Kinesis Data Firehose.
Kinesis Data Firehose là một dịch vụ của Amazon Web Services (AWS) được sử dụng để nhận dữ liệu thời gian thực từ nhiều nguồn khác nhau và chuyển tiếp dữ liệu đó đến các kho lưu trữ khác nhau. Với Kinesis Data Firehose, bạn có thể chuyển dữ liệu đến Amazon S3, Amazon Redshift, Amazon Elasticsearch Service và Splunk để lưu trữ và phân tích dữ liệu.

Kinesis Data Firehose cho phép bạn xử lý dữ liệu thời gian thực trên những dòng dữ liệu lớn mà không cần tới các máy chủ riêng biệt. Nó cho phép bạn lựa chọn các công nghệ mã hóa để đảm bảo rằng dữ liệu của bạn được bảo mật. Bạn cũng có thể sử dụng các công cụ quản lý trình tự để tùy chỉnh các bước xử lý dữ liệu của mình, chẳng hạn như chuyển đổi định dạng hoặc thêm thông tin vào các bản ghi dữ liệu.
Một trong những ưu điểm của Kinesis Data Firehose là nó có khả năng tự động mở rộng khi dữ liệu của bạn tăng, do đó bạn không cần phải lo lắng về việc phải mua thêm máy chủ để xử lý dữ liệu. Bạn chỉ cần cấu hình Kinesis Data Firehose để xử lý dữ liệu của mình, sau đó dịch vụ sẽ tự động mở rộng khi dữ liệu tăng.
Ngoài ra, Kinesis Data Firehose cũng hỗ trợ các đối tác bên thứ ba như Splunk, MongoDB, DataDog và NewRelic, và bạn cũng có thể gửi dữ liệu đến bất kỳ điểm cuối HTTP nào.
Bạn chỉ phải trả tiền cho dữ liệu thông qua Kinesis Data Firehose. Dịch vụ này cung cấp thời gian thực gần như, với độ trễ tối thiểu là 60 giây cho các lô không đầy đủ hoặc tối thiểu 1 MB dữ liệu mỗi lần. Kinesis Data Firehose hỗ trợ nhiều định dạng dữ liệu, chuyển đổi, biến đổi và nén dữ liệu. Nó cũng cho phép bạn tùy chỉnh các biến đổi dữ liệu bằng cách sử dụng AWS Lambda.
Kinesis Data Firehose cũng hỗ trợ gửi dữ liệu không thành công hoặc tất cả dữ liệu đến một bucket S3 sao lưu. Nếu dịch vụ gặp sự cố khi xử lý dữ liệu, bạn có thể đưa dữ liệu đó vào bucket S3 sao lưu để sau đó tiếp tục xử lý hoặc giải quyết vấn đề.
Tóm lại, Kinesis Data Firehose là một dịch vụ quản lý đám mây, tự động mở rộng và không cần máy chủ. Nó cho phép chuyển dữ liệu đến nhiều kho lưu trữ khác nhau trên AWS và hỗ trợ nhiều đối tác bên thứ ba. Nó cũng cung cấp các tùy chọn tùy chỉnh cho các biến đổi dữ liệu, hỗ trợ gửi dữ liệu không thành công hoặc tất cả dữ liệu đến một bucket S3 sao lưu, và tính phí dựa trên lượng dữ liệu thông qua dịch vụ.
Kinesis Data Streams VS Firehose.
Kinesis Data Streams.
Kinesis Data Streams là một dịch vụ luồng (streaming) được thiết kế để chấp nhận, xử lý và lưu trữ dữ liệu trực tuyến lớn. Với Kinesis Data Streams, bạn có thể viết mã tùy chỉnh để tạo ra dữ liệu đầu vào (producer) hoặc xử lý dữ liệu đầu ra (consumer). Dịch vụ này cung cấp khả năng xử lý dữ liệu thời gian thực với độ trễ thấp (khoảng 200ms).
Kinesis Data Streams cũng hỗ trợ quản lý quy mô, bao gồm phân chia và hợp nhất cụm shard để mở rộng khả năng xử lý và giảm chi phí. Dịch vụ này cũng cho phép bạn lưu trữ dữ liệu trong khoảng thời gian từ 1 đến 365 ngày.
