1. Giới thiệu.
Chủ đề kết hợp Filebeat, Kafka và bộ ELK là một chủ đề rất thú vị và đang được nhiều người quan tâm trong lĩnh vực thu thập và phân tích log. Bài viết này mình sẽ giúp bạn xây dựng một bài viết chi tiết về chủ đề này.
Trong quản trị hệ thống, việc thu thập và phân tích log trở nên vô cùng quan trọng để giám sát hệ thống, phát hiện lỗi và tối ưu hóa hiệu năng. Bộ công cụ ELK (Elasticsearch, Logstash, Kibana) đã trở thành một tiêu chuẩn trong lĩnh vực này, cung cấp một nền tảng mạnh mẽ để lưu trữ, tìm kiếm và trực quan hóa dữ liệu log. Tuy nhiên, để khai thác tối đa tiềm năng của ELK, chúng ta cần có một giải pháp hiệu quả để thu thập log từ nhiều nguồn khác nhau và xử lý lượng lớn dữ liệu một cách nhanh chóng và đáng tin cậy. Đó là lúc Filebeat và Kafka cùng nhau xuất hiện, tạo nên một bộ ba hoàn hảo.
2. Filebeat.
Filebeat là một agent nhẹ, được thiết kế để thu thập log từ các file trên hệ thống và gửi chúng đến các output như Elasticsearch, Logstash hoặc Kafka. Với Filebeat, chúng ta có thể:
- Thu thập log từ nhiều nguồn khác nhau: Filebeat hỗ trợ nhiều loại file log phổ biến và có thể tùy chỉnh để thu thập log từ các ứng dụng tùy biến.
- Định dạng lại log: Filebeat có khả năng định dạng lại log trước khi gửi đi, giúp cho việc phân tích dữ liệu trở nên dễ dàng hơn.
- Tích hợp với các hệ thống khác: Filebeat có thể dễ dàng tích hợp với các hệ thống giám sát và quản lý log khác.
3. Kafka (hệ thống tin nhắn phân tán hiệu năng cao).
Kafka là một hệ thống tin nhắn phân tán, được thiết kế để xử lý lượng lớn dữ liệu trong thời gian thực. Với Kafka, chúng ta có thể:
- Đảm bảo độ tin cậy cao: Kafka cung cấp cơ chế lưu trữ dữ liệu bền vững và đảm bảo rằng các tin nhắn sẽ không bị mất.
- Xử lý dữ liệu song song: Kafka cho phép nhiều người tiêu dùng cùng lúc đọc dữ liệu từ một topic, giúp tăng khả năng xử lý.
- Tích hợp với nhiều hệ thống: Kafka có thể dễ dàng tích hợp với nhiều hệ thống khác nhau, bao gồm cả ELK.
4. Kết hợp Filebeat, Kafka và ELK.
Việc kết hợp Filebeat, Kafka và ELK mang lại nhiều lợi ích:
- Tăng khả năng mở rộng: Kafka giúp giảm tải cho Elasticsearch, cho phép hệ thống xử lý được lượng log lớn hơn.
- Cải thiện hiệu suất: Kafka cung cấp khả năng xử lý dữ liệu song song, giúp giảm thiểu độ trễ.
- Đảm bảo độ tin cậy: Kafka giúp đảm bảo rằng các log sẽ không bị mất, ngay cả khi xảy ra lỗi.
- Linh hoạt: Kafka cho phép chúng ta dễ dàng thay đổi cấu hình và mở rộng hệ thống.
