Gần đây tôi nhận được một chia sẻ rất thú vị từ một bạn đang tự triển khai cluster lưu trữ Ceph với toàn bộ sử dụng default config nhưng vẫn đưa lại hiệu năng khá cao. Bạn ấy gửi tôi kết quả benchmark của cluster Ceph tự build gồm 3 node, mỗi node có 3 ổ đĩa NVMe. Tổng cộng là 9 OSD hoạt động trong hệ thống.
Cụ thể, bạn ấy đang sử dụng switch 40Gbps và toàn bộ hệ thống đều chạy trên nền tảng SSD NVMe – một hướng đi hợp lý trong các hệ thống yêu cầu hiệu năng IO cao như AI/ML, streaming, lưu trữ RBD cho VM, hoặc CephFS dùng cho backend ứng dụng cần truy cập nhanh.
Tuy nhiên trong trường hợp của cụm Ceph bạn này lý do đạt hiệu năng cao tôi có suy nghĩ như sau:
Mặc dù cấu hình đang để mặc định (ví dụ số PG còn thấp, chưa có tuning nhiều), hệ thống vẫn cho hiệu năng ấn tượng, bởi vì:
🔹 NVMe quá mạnh → giúp giảm bottleneck tại disk layer
🔹 Network 40G → tránh tắc nghẽn khi Ceph truyền replication hoặc client truy cập
🔹 Replication 3 vẫn chạy mượt mà vì cả disk và mạng đều dư sức gánh tải
Nếu so sánh với hệ thống dùng SSD hoặc HDD:
SSD SATA sẽ có độ trễ và IOPS thấp hơn NVMe rất nhiều → dễ bị bottleneck khi PG tăng hoặc client load tăng.
HDD thì còn hạn chế hơn nữa về IOPS, thường phù hợp với cold storage hoặc cần kết hợp thêm cache tier.
Trong cả hai trường hợp này, để đạt hiệu năng tương tự thì phải tuning rất kỹ (PG num chuẩn, cấu hình thread, backfill, recovery, thậm chí dùng erasure coding để tiết kiệm IO).
Dưới đây là chi tiết về kết quả kiểm tra hiệu năng mà bạn ấy chia sẻ.
⚙️ Đây là sơ đồ hệ thống Ceph của bạn ấy mà tôi đoán bạn ấy đang áp dụng.
┌─────────────────────────────┐
│ SWITCH 40Gbps (MTU 9000)│
└────────────┬────────────────┘
│
┌──────────────────────────┼──────────────────────────┐
│ │ │
┌──────▼──────┐ ┌───────▼──────┐ ┌───────▼──────┐
│ NODE 1 │ │ NODE 2 │ │ NODE 3 │
│------------ │ │--------------│ │--------------│
│ OSD.0 (NVMe1)│ │ OSD.3 (NVMe4)│ │ OSD.6 (NVMe7)│
│ OSD.1 (NVMe2)│ │ OSD.4 (NVMe5)│ │ OSD.7 (NVMe8)│
│ OSD.2 (NVMe3)│ │ OSD.5 (NVMe6)│ │ OSD.8 (NVMe9)│
└─────────────┘ └──────────────┘ └──────────────┘
Public & Cluster Network (Shared 40Gbps, Jumbo Frame MTU 9000)🔍 Cấu hình cluster.
- Số lượng node: 3 node vật lý
- Mỗi node có 3 ổ NVMe => tổng cộng 9 ổ NVMe
- Mỗi ổ NVMe chạy 1 OSD => cluster có 9 OSD
- Tất cả node kết nối vào switch 40Gbps, có thể dùng chung cho cả public network và cluster network, hoặc tách riêng nếu có 2 card mạng.
- Switch đã được bật MTU 9000 (Jumbo Frame) để tối ưu hiệu năng truyền dữ liệu (vì bạn này sử dụng Switch 40G nên tôi đoán là MTU 9000 nhưng có thể không phải).