Một tính năng quan trọng của Kinesis Data Streams là khả năng phát lại dữ liệu. Bằng cách sử dụng tính năng này, bạn có thể xem lại, tái sử dụng và tái tạo lại dữ liệu đã xử lý trước đó. Điều này giúp bạn giải quyết các lỗi và xác nhận rằng dữ liệu của bạn được xử lý đúng cách.
Tóm lại, Kinesis Data Streams là một dịch vụ luồng (streaming) giúp bạn xử lý dữ liệu thời gian thực với độ trễ thấp và hỗ trợ khả năng phát lại dữ liệu. Nó cũng cho phép quản lý quy mô tự động, lưu trữ dữ liệu trong khoảng thời gian từ 1 đến 365 ngày, và cung cấp khả năng viết mã tùy chỉnh để tạo ra hoặc xử lý dữ liệu.
Kinesis Data Firehose.
Kinesis Data Firehose là một dịch vụ quản lý dữ liệu trực tuyến của Amazon Web Services (AWS) cho phép bạn tải dữ liệu luồng vào S3, Redshift, OpenSearch, các bên thứ ba hoặc địa chỉ HTTP tùy chỉnh một cách dễ dàng. Dịch vụ này được quản lý hoàn toàn và tự động, không cần phải quản lý hoặc cấu hình gì. Nó hỗ trợ khả năng tự động mở rộng để đáp ứng nhu cầu tải dữ liệu lớn.
Kinesis Data Firehose cung cấp khả năng xử lý dữ liệu gần thời gian thực, tuy nhiên, để đảm bảo tính chính xác và hiệu suất, dữ liệu được lưu trữ trong bộ đệm ít nhất 60 giây trước khi được chuyển đến đích cuối cùng. Dịch vụ này không lưu trữ dữ liệu trong khoảng thời gian dài hơn một vài phút và không hỗ trợ khả năng phát lại dữ liệu đã được xử lý.
Mặc dù Kinesis Data Firehose không có khả năng phát lại dữ liệu, tuy nhiên, dịch vụ này cung cấp một số tính năng như chuyển đổi định dạng dữ liệu, nén dữ liệu và chuyển đổi dữ liệu bằng mã tùy chỉnh, cho phép bạn dễ dàng xử lý dữ liệu của mình trước khi đưa vào lưu trữ cuối cùng.
Tóm lại, Kinesis Data Firehose là một dịch vụ AWS quản lý dữ liệu trực tuyến cho phép bạn tải dữ liệu luồng vào các lưu trữ cuối cùng như S3, Redshift hoặc OpenSearch một cách dễ dàng. Dịch vụ này hỗ trợ khả năng xử lý dữ liệu gần thời gian thực và tự động mở rộng. Tuy nhiên, nó không hỗ trợ khả năng phát lại dữ liệu đã được xử lý và không có tính năng lưu trữ dữ liệu trong thời gian dài.
Thực hành với Kinesis Data Firehose.

Tại Choose source and destination mình chọn source là Amazon Kinesis Data Streams và Destination là Amazon S3.
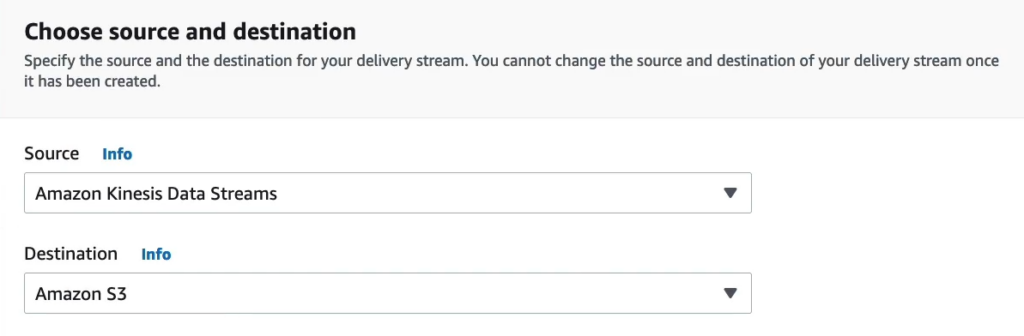
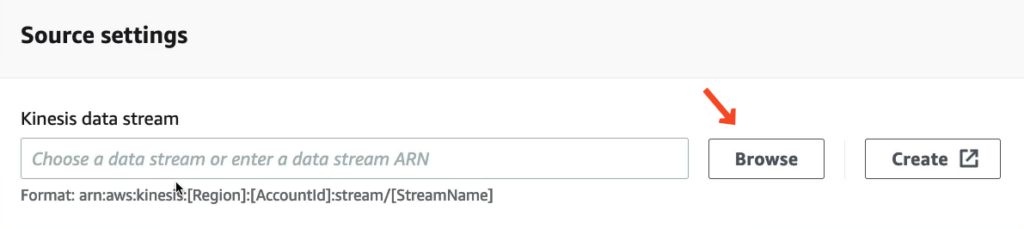
Tại Source settings chúng ta bấm Browse và tìm đến stream của bạn.