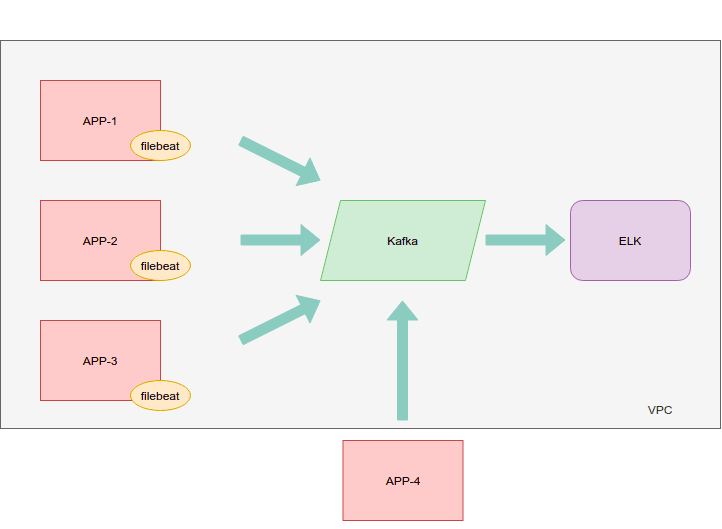
5. Quy trình hoạt động:
- Filebeat thu thập log từ các file trên hệ thống và gửi chúng đến một topic trên Kafka.
- Kafka lưu trữ các log trong các partition và phân phối chúng đến các consumer.
- Logstash (nếu sử dụng) đọc dữ liệu từ Kafka, tiến hành xử lý và định dạng lại log trước khi gửi đến Elasticsearch.
- Elasticsearch lưu trữ các log đã được định dạng và tạo ra các index để tìm kiếm và phân tích.
- Kibana cung cấp giao diện trực quan để truy vấn và trực quan hóa dữ liệu trong Elasticsearch.
6. Ứng dụng thực tế.
Việc kết hợp Filebeat, Kafka và ELK có rất nhiều ứng dụng trong thực tế, chẳng hạn như:
- Giám sát hệ thống: Theo dõi hoạt động của các ứng dụng và phát hiện các lỗi.
- Phân tích log: Tìm kiếm các pattern trong log để xác định nguyên nhân của các vấn đề.
- Tạo báo cáo: Tạo các báo cáo chi tiết về hoạt động của hệ thống.
- Phân tích hành vi người dùng: Phân tích log của người dùng để hiểu rõ hơn về cách họ sử dụng ứng dụng.
7. Ví dụ cơ bản cho việc triển khai bộ ba Filebeat, Kafka và ELK.
Bạn hãy theo dõi sơ đồ sau.
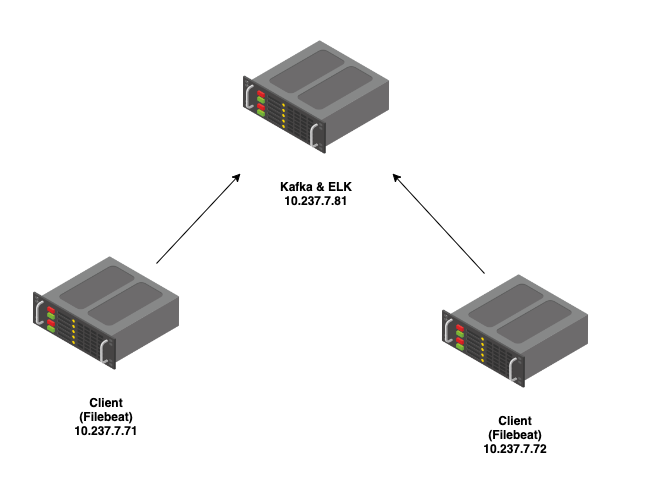
Để thiết lập môi trường sử dụng Filebeat để thu thập log từ /var/log/auth.log trên các server 10.237.7.71 và 10.237.7.72, đẩy log về Kafka tại 10.237.7.81, và sau đó xử lý và lưu trữ log trong bộ ELK (Elasticsearch, Logstash, Kibana) cũng tại 10.237.7.81 sử dụng Docker Compose, bạn cần thực hiện các bước sau:
Bước 1: Cài đặt Docker và Docker Compose.
Đảm bảo Docker và Docker Compose đã được cài đặt trên tất cả các server.