- Test trực tiếp: chạy benchmark ngay trên node
📊 Kết Quả Benchmark
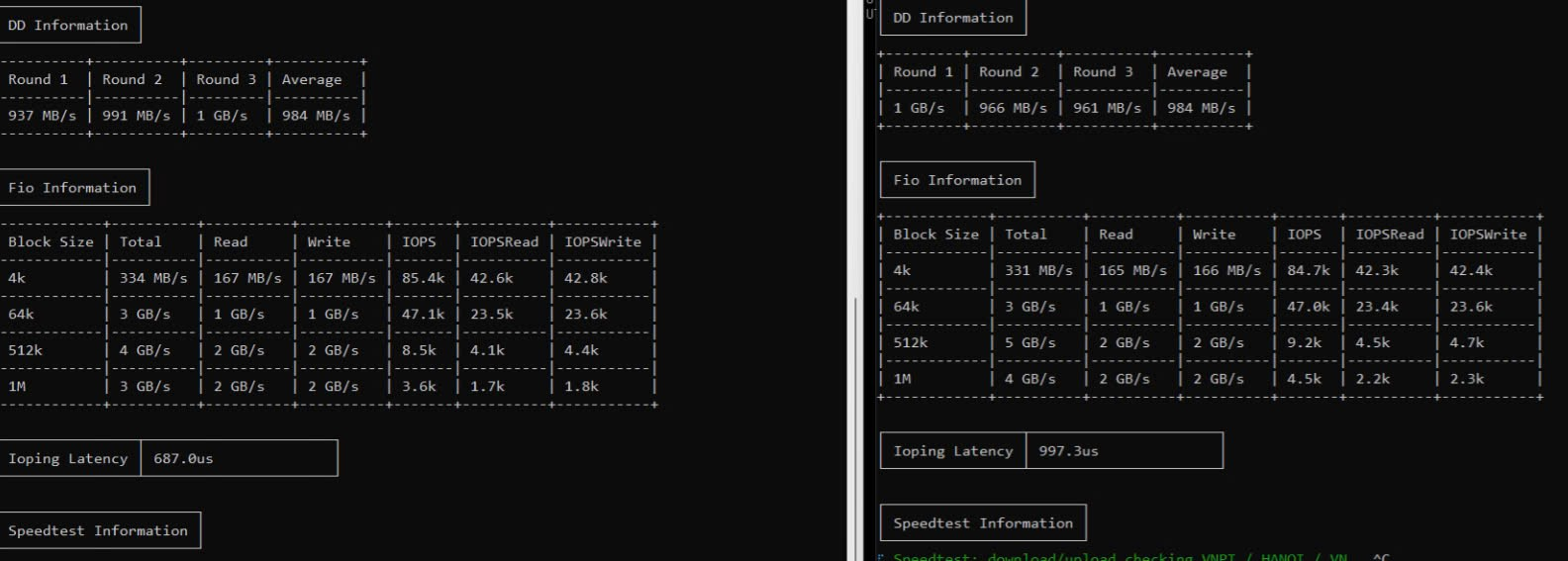
DD Test (ghi tuần tự)
| Vòng 1 | Vòng 2 | Vòng 3 | Trung bình |
|---|---|---|---|
| 937 MB/s | 991 MB/s | 1 GB/s | ~984 MB/s |
FIO Test – Random I/O với nhiều block size
| Block Size | Tổng (Read+Write) | Read | Write | IOPS | IOPS Read | IOPS Write |
|---|---|---|---|---|---|---|
| 4k | 334 MB/s | 167 MB/s | 167 MB/s | 85.4k | 42.6k | 42.8k |
| 64k | 3 GB/s | 1.5 GB/s | 1.5 GB/s | 47k | 23.5k | 23.6k |
| 512k | 4 GB/s | 2 GB/s | 2 GB/s | 8.5k | 4.1k | 4.4k |
| 1M | 3–4 GB/s | 2 GB/s | 2 GB/s | 3.6k–4.5k | 1.7k–2.2k | 1.8k–2.3k |
Ioping (latency)
- 687 – 997 µs (micro giây)
=> Tức ~0.6ms đến ~1ms, rất tốt cho NVMe.
🔍 Đánh Giá Hiệu Năng
Với hệ thống gồm 9 OSD NVMe trên 3 node, tôi đánh giá kết quả benchmark như trên là rất ổn.
Một số nhận xét chi tiết:
✅ Ưu điểm:
- IOPS 4k ~85k: đây là con số khá ấn tượng và phù hợp với cluster nhỏ chỉ 9 OSD.
- Throughput 64k–512k lên đến 4–5 GB/s: cho thấy hệ thống đạt hiệu năng cao khi làm việc với block size lớn, rất phù hợp với workload như backup, media, database.