Ví dụ.
Delivery stream name sẽ được tạo tự động, nếu bạn không quan tâm hãy để nguyên tên đó và đi tới phần tiếp theo.
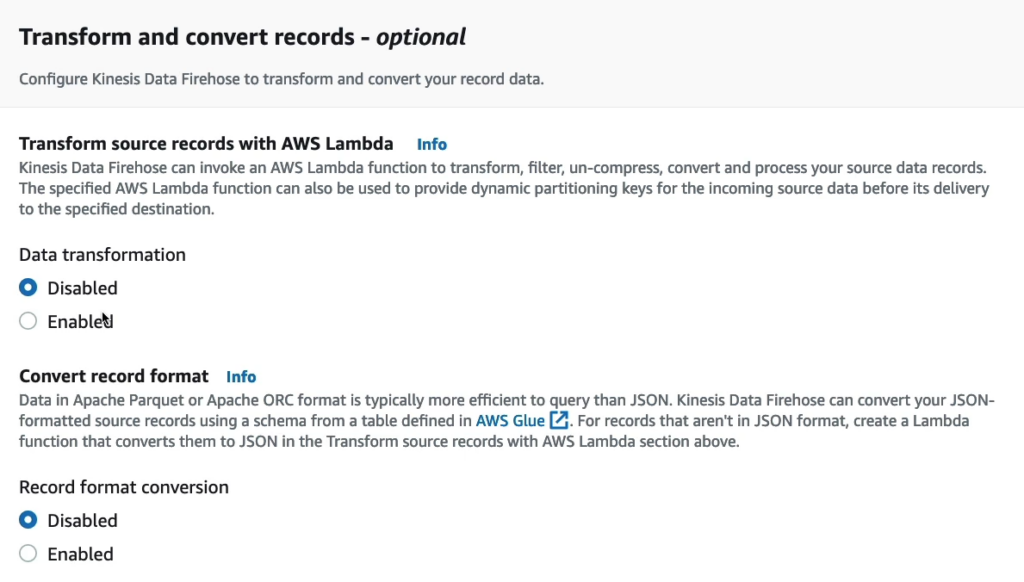
Tại phần Transform and convert records – optional có các lựa chọn như Transform source records with AWS Lambda và Convert record format.
Kinesis Data Firehose là một dịch vụ AWS cho phép bạn nhận dữ liệu luồng từ nhiều nguồn khác nhau và chuyển đến các dịch vụ khác nhau như Amazon S3, Redshift hoặc Elasticsearch để lưu trữ và phân tích dữ liệu. Khi bạn cấu hình Kinesis Data Firehose, bạn có thể chỉ định một chức năng AWS Lambda để thực hiện các phép biến đổi, lọc, giải nén, chuyển đổi và xử lý các bản ghi dữ liệu nguồn của bạn. Việc sử dụng chức năng Lambda giúp bạn có thể xử lý dữ liệu nguồn trước khi nó được chuyển đến đích cuối cùng. Lambda cung cấp một số tính năng mạnh mẽ, cho phép bạn thực hiện các phép biến đổi phức tạp trên dữ liệu, bao gồm tách dữ liệu thành các phần nhỏ hơn, xóa dữ liệu không cần thiết, mã hóa và giải mã, hoặc thực hiện bất kỳ tính toán nào khác. Một tính năng quan trọng khác của Lambda là khả năng cung cấp các khóa phân vùng động cho dữ liệu đầu vào nguồn của bạn trước khi gửi nó đến đích cuối cùng. Điều này cho phép bạn sắp xếp dữ liệu của mình theo cách tối ưu nhất cho các nhu cầu phân tích dữ liệu cuối cùng của bạn.