Bước 2: Cấu hình Kafka trên Server 10.237.7.81
Tạo file docker-compose-kafka.yml trên server 10.237.7.81 với nội dung sau:
version: '3'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 10.237.7.81
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sockChạy Kafka và Zookeeper bằng lệnh:
docker-compose -f docker-compose-kafka.yml up -dBước 3: Cấu hình Filebeat trên 10.237.7.71 và 10.237.7.72.
Tạo file docker-compose-filebeat.yml trên cả hai server với nội dung sau:
version: '3'
services:
filebeat:
image: docker.elastic.co/beats/filebeat:7.9.3
volumes:
- /var/log/auth.log:/var/log/auth.log
- ./filebeat.yml:/usr/share/filebeat/filebeat.yml
environment:
- output.kafka.hosts=["10.237.7.81:9092"]Tạo file cấu hình filebeat.yml trên cả hai server:
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/auth.log
output.kafka:
hosts: ["10.237.7.81:9092"]
topic: "auth-logs"Phân quyền cho file /var/log/auth.log.
chmod -R 775 /var/log/auth.logChạy Filebeat bằng lệnh:
docker-compose -f docker-compose-filebeat.yml up -dBước 4: Cấu hình ELK Stack trên 10.237.7.81
Tạo file docker-compose-elk.yml trên server 10.237.7.81:
version: '3'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.9.3
ports:
- "9200:9200"
environment:
- discovery.type=single-node
logstash:
image: docker.elastic.co/logstash/logstash:7.9.3
ports:
- "5000:5000"
volumes:
- ./logstash.conf:/usr/share/logstash/pipeline/logstash.conf
depends_on:
- elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:7.9.3
ports:
- "5601:5601"
depends_on:
- elasticsearchTạo file cấu hình logstash.conf để nhận log từ Kafka và đẩy vào Elasticsearch:
input {
kafka {
bootstrap_servers => "10.237.7.81:9092"
topics => ["auth-logs"]
}
}
output {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "auth-logs-%{+YYYY.MM.dd}"
}
}Chạy ELK Stack bằng lệnh:
docker-compose -f docker-compose-elk.yml up -dBằng cách thực hiện các bước trên, bạn đã thiết lập một môi trường để thu thập log từ /var/log/auth.log trên các server 10.237.7.71 và 10.237.7.72, đẩy log về Kafka tại 10.237.7.81, và sau đó xử lý và lưu trữ log trong bộ ELK cũng tại 10.237.7.81 sử dụng Docker Compose.
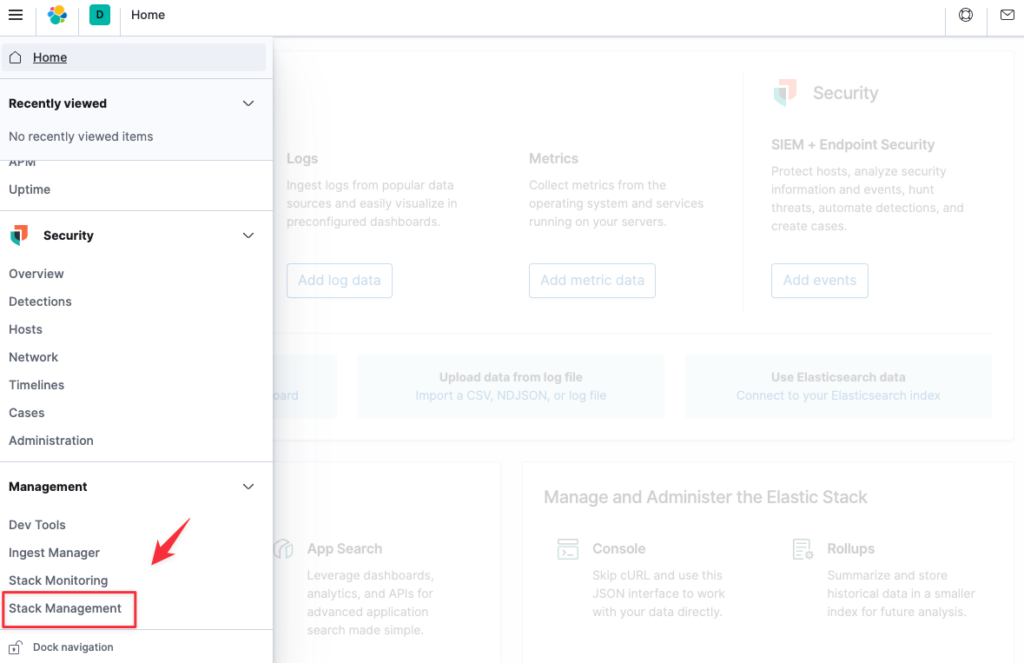
Giờ bạn truy cập vào Kibana bằng url http:10.237.7.81:5601, vào Stack Management.