- Độ trễ IO thấp (<1ms): đạt tiêu chuẩn của hệ thống sử dụng ổ NVMe.
- Hiệu suất đọc ghi cân bằng (Read = Write): đây là dấu hiệu của hệ thống ổn định và không bị nghẽn một chiều.
❓ Còn có thể tối ưu thêm không?
Mặc dù hệ thống đã khá tốt, nhưng vẫn còn vài điểm có thể cải thiện nếu muốn đẩy hệ thống đến giới hạn cao hơn:
🛠️ Gợi ý tối ưu cho cluster Ceph 3 node (9 OSD NVMe, replication 3)
🔢 Tăng số lượng PGs (Placement Groups)
✅ Hiện tại:
+---------+
| Client |
+---------+
|
v
+-----------+
| Pool |
+-----------+
|
+---------------+-------------------+
| | |
PG1 PG2 PG3
| | |
+-------+----+ +-----+-----+ +------+------+
| | | | | | | | | |
OSD1 OSD4 OSD7 OSD2 OSD5 OSD8 OSD3 OSD6 OSD9- Mỗi pool mặc định có thể chỉ là 128 PGs → quá thấp cho 9 OSD.
- Ceph khuyến nghị dùng công thức: mathematicaCopyEdit
Total PGs = (Number of OSDs * 100) / Pool size
📌 Gợi ý:
- Với 9 OSD và pool replication size = 3: CopyEdit
(9 * 100) / 3 = 300 PGs - Vậy bạn có thể nâng lên ít nhất từ 256 → 512 PGs (tùy mức độ sử dụng hiện tại).
⚠️ Lưu ý:
- Tăng PGs nên được thực hiện khi cluster đang hoạt động ổn định, không có backfill/recovery đang chạy.
- Có thể chia nhỏ để scale dần từ 128 → 256 → 512 nếu cần.
⚙️ Tune bluestore và osd để tận dụng NVMe
ceph config set osd osd_mclock_scheduler true
ceph config set osd bluestore_cache_size 4294967296 # 4GB cache
ceph config set osd osd_memory_target 8589934592 # 8GB target mem (tuỳ RAM)
- NVMe có tốc độ rất cao, nhưng nếu để cache mặc định quá nhỏ thì không tận dụng được hết băng thông.
- Mỗi OSD nên có ít nhất 4–6GB RAM nếu dùng NVMe để đạt hiệu quả cao nhất.
🧪 Dùng pool erasure coded nếu cần tiết kiệm dung lượng
Nếu workload thiên về cold storage (ít ghi, chủ yếu đọc): có thể dùng EC pool như k=4, m=2 → tiết kiệm hơn nhưng vẫn đảm bảo độ bền.
Tăng luồng khi test FIO để có thể xem được performance tối đa nhất.
Hiện tại có thể output trên do đang chạy FIO đơn luồng. Hãy chạy test với nhiều thread hơn, ví dụ:
fio --name=randread --iodepth=64 --rw=randread --bs=4k --direct=1 --size=4G --numjobs=8 --runtime=60 --group_reporting --filename=/dev/your_deviceĐiều này sẽ giúp đẩy hết băng thông của hệ thống và tránh bị giới hạn bởi số lượng thread.
Kiểm tra CPU/IRQ Affinity
Phân phối OSD theo CPU core để tránh bottleneck. Dùng tuna, irqbalance, hoặc numactl để pin các OSD daemon vào các core khác nhau.
📌 Kết Luận
Cluster 3 node với 9 ổ NVMe, switch 40G, benchmark như trên là một kết quả hoàn toàn ổn, phù hợp với nhiều workload từ mức trung đến cao. Với một vài điều chỉnh nhỏ như tăng số luồng test, tối ưu mạng và xử lý CPU affinity, bạn hoàn toàn có thể đạt ngưỡng hiệu năng cao hơn nữa.
Nhưng mà hiệu năng hiện tại của hệ thống phần lớn là nhờ phần cứng chất lượng cao, chứ không phải do cấu hình Ceph được tối ưu.”
→ Đây là điểm quan trọng để chia sẻ lại cho cộng đồng, tránh hiểu lầm là “dùng default là chạy nhanh”, mà phải đặt trong bối cảnh phần cứng đang “gánh team”.