Apache Parquet và Apache ORC là hai định dạng file dữ liệu hiệu quả hơn để truy vấn so với định dạng JSON. Tuy nhiên, nhiều nguồn dữ liệu thường được định dạng theo JSON. Kinesis Data Firehose cho phép bạn chuyển đổi các bản ghi nguồn định dạng JSON sang định dạng Parquet hoặc ORC bằng cách sử dụng lược đồ được xác định từ một bảng trong AWS Glue EZ. Trong trường hợp các bản ghi nguồn không phải định dạng JSON, bạn có thể tạo một chức năng Lambda để chuyển đổi chúng sang định dạng JSON, sau đó sử dụng Kinesis Data Firehose để chuyển đổi các bản ghi này sang định dạng Parquet hoặc ORC. Để chuyển đổi định dạng dữ liệu của các bản ghi nguồn, Kinesis Data Firehose cung cấp một số tùy chọn để định dạng lại dữ liệu và ánh xạ các trường dữ liệu nguồn sang các trường dữ liệu đích tương ứng. Điều này cho phép bạn tùy chỉnh cách dữ liệu được định dạng lại và lưu trữ để đảm bảo phù hợp với nhu cầu phân tích dữ liệu của bạn.
Tới phần Destination settings hãy chọn 1 bucket hiện có của bạn.

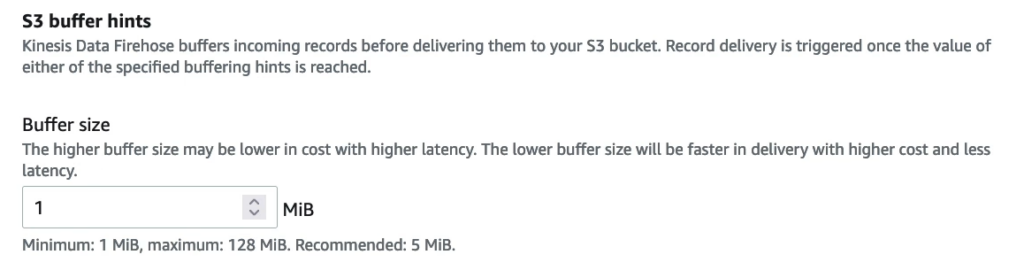
Kích thước bộ đệm (buffer size) trong Kinesis Data Firehose là thông số quan trọng để xác định số lượng bản ghi dữ liệu mà dịch vụ sẽ lưu trữ trước khi chuyển tiếp chúng đến đích cuối cùng.
Nếu bạn thiết lập kích thước bộ đệm lớn hơn, Kinesis Data Firehose sẽ lưu trữ nhiều bản ghi dữ liệu hơn trước khi chuyển tiếp chúng đến đích, điều này có thể giảm chi phí nhưng làm tăng thời gian chờ đợi (latency). Vì nó phải đợi đến khi đầy bộ đệm mới chuyển tiếp, điều này có thể làm chậm quá trình chuyển dữ liệu.
Ngược lại, nếu bạn thiết lập kích thước bộ đệm nhỏ hơn, Kinesis Data Firehose sẽ chuyển tiếp các bản ghi dữ liệu nhanh hơn đến đích cuối cùng, tuy nhiên điều này có thể tăng chi phí và giảm độ trễ. Vì nó phải chuyển tiếp các bản ghi dữ liệu nhanh hơn, điều này sẽ làm tăng số lượng kết nối tới dịch vụ đích cuối cùng, do đó làm tăng chi phí.
Do đó, khi thiết lập kích thước bộ đệm trong Kinesis Data Firehose, bạn cần cân nhắc giữa chi phí và độ trễ, để tối ưu hóa hiệu quả chuyển tiếp dữ liệu.
