Amazon OpenSearch Service
Amazon OpenSearch Service là một dịch vụ tìm kiếm của Amazon, kế thừa từ Amazon ElasticSearch. Trong DynamoDB, các truy vấn chỉ tồn tại bằng khóa chính hoặc các chỉ mục. Nhưng với OpenSearch, bạn có thể tìm kiếm bất kỳ trường nào, thậm chí là đối sánh một phần của nó. Thông thường, người ta sử dụng OpenSearch như một bổ sung cho cơ sở dữ liệu khác. OpenSearch yêu cầu một cụm các phiên bản (không có tính năng serverless) và không hỗ trợ SQL (nó có ngôn ngữ truy vấn riêng). Nó có thể nhập dữ liệu từ Kinesis Data Firehose, AWS IoT và CloudWatch Logs. An ninh được đảm bảo thông qua Cognito & IAM, mã hóa KMS và TLS. Nó đi kèm với OpenSearch Dashboards (trực quan hóa).
OpenSearch patterns DynamoDB
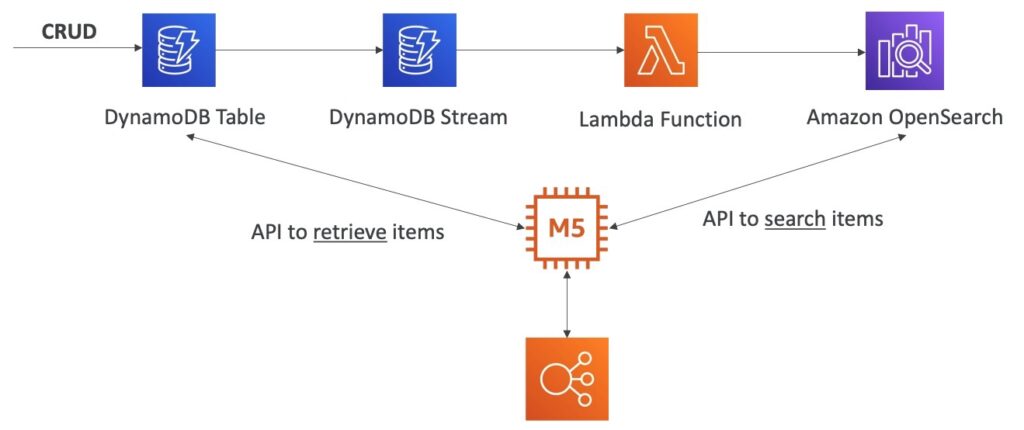
Sơ đồ trên đề cập đến quá trình di chuyển dữ liệu từ bảng DynamoDB tới Amazon OpenSearch thông qua DynamoDB Stream và Lambda Function. Quá trình này bao gồm việc thực hiện các thao tác CRUD (tạo, đọc, cập nhật và xóa) trên bảng DynamoDB, sau đó dữ liệu sẽ được gửi tới DynamoDB Stream và xử lý bởi Lambda Function trước khi được đưa vào Amazon OpenSearch.
Để truy vấn các mục trong Amazon OpenSearch, ta sử dụng API được đặt trên một EC2 Instance có cấu hình EC2M5. Trong khi đó, để lấy các mục từ bảng DynamoDB, ta cũng sử dụng một API trên một EC2 Instance khác có cấu hình tương tự.
OpenSearch patterns CloudWatch Logs
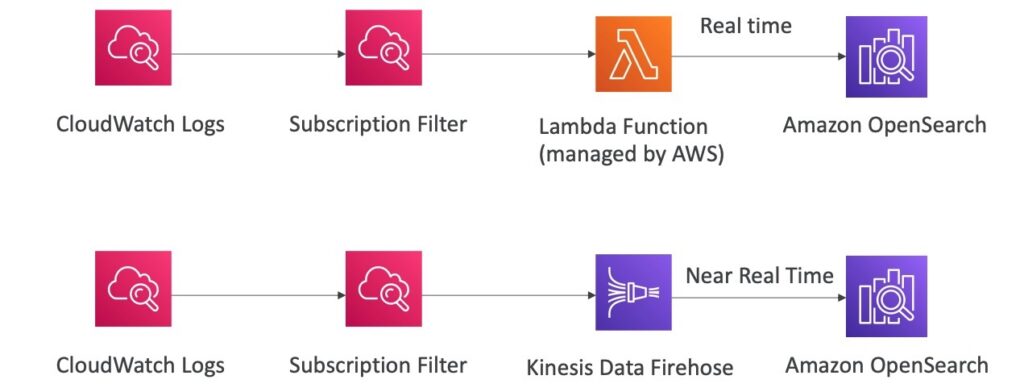
Sơ đồ trên đề cập đến hai quá trình khác nhau để đưa dữ liệu từ CloudWatch Logs vào Amazon OpenSearch.
