1.Tổng quan về giám sát OSDS và PGS.
Ceph là một hệ thống lưu trữ phân tán, được thiết kế để cung cấp hiệu suất cao, độ tin cậy cao và không có điểm chết đơn lẻ. Điều này có nghĩa là nếu một phần của hệ thống gặp sự cố, Ceph vẫn có thể tiếp tục phục vụ yêu cầu dữ liệu, ngay cả khi nó đang hoạt động trong chế độ “degraded” (giảm chất lượng).
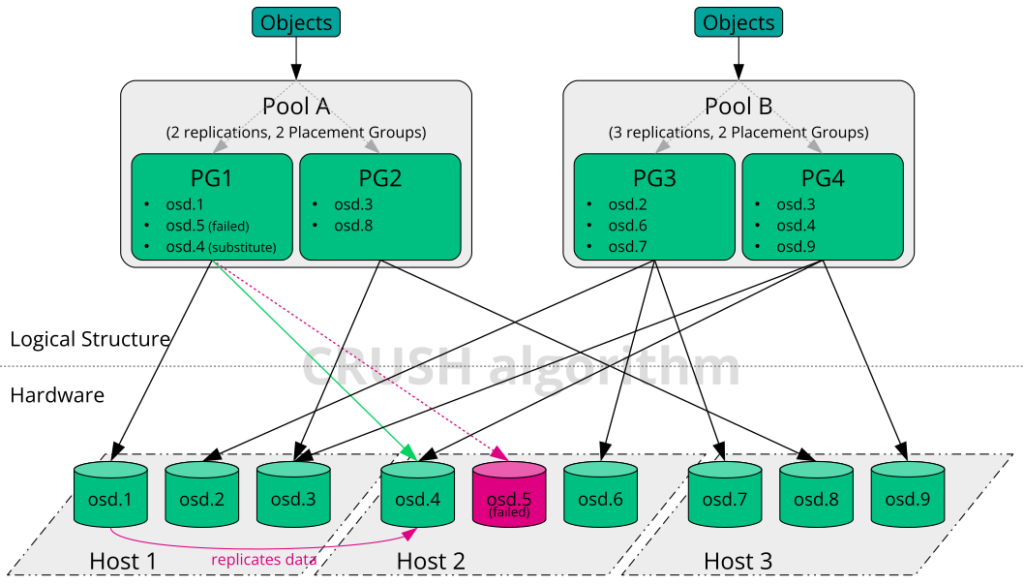
Ceph sử dụng một cơ chế gọi là “data placement” để đảm bảo rằng dữ liệu không bị ràng buộc trực tiếp với các OSD (Object Storage Daemons) cụ thể. Điều này giúp Ceph linh hoạt hơn trong việc xử lý sự cố và phục hồi từ chúng.
Khi gặp sự cố, bạn đừng quá lo lắng vì Ceph có khả năng tự sửa chữa. Thay vào đó, bạn nên theo dõi các OSD và placement groups của mình, sau đó bắt đầu xử lý sự cố. Mặc dù Ceph có khả năng tự sửa chữa, nhưng nếu vấn đề vẫn tiếp tục, việc giám sát OSD và placement groups sẽ giúp bạn xác định vấn đề.

Lưu ý rằng một sự cố ở một phần của cluster có thể ngăn bạn truy cập vào một đối tượng cụ thể, nhưng điều đó không có nghĩa là bạn bị ngăn chặn truy cập vào các đối tượng khác.
2. Giám sát OSDS.
Các trạng thái trong OSD.
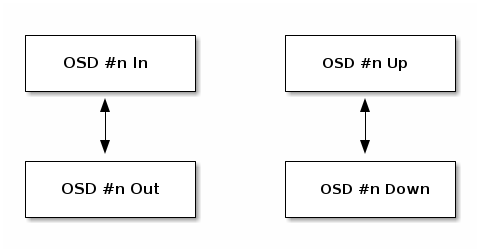
OSD (Object Storage Daemons) là các thành phần chịu trách nhiệm lưu trữ và truy xuất dữ liệu. Mỗi OSD có thể ở trong hai trạng thái chính: “in” (đang hoạt động) hoặc “out” (không hoạt động) và “up” (đang chạy và có thể truy cập được) hoặc “down” (không chạy và không thể truy cập được).
- Một OSD (Object Storage Daemon) trong hệ thống lưu trữ Ceph khi ở trạng thái “up” (hoạt động) có thể ở hai trạng thái phục vụ khác nhau: “in” (đang phục vụ) hoặc “out” (không phục vụ).
