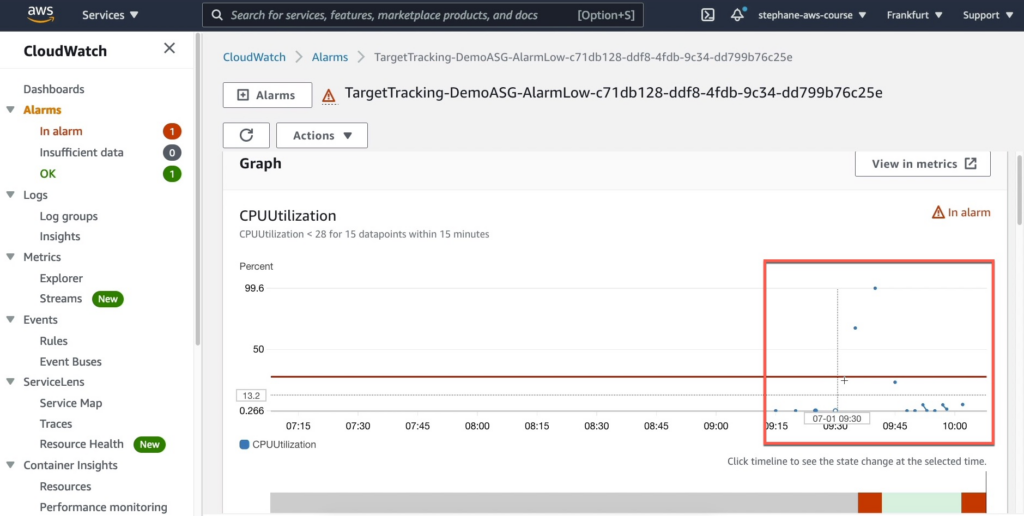
- Ở trigger TargetTracking-DemoASG-AlarmLow-c71db128-ddf8-4fdb-9c34-dd799b76c25e nó có nghĩa là trong vòng 15 phút, nếu CPU Utilization của các instances nằm trong Auto Scaling Group giảm xuống dưới mức 28% trong 15 mẫu dữ liệu liên tiếp, điều kiện này sẽ được đáp ứng và chuẩn đoán sẽ được kích hoạt. Có thể sử dụng chuẩn đoán này để giảm kích thước của Auto Scaling Group và giảm số lượng instances trong nhóm.
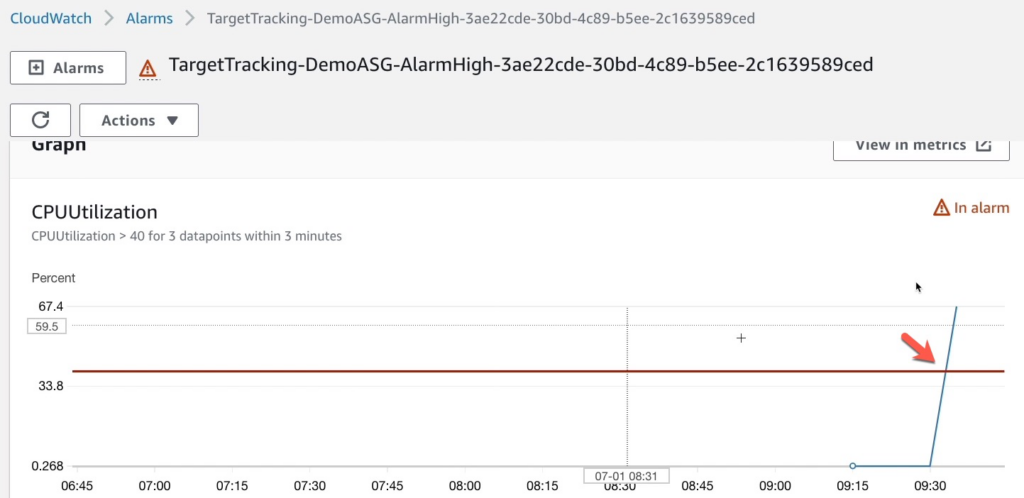
Và khi ta nhấp vào TargetTracking-DemoASG-AlarmHigh-3ae22cde-30bd-4c89-b5ee-2c1639589ced chúng ta có thể thấy ngưỡng CPU đã vượt quá 40% ở dấu mũi tên.
Và bây giờ mình sẽ phải dừng lệnh này để CPU hạ xuống dưới 40%, chúng ta sẽ xem chuyện j sẽ xảy ra.