Vào Index Patterns, tại Define index pattern hãy điền vào define index pattern name sau đó bấm Next step.
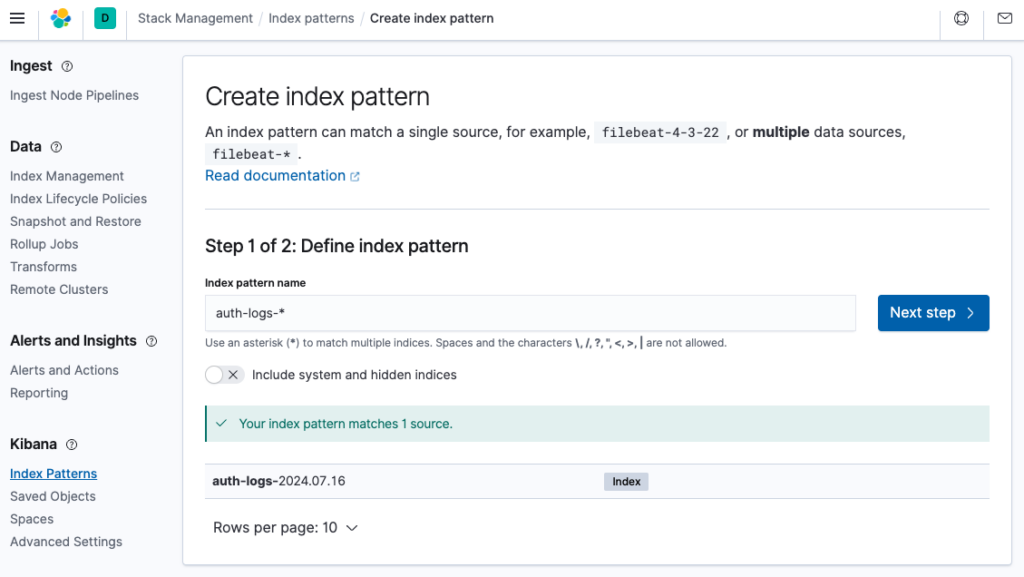
Mình chọn Time field là @timestamp và bấm Create index pattern.
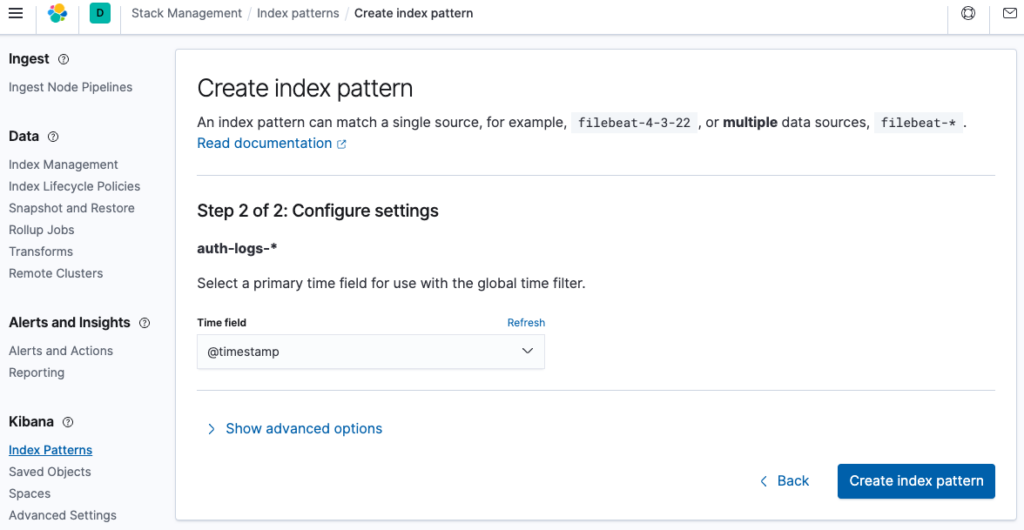
Hoàn thành.