- “In”: OSD đang hoạt động và phục vụ dữ liệu cho các client. Ceph sẽ sử dụng OSD này để lưu trữ và truy xuất dữ liệu.
- “Out”: Mặc dù OSD đang hoạt động (up) nhưng nó không phục vụ dữ liệu cho các client. Ceph sẽ không sử dụng OSD này để lưu trữ dữ liệu mới hoặc di chuyển dữ liệu hiện có vào đây.
Trạng thái này cho phép quản lý linh hoạt hơn việc sử dụng và không sử dụng các OSD trong hệ thống, cho phép việc bảo dưỡng và nâng cấp mà không làm gián đoạn dịch vụ.
Vì vậy, một OSD có thể ở trạng thái “up” nhưng không phục vụ dữ liệu (nghĩa là “out of service”), hoặc nó có thể ở trạng thái “up” và đang phục vụ dữ liệu (nghĩa là “in service”).
Nếu một OSD ở trạng thái “out”, CRUSH (thuật toán phân bổ dữ liệu của Ceph) sẽ không gán placement groups cho nó. Nếu một OSD ở trạng thái “down”, nó cũng sẽ ở trạng thái “out”.
Lưu ý rằng nếu một OSD ở trạng thái “down” và “in”, đây là một vấn đề và điều này cho thấy rằng cluster không ở trong trạng thái lành mạnh. Đây là một tình huống có xảy ra trong hệ thống lưu trữ Ceph khi một OSD (Object Storage Daemon) ở trạng thái “down” (không hoạt động) nhưng vẫn ở trạng thái “in” (đang phục vụ).
- “Down”: OSD không hoạt động, nghĩa là nó không thể liên lạc được hoặc không chạy.
- “In”: OSD đang phục vụ, nghĩa là Ceph sẽ sử dụng OSD này để lưu trữ và truy xuất dữ liệu.
Khi một OSD ở trạng thái “down” nhưng vẫn “in”, điều này có nghĩa là Ceph vẫn đang cố gắng sử dụng một OSD không hoạt động để lưu trữ và truy xuất dữ liệu. Điều này là một vấn đề lớn vì nó có thể gây ra mất mát dữ liệu hoặc gián đoạn dịch vụ. Đó là lý do tại sao đoạn văn nói rằng “điều này cho thấy rằng cluster không ở trong trạng thái lành mạnh”.
Trong một số trường hợp, cluster có thể không hiển thị “HEALTH OK”. Điều này có thể xảy ra trong các tình huống sau:
- Bạn chưa bắt đầu chạy cluster.
- Bạn vừa khởi động hoặc khởi động lại cluster và nó chưa sẵn sàng để hiển thị trạng thái sức khỏe, bởi vì các Placement Group (PG) đang trong quá trình được tạo và các OSD (Object Storage Daemons) đang trong quá trình peering.
- Bạn vừa thêm hoặc loại bỏ một OSD.
- Bạn vừa chỉnh sửa lại cluster map của mình.
Việc kiểm tra xem OSD có đang hoạt động hay không rất quan trọng của việc giám sát chúng. Bất cứ khi nào cluster đang hoạt động thì tất cả các OSD trong cluster cũng nên ở trạng thái đang hoạt động. Để xem tất cả OSD của cluster có đang hoạt động hay không, bạn có thể chạy lệnh sau:
ceph osd statKết quả xuất ra sẽ cung cấp các thông tin sau: tổng số OSD (x), số OSD đang hoạt động (up) (y), số OSD đang trong trạng thái “in” (z) và epoch của bản đồ (eNNNN).
Epoch là một số nguyên dùng để đánh dấu phiên bản của map (bản đồ) của cluster. Mỗi khi có sự thay đổi trong cấu trúc của cluster (như thêm hoặc xóa một OSD, thay đổi trạng thái của một OSD, v.v.), Ceph sẽ tạo ra một bản đồ mới của cluster và tăng epoch lên một đơn vị.
x osds: y up, z in; epoch: eNNNNVí dụ trường hợp này “epoch: e9392” có nghĩa là bản đồ hiện tại của cluster là phiên bản thứ 9392. Điều này cho thấy đã có 9392 thay đổi đã được thực hiện trên cluster kể từ khi nó được khởi tạo.