Khoảng thời gian bộ đệm (buffer interval) trong Kinesis Data Firehose là thời gian mà dịch vụ sẽ chờ đợi trước khi chuyển tiếp dữ liệu tới đích cuối cùng.
Nếu bạn thiết lập khoảng thời gian bộ đệm cao hơn, Kinesis Data Firehose sẽ có nhiều thời gian hơn để thu thập dữ liệu trước khi chuyển tiếp chúng đến đích cuối cùng. Khi đủ kích thước bộ đệm hoặc đạt đến thời gian đó, Kinesis Data Firehose sẽ chuyển tiếp các bản ghi dữ liệu tới đích cuối cùng. Điều này có thể làm cho kích thước dữ liệu lớn hơn, tuy nhiên sẽ làm tăng độ trễ.
Ngược lại, nếu bạn thiết lập khoảng thời gian bộ đệm thấp hơn, Kinesis Data Firehose sẽ chuyển tiếp các bản ghi dữ liệu tới đích cuối cùng thường xuyên hơn. Điều này có thể giúp bạn quan sát các chu kỳ hoạt động dữ liệu ngắn hơn, tuy nhiên sẽ tăng chi phí liên quan đến số lượng yêu cầu tới dịch vụ đích cuối cùng.
Kích thước mặc định của khoảng thời gian bộ đệm trong Kinesis Data Firehose là 900 giây (15 phút). Tuy nhiên, bạn có thể tùy chỉnh khoảng thời gian bộ đệm để phù hợp với nhu cầu của bạn, tùy thuộc vào các yêu cầu về độ trễ và kích thước dữ liệu của bạn.

Kinesis Data Firehose có thể nén các bản ghi trước khi gửi chúng đến bucket S3. Khi nén dữ liệu, kích thước file sẽ giảm, giúp tiết kiệm lưu trữ và giảm chi phí. Firehose cung cấp các tùy chọn nén dữ liệu khác nhau, bao gồm Snappy, GZIP, Zip Hadoop-Compatible Snappy.
- Snappy: là một công cụ nén dữ liệu được sử dụng để nén và giải nén dữ liệu trong kho lưu trữ phân tán, thường được sử dụng để tăng tốc độ truy cập dữ liệu.
- GZIP: là một trong những định dạng nén dữ liệu thông dụng nhất, sử dụng thuật toán nén LZ77 để giảm kích thước file.
- Zip Hadoop-Compatible Snappy: là một phương thức nén dữ liệu được tối ưu hóa cho các bản ghi lớn. Nó sử dụng thuật toán nén Snappy và mã hóa Deflate, cung cấp hiệu suất cao và tốc độ xử lý nhanh hơn so với các phương pháp khác.
Việc sử dụng các định dạng nén dữ liệu khác nhau tùy thuộc vào mục đích và yêu cầu của bạn. Kết hợp nén dữ liệu với các tùy chọn buffer size và buffer interval phù hợp sẽ giúp tối ưu hóa hoạt động và giảm chi phí.

Vì demo nên các cài đặt khác các bạn có thể để mặc định, bấm Create delivery stream để tạo delivery stream.

Sau khi tạo xong để test bạn bấm vào Test with demo data.

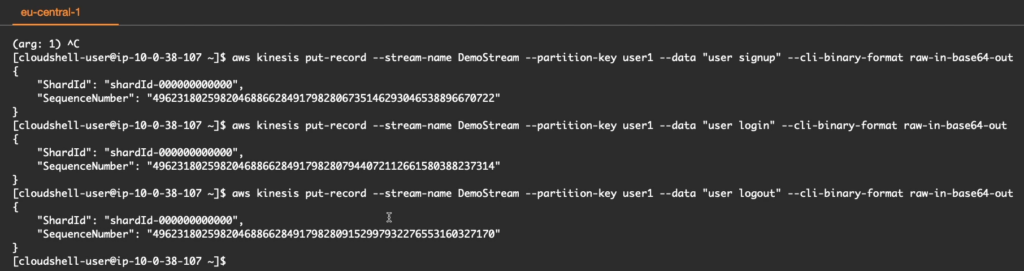
Giống như phần demo trước, chúng ta vào CloudShell và gửi các lệnh dưới để kiểm thử.