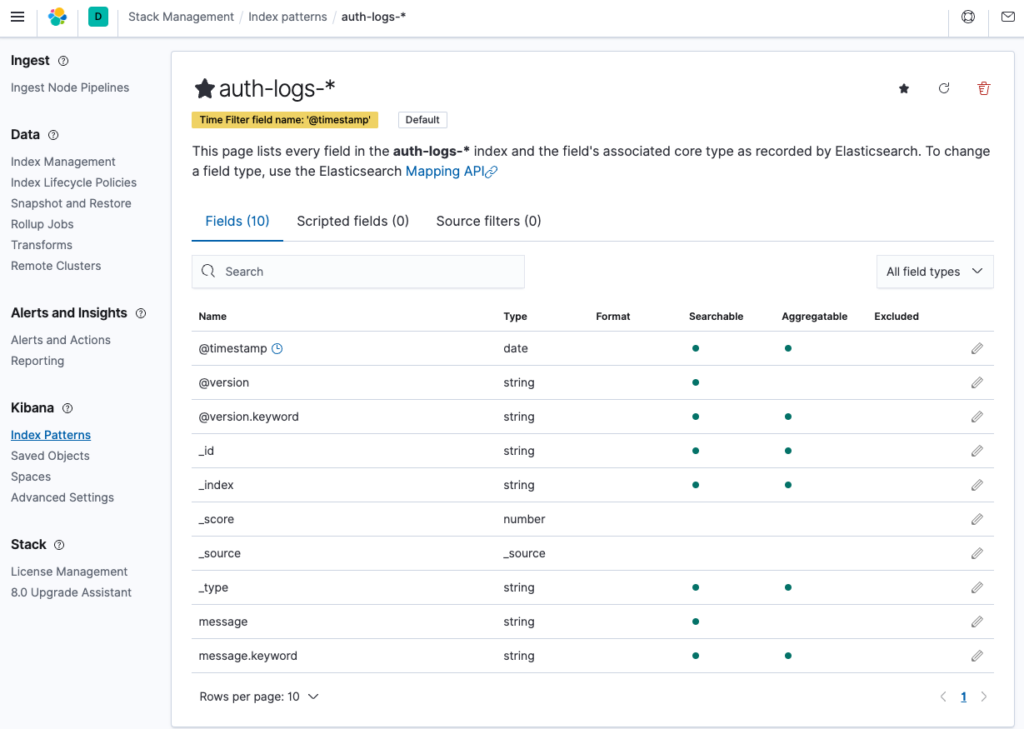
Giờ vào xem danh sách các index tại Index Management bạn sẽ thấy index auth-loqs-2024.07.16 đã xuất hiện.