Điều này giúp người quản lý hệ thống theo dõi sự tiến triển và thay đổi của cluster theo thời gian.
shell> ceph osd stat
32 osds: 32 up (since 10w), 32 in (since 11w); epoch: e9392Nếu số lượng OSD (Object Storage Daemons) trong cluster lớn hơn số lượng OSD đang hoạt động, bạn có thể chạy lệnh ceph osd tree để xác định các daemon ceph-osd không đang chạy:
shell> ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 111.77881 root default
-3 27.94470 host pve01
0 ssd 3.49309 osd.0 up 1.00000 1.00000
1 ssd 3.49309 osd.1 down 0 0
2 ssd 3.49309 osd.2 up 1.00000 1.00000
3 ssd 3.49309 osd.3 up 1.00000 1.00000
4 ssd 3.49309 osd.4 up 1.00000 1.00000
5 ssd 3.49309 osd.5 up 1.00000 1.00000
6 ssd 3.49309 osd.6 up 1.00000 1.00000
7 ssd 3.49309 osd.7 up 1.00000 1.00000
-5 27.94470 host pve02
8 ssd 3.49309 osd.8 up 1.00000 1.00000
9 ssd 3.49309 osd.9 up 1.00000 1.00000
10 ssd 3.49309 osd.10 up 1.00000 1.00000
11 ssd 3.49309 osd.11 up 1.00000 1.00000
12 ssd 3.49309 osd.12 up 1.00000 1.00000
13 ssd 3.49309 osd.13 up 1.00000 1.00000
14 ssd 3.49309 osd.14 up 1.00000 1.00000
15 ssd 3.49309 osd.15 up 1.00000 1.00000
-7 27.94470 host pve03
16 ssd 3.49309 osd.16 up 1.00000 1.00000
17 ssd 3.49309 osd.17 up 1.00000 1.00000
18 ssd 3.49309 osd.18 up 1.00000 1.00000
19 ssd 3.49309 osd.19 up 1.00000 1.00000
20 ssd 3.49309 osd.20 up 1.00000 1.00000
21 ssd 3.49309 osd.21 up 1.00000 1.00000
22 ssd 3.49309 osd.22 up 1.00000 1.00000
23 ssd 3.49309 osd.23 up 1.00000 1.00000
-9 27.94470 host pve04
24 ssd 3.49309 osd.24 up 1.00000 1.00000
25 ssd 3.49309 osd.25 up 1.00000 1.00000
26 ssd 3.49309 osd.26 up 1.00000 1.00000
27 ssd 3.49309 osd.27 up 1.00000 1.00000
28 ssd 3.49309 osd.28 up 1.00000 1.00000
29 ssd 3.49309 osd.29 up 1.00000 1.00000
30 ssd 3.49309 osd.30 up 1.00000 1.00000
31 ssd 3.49309 osd.31 up 1.00000 1.0000Lệnh này sẽ hiển thị cấu trúc cây của cluster, bao gồm tất cả các OSD và trạng thái của chúng. Điều này giúp bạn xác định vị trí vật lý của các OSD cụ thể, có thể hỗ trợ bạn trong việc khắc phục sự cố của cluster.
Nếu một OSD đang ở trạng thái “down”, bạn có thể khởi động nó bằng cách chạy lệnh sau:
sudo systemctl start ceph-osd@1Trong đó, “1” là ID của OSD bạn muốn khởi động.
Đối với các vấn đề liên quan đến OSD bị stop và không khởi động lại được, bạn có thể tham khảo tài liệu hoặc hướng dẫn về “OSD Not Running” để tìm hiểu thêm.
3. Giám sát PG.
Thuật toán CRUSH trong Ceph.
CRUSH (Controlled Replication Under Scalable Hashing) là thuật toán mà Ceph sử dụng để xác định cách phân bổ và sao chép dữ liệu trong cluster. Khi CRUSH gán một Placement Group (PG) cho các OSD (Object Storage Daemons), nó sẽ xác định số lượng bản sao của PG cần thiết cho pool và sau đó gán mỗi bản sao cho một OSD khác nhau.
Ví dụ, nếu pool yêu cầu ba bản sao của một PG, CRUSH có thể gán chúng riêng lẻ cho osd.1, osd.2 và osd.3. CRUSH tìm kiếm một vị trí ngẫu nhiên mà cũng đồng thời xem xét các failure domains mà bạn đã đặt trong bản đồ CRUSH của mình; vì lý do này, PGs hiếm khi được gán cho các OSD liền kề trong một cluster lớn.