Quá trình thứ nhất bao gồm việc sử dụng Subscription Filter để lọc dữ liệu từ CloudWatch Logs và sau đó gửi chúng tới một Lambda Function được quản lý bởi AWS để xử lý dữ liệu trước khi đưa chúng vào Amazon OpenSearch. Quá trình này là thời gian thực, có nghĩa là dữ liệu được xử lý ngay lập tức.
Quá trình thứ hai là sử dụng Kinesis Data Firehose để gửi dữ liệu từ CloudWatch Logs tới Amazon OpenSearch. Dữ liệu sẽ được gửi gần thời gian thực, có nghĩa là có một độ trễ rất nhỏ giữa khi dữ liệu được ghi lại trong CloudWatch Logs và khi nó được hiển thị trên Amazon OpenSearch.
OpenSearch patterns Kinesis Data Streams & Kinesis Data Firehose
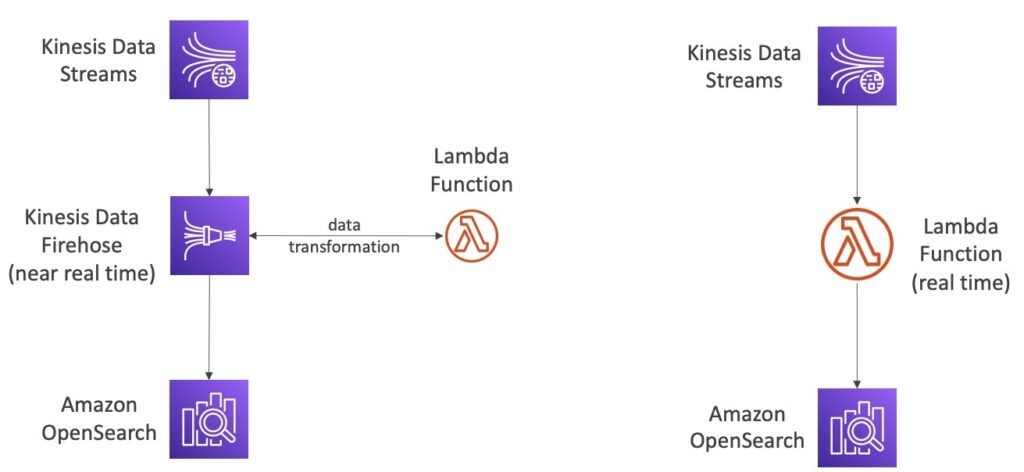
Quá trình đầu tiên bao gồm việc sử dụng Kinesis Data Firehose để nhận dữ liệu từ Kinesis Data Streams và gửi chúng đến Amazon OpenSearch. Quá trình này là gần thời gian thực, có nghĩa là có một độ trễ rất nhỏ giữa khi dữ liệu được ghi lại trong Kinesis Data Streams và khi nó được hiển thị trên Amazon OpenSearch. Quá trình tiếp theo là sử dụng Kinesis Data Firehose để nhận dữ liệu từ Kinesis Data Streams và sau đó thực hiện các bước chuyển đổi dữ liệu thông qua một Lambda Function trước khi đưa chúng vào Amazon OpenSearch. Quá trình này cũng gần thời gian thực, có nghĩa là có một độ trễ rất nhỏ giữa khi dữ liệu được ghi lại trong Kinesis Data Streams và khi nó được hiển thị trên Amazon OpenSearch.
Quá trình thứ 2 ở bên phải đề cập đến quá trình để đưa dữ liệu từ Kinesis Data Streams vào Amazon OpenSearch. Quá trình này bao gồm việc sử dụng một Lambda Function để xử lý dữ liệu từ Kinesis Data Streams trước khi đưa chúng vào Amazon OpenSearch. Lambda Function này sẽ được triển khai trong thời gian thực, có nghĩa là dữ liệu được xử lý ngay khi nó được ghi lại trong Kinesis Data Streams. Sau khi xử lý, dữ liệu được ghi vào Amazon OpenSearch để tìm kiếm và truy vấn.
Tóm lại, quá trình này cho phép dữ liệu được xử lý và đưa vào Amazon OpenSearch một cách nhanh chóng và thời gian thực, để người dùng có thể thực hiện các truy vấn và tìm kiếm trên dữ liệu mới nhất.
Amazon EMR
EMR là viết tắt của “Elastic MapReduce”. EMR giúp tạo các cụm Hadoop (Big Data) để phân tích và xử lý lượng dữ liệu lớn. Các cụm này có thể được tạo từ hàng trăm instances EC2. EMR đi kèm với các công cụ như Apache Spark, HBase, Presto, Flink… EMR lo lắng cho việc cấu hình và cung cấp tất cả các tài nguyên. Nó có khả năng tự động điều chỉnh quy mô và tích hợp với các instances Spot.
EMR có nhiều ứng dụng trong việc xử lý dữ liệu, học máy, đánh chỉ mục web và các ứng dụng liên quan đến Big Data.
