AWS Glue
AWS Glue là một dịch vụ quản lý quá trình extract, transform và load (ETL) dữ liệu. Dịch vụ này hữu ích trong việc chuẩn bị và chuyển đổi dữ liệu để sử dụng trong phân tích. Nó là một dịch vụ hoàn toàn không cần máy chủ (serverless).
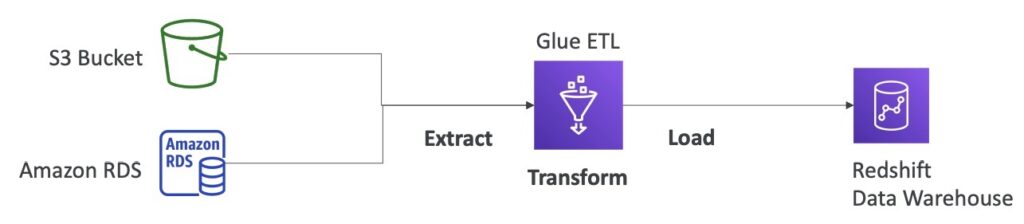
Sơ đồ trên đề cập đến việc sử dụng các dịch vụ của AWS để chuyển dữ liệu từ Amazon S3 và Amazon RDS, sau đó thực hiện ETL (extract, transform, and load) bằng AWS Glue và cuối cùng load dữ liệu vào data warehouse Redshift.
Cụ thể, Amazon S3 và Amazon RDS được sử dụng để lấy dữ liệu nguồn, sau đó dữ liệu được chuyển đến AWS Glue để thực hiện các bước ETL (trích xuất, biến đổi và tải). Kết quả của ETL được lưu trữ trong Redshift Data Warehouse để phục vụ cho các mục đích phân tích và thống kê.
Glue Data Catalog: catalog of datasets
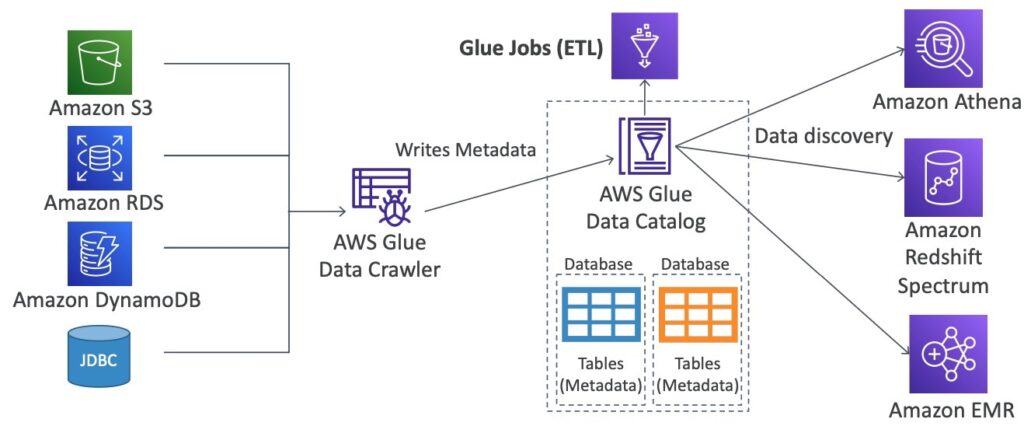
Sơ đồ trên nói về quá trình xử lý dữ liệu với sử dụng các dịch vụ của AWS. Cụ thể:
- Amazon S3, Amazon RDS, Amazon DynamoDB là các dịch vụ lưu trữ dữ liệu trên AWS.
- AWS Glue Data Crawler là một dịch vụ tự động phát hiện các loại dữ liệu khác nhau và tạo schema (metadata) cho chúng.
- AWS Glue Data Catalog là một service lưu trữ metadata cho các tài nguyên dữ liệu khác nhau (ví dụ: tables, databases, partitions).
- Các dữ liệu được phát hiện và lưu trữ metadata được sử dụng cho data discovery trong Amazon Athena, Amazon Redshift Spectrum, và Amazon EMR.
- AWS Glue Jobs là một dịch vụ xử lý ETL (extract, transform, and load) để chuẩn bị dữ liệu cho việc phân tích hoặc lưu trữ dữ liệu.
Glue – things to know at a high-level
Phần này chúng ta nói về quá trình sử dụng các dịch vụ của AWS để trích xuất, biến đổi và tải dữ liệu vào hệ thống Data Warehouse của mình. Cụ thể, quá trình này diễn ra như sau:
- Sử dụng các dịch vụ như Amazon S3, Amazon RDS, Amazon DynamoDB để lưu trữ dữ liệu.
- Sử dụng AWS Glue Data Crawler để quét dữ liệu từ các nguồn trên và ghi lại thông tin về các bảng, cột và liên kết dữ liệu vào AWS Glue Data Catalog. Điều này giúp cho việc tìm kiếm và phân tích dữ liệu trở nên dễ dàng hơn.
- Sử dụng các dịch vụ khác như Amazon Athena, Amazon Redshift Spectrum, Amazon EMR để khám phá và truy vấn dữ liệu được lưu trữ trong AWS Glue Data Catalog.
- Sử dụng Glue Jobs để thực hiện các tác vụ ETL trên dữ liệu. Glue Jobs sẽ sử dụng thông tin được lưu trữ trong AWS Glue Data Catalog để truy xuất và xử lý dữ liệu, và sau đó tải dữ liệu đã được xử lý vào hệ thống Data Warehouse của mình.
Quá trình này giúp cho việc trích xuất, biến đổi và tải dữ liệu trở nên dễ dàng và hiệu quả hơn bằng cách sử dụng các dịch vụ của AWS, và đồng thời giúp cho việc tìm kiếm và phân tích dữ liệu trở nên thuận tiện hơn thông qua AWS Glue Data Catalog.