Failure domains là một khái niệm quan trọng liên quan đến cách dữ liệu được phân phối và sao lưu trong cluster. Một failure domain có thể được hiểu là một nhóm các OSD (Object Storage Daemons) mà nếu một sự cố xảy ra, tất cả các OSD trong nhóm đó có thể bị ảnh hưởng.
Ví dụ, nếu bạn đặt một rack chứa nhiều OSD làm một failure domain, điều đó có nghĩa là Ceph sẽ cố gắng không đặt nhiều bản sao của cùng một dữ liệu trên các OSD nằm trong cùng một rack. Điều này giúp ngăn ngừa mất mát dữ liệu nếu toàn bộ rack gặp sự cố.
Up set và Acting Set trong Ceph.
Acting set được xác định bởi Ceph OSD daemon, Acting set là tập hợp các OSD mà một object hoặc một phần của object hiện đang được lưu trữ. Acting set giúp Ceph xác định nơi để đọc dữ liệu hiện có, đảm bảo rằng dữ liệu luôn sẵn sàng cho các yêu cầu đọc.
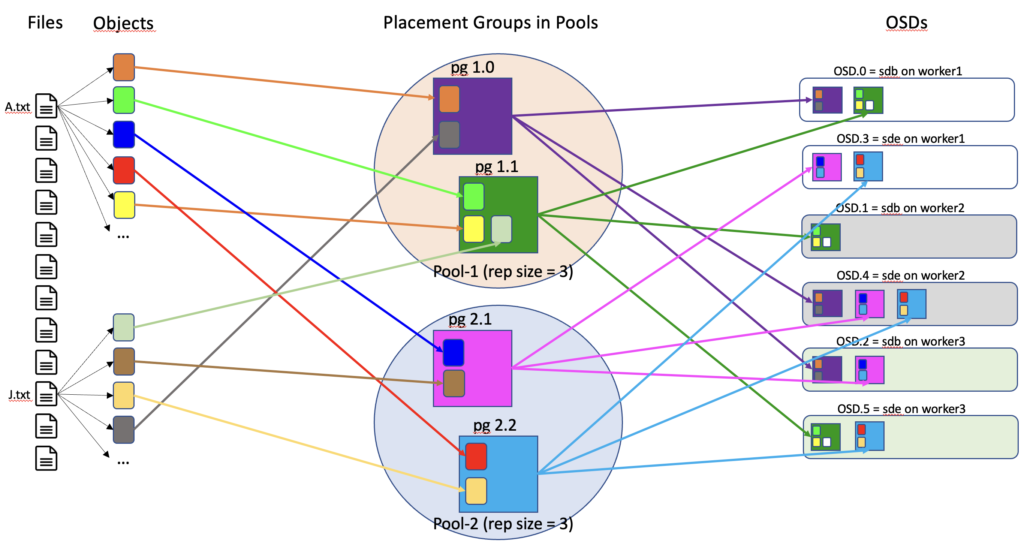
UP set được xác định bởi CRUSH map, UP set là tập hợp các OSD mà một object hoặc một phần của object sẽ được lưu trữ. UP set giúp Ceph xác định nơi để ghi dữ liệu mới, đảm bảo rằng dữ liệu được phân phối đều và hiệu quả trên tất cả các OSD.
Việc xác định UP set và Acting set được thực hiện tự động bởi thuật toán CRUSH và Ceph OSD daemon, không cần phải cấu hình thủ công.
Mỗi Placement Group (PG) trong Ceph sẽ có một Up Set và một Acting Set riêng của nó.
- Trong một số trường hợp nhất định, UP set và Acting set có thể thực hiện công việc của nhau để đảm bảo tính nhất quán và sẵn sàng của dữ liệu.
- Khi một OSD trong UP set bị hỏng, Ceph sẽ cố gắng ghi dữ liệu mới vào các OSD khác trong UP set. Nếu một yêu cầu đọc dữ liệu đến và dữ liệu đó nằm trên một OSD bị hỏng, Ceph sẽ cố gắng tìm dữ liệu đó trên các OSD khác trong UP set nếu có bản sao của dữ liệu đó.
- Khi một OSD trong Acting set bị hỏng, Ceph sẽ cố gắng đọc dữ liệu từ các OSD khác trong Acting set nếu OSD chứa dữ liệu gốc bị hỏng. Nếu một yêu cầu ghi dữ liệu đến, Ceph sẽ cố gắng ghi dữ liệu đó vào các OSD khác trong Acting set.