Để dừng lệnh này bạn có thể khởi động lại EC2 gốc của mình và khởi động lại nó.
Bấm reboot.
Mình sẽ khởi động luôn máy EC2 mới được tạo ra.
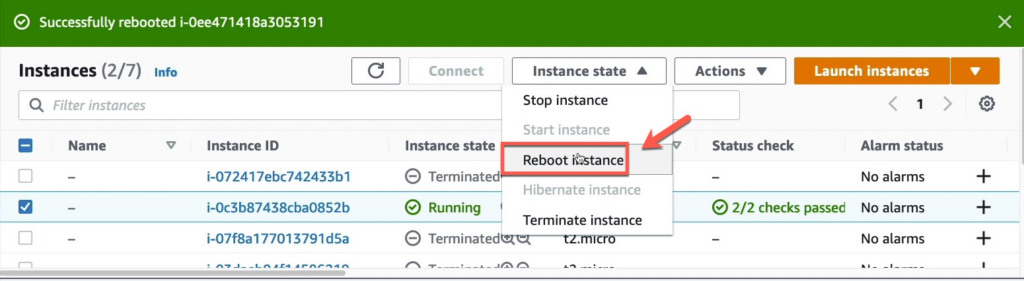
Bấm reboot.

Việc này sẽ làm cho CPU 2 máy chủ EC2 của mình trở về dưới mức 40% và nó sẽ kích hoạt trigger và xóa 1 EC2 trong vòng 15p.
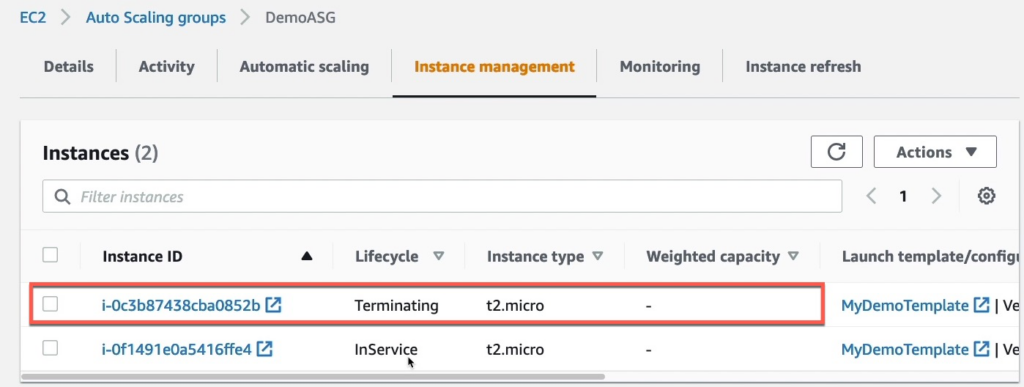
Bây giờ quay lại CloudWatch tại phần Alams bạn sẽ thấy 1 alam mới có tên TargetTracking-DemoASG-AlarmLow-c71db128-ddf8-4fdb-9c34-dd799b76c25e.
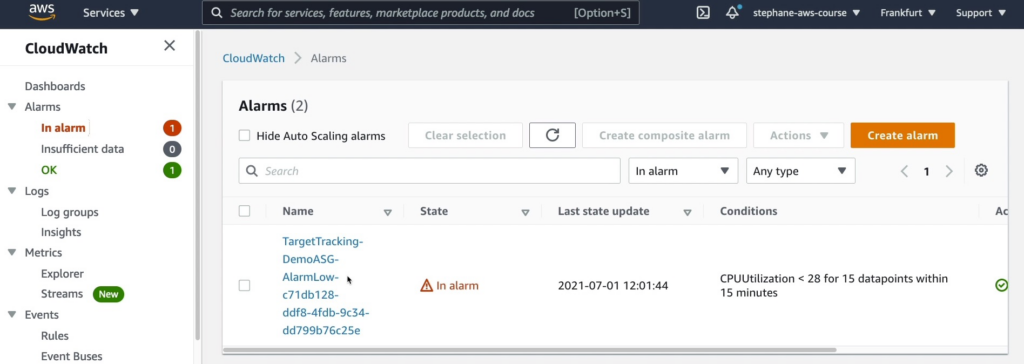
Hãy click vào nó bạn sẽ thấy phân đoạn mình đánh dấu có mức độ dùng CPU từ thấp đến cao và bắt đầu hạ xuống.