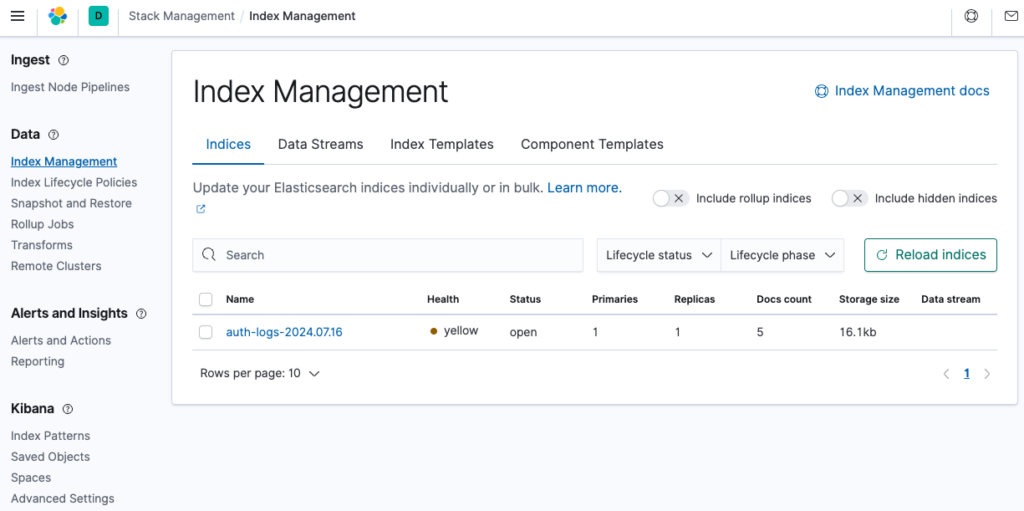
Và đây là kết quả log trên Discover.
8. Một số lưu ý và các lệnh quản trị cơ bản.
Lệnh xem một index Elasticsearch đang nhận dữ liệu từ topic Kafka nào?
Không có lệnh trực tiếp nào cho phép bạn xem một index Elasticsearch đang nhận dữ liệu từ topic Kafka nào mà không kiểm tra cấu hình. Cách duy nhất để biết chính xác là xem qua cấu hình Logstash hoặc bất kỳ công cụ trung gian nào bạn đang sử dụng để chuyển tiếp dữ liệu từ Kafka sang Elasticsearch.
Liệt kê các topic hiện có trong Kafka.
Để hiển thị các topic hiện có trong Kafka, bạn có thể sử dụng lệnh kafka-topics.sh từ terminal. Lệnh này là một phần của bộ công cụ mà Kafka cung cấp và cho phép bạn quản lý và kiểm tra các topic. Dưới đây là cách sử dụng lệnh:
kafka-topics.sh --list --bootstrap-server <Kafka Server>:<port>Nếu bạn không chắc chắn về vị trí cài đặt của Kafka, bạn có thể sử dụng lệnh find trên Linux/MacOS hoặc dir trên Windows để tìm kiếm file kafka-topics.sh hoặc kafka-topics.bat trong hệ thống của bạn. Ví dụ trên Linux/MacOS:
shell> find / -name kafka-topics.sh 2>/dev/null
/opt/kafka_2.13-2.8.1/bin/kafka-topics.shThay thế <Kafka Server> và <port> với địa chỉ và cổng của máy chủ Kafka của bạn. Ví dụ, nếu Kafka của bạn chạy trên localhost với cổng mặc định là 9092, ví dụ:
shell> cd /opt/kafka_2.13-2.8.1/bin/
shell> kafka-topics.sh --list --bootstrap-server localhost:9092
__consumer_offsets
auth-logsTopic __consumer_offsets trong Kafka.
Topic __consumer_offsets là một topic đặc biệt trong Kafka được sử dụng để lưu trữ thông tin về offsets của các consumer. Mỗi khi một consumer đọc dữ liệu từ một topic, nó cần biết vị trí cuối cùng mà nó đã đọc để có thể tiếp tục đọc từ vị trí đó khi cần. Kafka sử dụng topic __consumer_offsets để lưu trữ thông tin này.
Dưới đây là một số điểm quan trọng về topic __consumer_offsets:
- Quản lý Offset: Nó giúp Kafka theo dõi vị trí “offset” mà mỗi consumer group đã đọc đến trong mỗi partition của mỗi topic. Điều này cho phép các consumer tiếp tục đọc từ đúng vị trí mà chúng đã dừng, ngay cả sau khi bị ngắt kết nối hoặc khi có sự cố.