Vì vậy, trong những trường hợp như vậy, UP set và Acting set cùng nhau giúp Ceph duy trì tính nhất quán và sẵn sàng của dữ liệu, bằng cách cho phép Ceph ghi dữ liệu mới vào các OSD khác và đọc dữ liệu từ các OSD khác.
Trong trạng thái hoạt động bình thường của hệ thống, UP set và Acting set thường quản lý cùng một nhóm OSD. Mỗi object hoặc phần của object sẽ được lưu trữ trên cùng một tập hợp các OSD và tập hợp này được xác định bởi cả UP set và Acting set.
Tuy nhiên, trong một số trường hợp nhất định, chẳng hạn như khi một OSD bị hỏng hoặc khi đang di chuyển dữ liệu giữa các OSD, UP set và Acting set có thể khác nhau. Điều đó có nghĩa là tập hợp các OSD được chọn để lưu trữ dữ liệu mới (UP set) và tập hợp các OSD đang lưu trữ dữ liệu hiện tại (Acting set) có thể không giống nhau.
Ví dụ, giả sử bạn có một hệ thống Ceph với 5 OSD. Trong trạng thái bình thường, UP set và Acting set có thể bao gồm OSD 1, 2 và 3. Tuy nhiên, nếu OSD 2 bị hỏng, Ceph có thể quyết định di chuyển dữ liệu từ OSD 2 sang OSD 4 để đảm bảo tính nhất quán và sẵn sàng của dữ liệu. Trong trường hợp này, UP set sẽ bao gồm OSD 1, 3 và 4, trong khi Acting set vẫn bao gồm OSD 1, 2 và 3 cho đến khi việc di chuyển dữ liệu hoàn tất.
Tương tự, khi đang di chuyển dữ liệu giữa các OSD, UP set và Acting set cũng có thể khác nhau. Ví dụ, nếu bạn đang di chuyển dữ liệu từ OSD 5 sang OSD 4, UP set có thể bao gồm OSD 1, 3 và 4, trong khi Acting set bao gồm OSD 1, 3 và 5 cho đến khi việc di chuyển dữ liệu hoàn tất.
Khi chúng có vấn đề thì Ceph thường hiển thị trạng thái “HEALTH WARN” với thông báo “stuck stale”).
Bạn có thể sử dụng lệnh ceph pg dump để xem thông tin về tất cả các PG trong cluster, bao gồm cả Acting Set cho mỗi PG. Kết quả trả về sẽ bao gồm một cột “acting” mô tả Acting Set cho mỗi PG. OSD đầu tiên trong danh sách này là OSD chính.
ceph pg dumpVí dụ về đầu ra của lệnh ceph pg dump:
shell> ceph pg dump
version 345898
stamp 2024-04-12T16:03:51.044639+0700
last_osdmap_epoch 0
last_pg_scan 0
PG_STAT OBJECTS MISSING_ON_PRIMARY DEGRADED MISPLACED UNFOUND BYTES OMAP_BYTES* OMAP_KEYS* LOG LOG_DUPS DISK_LOG STATE STATE_STAMP VERSION REPORTED UP UP_PRIMARY ACTING ACTING_PRIMARY LAST_SCRUB SCRUB_STAMP LAST_DEEP_SCRUB DEEP_SCRUB_STAMP SNAPTRIMQ_LEN LAST_SCRUB_DURATION SCRUB_SCHEDULING OBJECTS_SCRUBBED OBJECTS_TRIMMED
2.7f 8845 0 0 0 0 37034606592 0 0 10040 0 10040 active+clean 2024-04-12T02:50:30.133715+0700 9392'27481647 9392:69617420 [22,13,31] 22 [22,13,31] 22 9373'27450595 2024-04-12T02:50:30.133657+0700 9373'27450595 2024-04-12T02:50:30.133657+0700 0 126 periodic scrub scheduled @ 2024-04-13T01:43:34.870339+0000 8754 0
2.7e 8877 0 0 0 0 37141450752 0 0 10015 0 10015 active+clean 2024-04-12T14:22:49.964468+0700 9392'19937259 9392:58368773 [0,15,29] 0 [0,15,29] 0 9392'19929959 2024-04-12T14:22:49.964439+0700 9392'19929959 2024-04-12T14:22:49.964439+0700 0 124 periodic scrub scheduled @ 2024-04-13T12:21:17.497230+0000 8816 0
2.38 8726 0 0 0 0 36511493650 0 0 10011 0 10011 active+clean 2024-04-11T14:02:02.592901+0700 9392'15257814 9392:54365568 [23,8,1] 23 [23,8,1] 23 9364'15219218 2024-04-11T14:02:02.592807+0700 9293'15111580 2024-04-08T19:31:57.244022+0700 0 4 periodic scrub scheduled @ 2024-04-12T18:51:11.585052+0000 8658 0