Amazon QuickSight
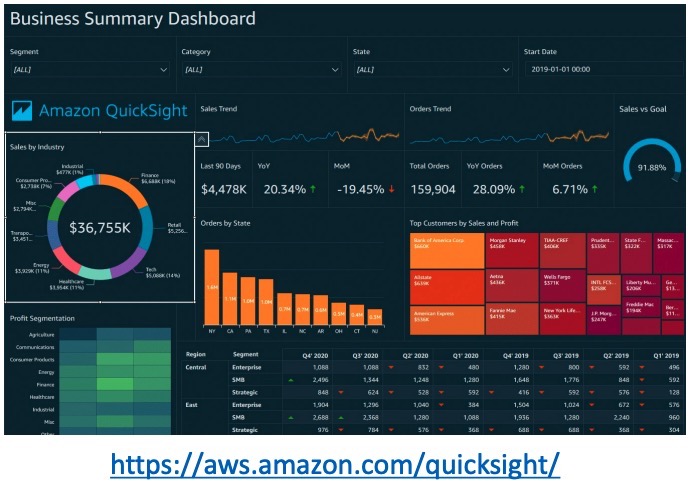
Amazon QuickSight là một dịch vụ năng suất kinh doanh được cung cấp bởi AWS, với sức mạnh của trí tuệ nhân tạo để tạo ra các bảng điều khiển tương tác. Nó có khả năng nhanh chóng mở rộng tự động, có thể nhúng, với giá tính theo phiên sử dụng. QuickSight được sử dụng để thực hiện các tác vụ phân tích kinh doanh, xây dựng trực quan hóa, thực hiện phân tích tạm thời và nhận thông tin kinh doanh từ dữ liệu. Nó tích hợp với nhiều dịch vụ khác của AWS như RDS, Aurora, Athena, Redshift, S3… Với SPICE engine, QuickSight có khả năng tính toán trong bộ nhớ nếu dữ liệu được nhập vào. Phiên bản Enterprise của QuickSight cung cấp khả năng thiết lập bảo mật theo cấp cột (CLS).
QuickSight Integrations
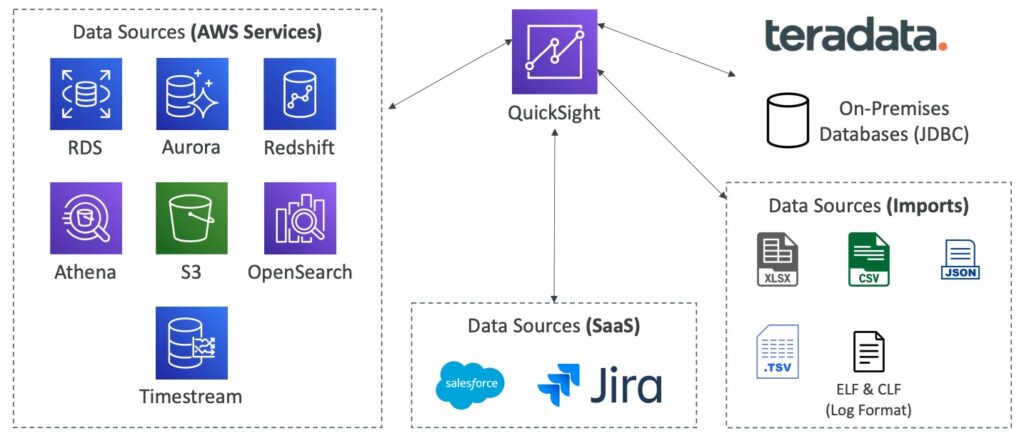
Đây là mô tả về các nguồn dữ liệu mà Amazon QuickSight có thể kết nối để tạo bảng điều khiển tương tác. Các nguồn dữ liệu bao gồm các dịch vụ AWS như RDS, Aurora, Redshift, Athena, S3, OpenSearch và Timestream. Ngoài ra, QuickSight cũng có thể kết nối đến các nguồn dữ liệu khác như Teradata (Cơ sở dữ liệu On-Premises sử dụng JDBC), các tập tin nhập khẩu với định dạng ELF & CLF (Log Format), tập tin tsv, xlsx, csv, json,… Và QuickSight cũng hỗ trợ kết nối đến các ứng dụng SaaS như Salesforce, Jira,.. để thu thập dữ liệu và hiển thị trên bảng điều khiển của QuickSight.
QuickSight – Dashboard & Analysis
QuickSight là một dịch vụ phân tích kinh doanh được tích hợp sẵn machine learning và có thể tạo các bảng điều khiển tương tác. QuickSight cho phép người dùng xác định các người dùng và nhóm của mình để chia sẻ bảng điều khiển và phân tích. Các người dùng và nhóm này chỉ tồn tại trong QuickSight và không liên quan đến IAM. Một bảng điều khiển là một bản chụp chỉ cho phép đọc của phân tích, bảo tồn cấu hình của phân tích (lọc, tham số, điều khiển, sắp xếp). Người dùng có thể chia sẻ phân tích hoặc bảng điều khiển với người dùng hoặc nhóm. Để chia sẻ một bảng điều khiển, người dùng phải xuất bản nó. Người dùng có thể xem dữ liệu cơ bản khi xem bảng điều khiển.