- Tự động Tạo: Topic này được Kafka tự động tạo ra và quản lý. Bạn không cần phải tạo hoặc quản lý nó một cách thủ công.
- Cấu hình: Mặc dù được tạo tự động, nhưng các cài đặt của
__consumer_offsetscó thể được điều chỉnh thông qua cấu hình của Kafka broker. Tuy nhiên, việc thay đổi cấu hình này không được khuyến khích trừ khi bạn hiểu rõ về hệ thống và có lý do chính đáng. - Bảo mật và Quyền truy cập: Mặc dù là một phần quan trọng của hệ thống Kafka, nhưng không phải lúc nào bạn cũng cần truy cập trực tiếp vào topic này. Trong hầu hết các trường hợp, việc quản lý offsets được thực hiện tự động bởi Kafka và các client của nó.
Cách để biết topic đó từ đâu đẩy tới và server nào lấy dữ liệu từ topic này?
Dựa vào thông tin bạn cung cấp từ file logstash.conf và việc con trỏ đang ở dòng đầu tiên, để biết topic đó từ đâu đẩy tới và server nào lấy dữ liệu từ topic này, bạn cần xem phần cấu hình input trong file logstash.conf đó. Trong phần input, đặc biệt là khi sử dụng plugin kafka, bạn sẽ tìm thấy thông tin về các topic Kafka mà Logstash đang lắng nghe, cũng như thông tin về các server Kafka.
Dưới đây là một ví dụ về cách cấu hình input cho Kafka trong logstash.conf:
input {
kafka {
bootstrap_servers => "kafka-server1:9092,kafka-server2:9092"
topics => ["your-topic-name"]
...
}
}Trong đoạn cấu hình này:
bootstrap_serverschỉ định danh sách các server Kafka mà Logstash kết nối để lấy dữ liệu. Đây là nơi bạn có thể xác định server nào đang đẩy dữ liệu tới topic mà Logstash lắng nghe.topicschỉ định tên của các topic mà Logstash sẽ lắng nghe và lấy dữ liệu.
Kiểm tra thông tin cơ bản về các topic.
Bạn có thể sử dụng một số lệnh CLI của Kafka để kiểm tra thông tin cơ bản về các topic, nhưng những lệnh này không cung cấp thông tin chi tiết về nguồn dữ liệu đẩy tới hoặc điểm đích mà dữ liệu được gửi đến. Các lệnh CLI của Kafka chủ yếu giúp bạn quản lý và kiểm tra trạng thái của các topic, partition, consumer group, v.v.
Để xem thông tin chi tiết về một topic cụ thể, bạn có thể sử dụng lệnh kafka-topics.sh với tùy chọn --describe:
kafka-topics.sh --describe --topic your-topic-name --bootstrap-server localhost:9092Ví dụ:
kashell> fka-topics.sh --describe --topic auth-logs --bootstrap-server localhost:9092
Topic: auth-logs TopicId: iIstzc9JTny4hmaVqc1OOg PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: auth-logs Partition: 0 Leader: 1001 Replicas: 1001 Isr: 1001Thông tin này cho biết auth-logs là một topic với một partition duy nhất, không có bản sao dự phòng, và được lưu trữ trên broker với ID 1001. Kích thước tối đa của một segment file cho topic này là 1GB. Cụ thể:
- Topic: Tên của topic, trong trường hợp này là
auth-logs. - TopicId: Định danh duy nhất của topic trong cluster Kafka,
iIstzc9JTny4hmaVqc1OOgtrong trường hợp này. - PartitionCount: Số lượng partition của topic.
1chỉ ra rằng topic này có một partition. - ReplicationFactor: Số lượng bản sao của mỗi partition.
1chỉ ra rằng mỗi partition chỉ có một bản sao, không có bản sao dự phòng. - Configs: Các cấu hình cụ thể cho topic.
segment.bytes=1073741824chỉ ra kích thước tối đa của một segment file trên đĩa là 1GB. Kafka lưu trữ dữ liệu của mỗi partition trong các segment files.