2.37 8997 0 0 0 0 37651232256 0 0 10088 0 10088 active+clean 2024-04-12T06:10:10.899550+0700 9392'32598845 9392:64628493 [16,8,24] 16 [16,8,24] 16 9380'32543580 2024-04-12T06:10:10.899473+0700 9254'32046056 2024-04-07T08:30:48.345517+0700 0 4 periodic scrub scheduled @ 2024-04-13T02:39:57.927464+0000 8921 0
<đã làm gọn bớt>
2.7a 8971 0 0 0 0 37537217536 0 0 10018 0 10018 active+clean 2024-04-11T23:30:40.478398+0700 9392'19781144 9392:42990776 [31,18,1] 31 [31,18,1] 31 9370'19733885 2024-04-11T23:30:40.478370+0700 9370'19733885 2024-04-11T23:30:40.478370+0700 0 100 periodic scrub scheduled @ 2024-04-13T00:46:32.671563+0000 8893 0
2.7b 8822 0 0 0 0 36917320742 0 0 10019 0 10019 active+clean 2024-04-11T14:46:08.024667+0700 9392'25896029 9392:79421410 [9,31,23] 9 [9,31,23] 9 9364'25853278 2024-04-11T14:46:08.024601+0700 9364'25853278 2024-04-11T14:46:08.024601+0700 0 124 periodic scrub scheduled @ 2024-04-12T16:47:15.354124+0000 8745 0
2.7c 8948 0 0 0 0 37448283136 0 0 10036 0 10036 active+clean 2024-04-12T06:05:47.011397+0700 9392'15727847 9392:46557103 [7,12,25] 7 [7,12,25] 7 9380'15708536 2024-04-12T06:05:47.011346+0700 9380'15708536 2024-04-12T06:05:47.011346+0700 0 125 periodic scrub scheduled @ 2024-04-13T04:36:00.342913+0000 8874 0
3 1122 0 0 0 0 1693699876 78458 4032 145360 145360
2 1136717 0 0 0 0 4756998628612 5472 441 1286326 1286326
1 82 0 0 0 0 338952752 0 0 10013 10013
sum 1137921 0 0 0 0 4759031281240 83930 4473 1441699 1441699
OSD_STAT USED AVAIL USED_RAW TOTAL HB_PEERS PG_SUM PRIMARY_PG_SUM
31 448 GiB 3.1 TiB 448 GiB 3.5 TiB [0,1,4,11,14,15,16,18,23,30] 14 3
30 451 GiB 3.1 TiB 451 GiB 3.5 TiB [0,1,5,6,9,13,14,18,19,20,21,22,29,31] 18 5
29 417 GiB 3.1 TiB 417 GiB 3.5 TiB [0,4,5,8,9,11,13,14,19,20,21,22,28,30] 17 6
12 520 GiB 3.0 TiB 520 GiB 3.5 TiB [2,3,4,11,13,17,18,19,20,22,23,26,27,28,29,31] 16 6
11 382 GiB 3.1 TiB 382 GiB 3.5 TiB [1,2,3,6,10,12,16,18,19,23,25,27,29,30,31] 14 4
10 381 GiB 3.1 TiB 381 GiB 3.5 TiB [2,3,5,9,11,18,21,23,26,28,31] 14 3
9 415 GiB 3.1 TiB 415 GiB 3.5 TiB [1,5,6,7,8,10,16,17,18,19,20,21,22,23,25,26,27,28,29,30,31] 17 6
<đã làm gọn bớt>
21 519 GiB 3.0 TiB 519 GiB 3.5 TiB [0,1,5,6,12,13,20,22,24,26,27,29] 18 3
22 349 GiB 3.2 TiB 349 GiB 3.5 TiB [1,3,4,5,6,9,10,12,13,14,21,23,25,30,31] 12 3
23 520 GiB 3.0 TiB 520 GiB 3.5 TiB [0,1,6,7,8,11,12,14,15,22,24,27,29] 19 7
24 280 GiB 3.2 TiB 280 GiB 3.5 TiB [0,8,9,10,13,19,20,21,22,23,25] 13 4
25 346 GiB 3.2 TiB 346 GiB 3.5 TiB [1,6,7,8,9,14,16,17,19,20,21,23,24,26] 15 7
26 277 GiB 3.2 TiB 277 GiB 3.5 TiB [0,2,9,10,16,17,18,21,25,27] 9 3
27 486 GiB 3.0 TiB 486 GiB 3.5 TiB [0,1,3,7,8,10,11,12,15,18,19,22,26,28] 21 6
28 486 GiB 3.0 TiB 486 GiB 3.5 TiB [2,3,4,5,10,12,13,18,20,27,29] 15 5
sum 13 TiB 99 TiB 13 TiB 112 TiB
* NOTE: Omap statistics are gathered during deep scrub and may be inaccurate soon afterwards depending on utilization. See http://docs.ceph.com/en/latest/dev/placement-group/#omap-statistics for further details.