Bây giờ hãy vào Amazon S3 và tìm tới bucket demo-firehosestephane-v3.
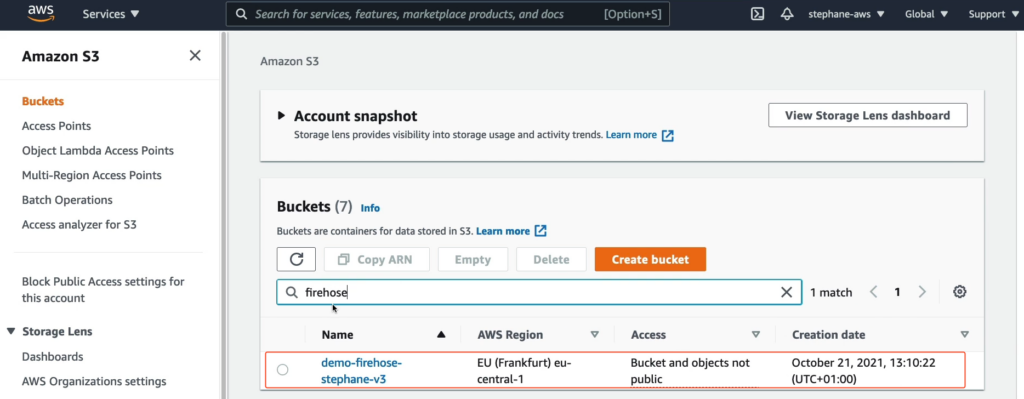
Bạn thấy hiện tại trong bucket demo-firehosestephane-v3 chưa có đối tượng nào, lý do là Kinesis Data Firehose đang set bộ đệm là 900 giây.

Sau khi đợi hết 900 giây, trong bucket demo-firehosestephane-v3 của mình đã có dữ liệu.
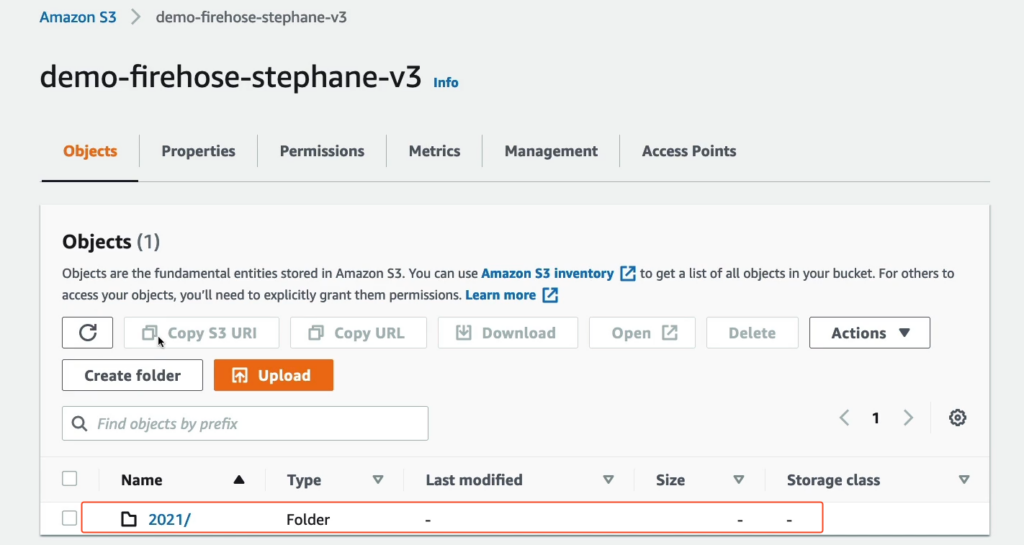
Dữ liệu được tạo thư mục theo năm/tháng/ngày/giờ nên bạn hãy vào từng thư mục và chúng ta có 1 file dữ liệu như dưới, hãy bấm Open để mở file này.

Khi mở ra bạn sẽ nhận được đoạn text như vậy cho thấy chúng ta có đăng ký người dùng, đăng nhập và đăng xuất người dùng.
user signupuser loginuser logout