Về thông tin chi tiết của partition:
- Partition: Số hiệu của partition,
0trong trường hợp này. - Leader: ID của broker đang giữ vai trò leader cho partition này.
1001chỉ ra rằng broker với ID 1001 là leader. - Replicas: Danh sách các broker có bản sao của partition này.
1001chỉ ra rằng chỉ có một broker (ID 1001) có bản sao của partition này. - Isr: Tập hợp các broker trong trạng thái đồng bộ (In-Sync Replicas) với leader.
1001chỉ ra rằng broker 1001 đang đồng bộ với chính nó (vì chỉ có một bản sao).
Hoặc để kiểm tra các consumer group và offset của chúng, bạn có thể sử dụng lệnh kafka-consumer-groups.sh:Nhưng để biết nguồn dữ liệu cụ thể (ứng dụng hoặc dịch vụ nào đang đẩy dữ liệu vào topic) và điểm đích mà dữ liệu được gửi đến (ứng dụng hoặc dịch vụ nào đang đọc dữ liệu từ topic), bạn cần xem cấu hình của các ứng dụng hoặc dịch vụ đó, như Logstash trong trường hợp này.
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group your-consumer-groupĐể liệt kê danh sách các consumer groups trong Kafka, bạn có thể sử dụng công cụ kafka-consumer-groups.sh đi kèm với Kafka. Dưới đây là cách thực hiện từ terminal:
shell> kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
logstashKiểm tra các consumer group và offset.
shell> kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group logstash
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
logstash auth-logs 0 136 136 0 logstash-0-7bda5734-37ff-4a91-b4d8-3fbb1ab38de9 /172.18.0.1 logstash-0Kết quả trên cung cấp thông tin chi tiết về trạng thái của consumer group logstash đối với topic auth-logs. Thông tin này cho biết consumer group logstash đang theo dõi và đã đọc hết tất cả messages trong partition 0 của topic auth-logs mà không có lag nào (tức là đã đọc đến message mới nhất). Consumer này chạy trên máy chủ có địa chỉ IP là 172.18.0.1 và có ID là logstash-0-7bda5734-37ff-4a91-b4d8-3fbb1ab38de9.
Trong đó.
- GROUP: Tên của consumer group, ở đây là
logstash. - TOPIC: Tên của topic mà consumer group đang theo dõi, trong trường hợp này là
auth-logs. - PARTITION: Số hiệu của partition trong topic mà consumer group đang đọc dữ liệu.
0chỉ ra rằng consumer group này đang đọc dữ liệu từ partition 0 của topicauth-logs. - CURRENT-OFFSET: Offset hiện tại mà consumer group đã đọc tới trong partition.
136chỉ ra rằng consumer group đã đọc tới message thứ 136. - LOG-END-OFFSET: Offset cuối cùng trong log của partition.
136chỉ ra rằng message cuối cùng trong partition là message thứ 136. - LAG: Số lượng messages chưa được consumer group đọc.
0chỉ ra rằng không có lag, tức là consumer group đã đọc hết tất cả messages có trong partition. - CONSUMER-ID: Định danh duy nhất của consumer trong group.
logstash-0-7bda5734-37ff-4a91-b4d8-3fbb1ab38de9là ID của consumer này. - HOST: Địa chỉ IP của máy chủ mà consumer đang chạy.
/172.18.0.1chỉ ra địa chỉ IP của máy chủ. - CLIENT-ID: Định danh của client Kafka.
logstash-0là ID của client này.
Kết luận.
Việc kết hợp Filebeat, Kafka và ELK là một giải pháp hiệu quả và linh hoạt để thu thập và phân tích log. Bằng cách tận dụng các ưu điểm của từng công cụ, chúng ta có thể xây dựng một hệ thống giám sát và phân tích log mạnh mẽ, đáp ứng được các yêu cầu của các hệ thống hiện đại.