dumped allTrong ví dụ trên, PG 2.7f có Acting Set là [22,13,31] và ACTING_PRIMARY là 22 vì vậy OSD chính là OSD 22.
Để xem OSD nào nằm trong Acting Set và Up Set cho một PG cụ thể, hãy chạy lệnh sau:
ceph pg map {pg-num}Kết quả xuất ra cung cấp các thông tin sau: osdmap epoch (eNNN), số PG ({pg-num}), các OSD trong Up Set (up[]) và các OSD trong Acting Set (acting[]):
osdmap eNNN pg {raw-pg-num} ({pg-num}) -> up [0,1,2] acting [0,1,2]Ví dụ:
shell> ceph pg map 2.7f
osdmap e9392 pg 2.7f (2.7f) -> up [22,13,31] acting [22,13,31]Kết quả trên cho thấy thông tin về việc lưu trữ Placement Group (PG) 2.7f trong hệ thống Ceph của bạn.
osdmap e9392: Đây là phiên bản của OSD map, một dạng bản đồ mà Ceph sử dụng để theo dõi vị trí của tất cả các OSD trong hệ thống.e9392là số phiên bản của OSD map.pg 2.7f (2.7f): Đây là ID của Placement Group (PG) mà bạn đang truy vấn. PG là một đơn vị phân phối dữ liệu trong Ceph. Mỗi PG chứa một phần của dữ liệu trong hệ thống Ceph.up [22,13,31]: Đây là UP set cho PG 2.7f. UP set là tập hợp các OSD mà Ceph dự định sử dụng để lưu trữ dữ liệu. Trong trường hợp này, Ceph dự định lưu trữ PG 2.7f trên OSD 22, 13 và 31.acting [22,13,31]: Đây là Acting set cho PG 2.7f. Acting set là tập hợp các OSD mà Ceph hiện đang sử dụng để lưu trữ dữ liệu. Trong trường hợp này, Ceph đang lưu trữ PG 2.7f trên OSD 22, 13 và 31.
Vì UP set và Acting set giống nhau, điều này cho thấy hệ thống Ceph của bạn đang hoạt động bình thường và không có OSD nào bị hỏng hoặc đang di chuyển dữ liệu.
- Lưu ý:
- Nếu Up Set và Acting Set không khớp, điều này có thể cho thấy rằng cụm đang cân bằng lại chính nó hoặc có vấn đề với cụm.
- Trực tiếp từ Ceph, bạn không thể xem được danh sách các object cụ thể đang được quản lý bởi một Placement Group (PG) cụ thể. Ceph không cung cấp công cụ hoặc lệnh để truy vấn trực tiếp thông tin này.
Peering.
Trong hệ thống Ceph, dữ liệu được chia thành các đối tượng (objects) và được lưu trữ trong các Placement Group (PG). Mỗi PG được quản lý bởi một tập hợp các OSD, được gọi là Acting Set. Trong Acting Set, OSD đầu tiên được coi là OSD chính, còn các OSD khác là OSD phụ.
Trước khi một PG có thể nhận dữ liệu để lưu trữ (tức là trước khi bạn có thể ghi dữ liệu vào một PG), PG đó phải ở trong trạng thái “hoạt động” (active). Điều này có nghĩa là tất cả các OSD trong Acting Set của PG đều phải sẵn sàng để nhận và lưu trữ dữ liệu. Ngoài ra, nếu PG đó còn ở trạng thái “sạch” (clean), điều này có nghĩa là không có dữ liệu nào đang chờ được ghi vào PG.
Để xác định trạng thái hiện tại của một PG, một quá trình gọi là “peering” phải diễn ra. Trong quá trình peering, OSD chính của PG (tức là OSD đầu tiên trong Acting Set) sẽ liên lạc với các OSD phụ trong Acting Set để đạt được sự đồng thuận về trạng thái hiện tại của PG. Nếu tất cả các OSD đều đồng ý rằng PG đang ở trạng thái Active/clean, thì PG đó sẽ được coi là sẵn sàng để nhận dữ liệu.
Ví dụ, giả sử bạn có một pool với ba bản sao của mỗi PG. Trong trường hợp này, mỗi PG sẽ có một Acting Set gồm ba OSD. Trước khi bạn có thể ghi dữ liệu vào một PG, OSD chính của PG đó phải peering với hai OSD phụ để xác định rằng PG đó đang ở trạng thái Active/clean.
Nếu một OSD trong Acting Set của một Placement Group (PG) gặp vấn đề và không hoạt động, Ceph sẽ thực hiện một quá trình gọi là “backfill” hoặc “recovery” để đảm bảo rằng dữ liệu vẫn được lưu trữ an toàn.
Trong quá trình backfill hoặc recovery, Ceph sẽ chọn một OSD khác trong hệ thống để thay thế OSD bị hỏng. Dữ liệu từ OSD bị hỏng (nếu có thể truy cập) hoặc từ các bản sao khác của dữ liệu sẽ được sao chép đến OSD mới này. Khi quá trình backfill hoặc recovery hoàn tất, PG sẽ trở lại trạng thái Active/clean và dữ liệu có thể tiếp tục được ghi vào PG.
Tuy nhiên, trong thời gian backfill hoặc recovery, việc ghi dữ liệu mới vào PG có thể bị tạm thời giới hạn hoặc ngừng lại, tùy thuộc vào cấu hình của hệ thống Ceph. Điều này giúp đảm bảo rằng dữ liệu không bị mất hoặc bị hỏng trong quá trình khắc phục sự cố.
Trong quá trình backfill hoặc recovery, dữ liệu vẫn có thể được đọc từ Placement Group (PG) nếu có yêu cầu từ client. Điều này là do Ceph lưu trữ nhiều bản sao của mỗi object, nên ngay cả khi một OSD gặp sự cố, các bản sao khác của dữ liệu vẫn có thể được truy cập.
Tuy nhiên, tốc độ đọc có thể chậm hơn bình thường do quá trình backfill hoặc recovery đang diễn ra. Ngoài ra, nếu tất cả các bản sao của một object đều bị lưu trữ trên các OSD đang gặp sự cố, thì object đó có thể không thể truy cập được cho đến khi quá trình backfill hoặc recovery hoàn tất.
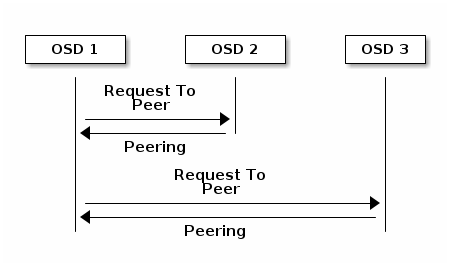
Trong quá trình lưu dữ liệu Ceph sẽ chọn một OSD làm “OSD chính” cho PG đó. OSD chính này sẽ chịu trách nhiệm ghi dữ liệu và sau đó đồng bộ hóa dữ liệu đó với các “OSD phụ”.
Các OSD cũng báo cáo trạng thái của nó cho monitor. Để biết chi tiết, xem Cấu hình Tương tác giữa Monitor/OSD. Để khắc phục sự cố peering, xem Peering Failure.
Giám sát trạng thái PG.
Nếu bạn chạy các lệnh ceph health, ceph -s, hoặc ceph -w, bạn có thể nhận thấy rằng cụm không luôn hiển thị HEALTH OK. Sau khi kiểm tra xem các OSD có đang chạy hay không, bạn cũng nên kiểm tra trạng thái của PG. Có một số tình huống liên quan đến PG-peering mà cụm sẽ KHÔNG hiển thị HEALTH OK là bình thường và dự kiến:
- Bạn vừa tạo một pool và các PG chưa peering.
- Các PG đang phục hồi.
- Bạn vừa thêm một OSD vào hoặc loại bỏ một OSD khỏi cụm.
- Bạn vừa sửa đổi bản đồ CRUSH của mình và các PG của bạn đang di chuyển.
- Có dữ liệu không nhất quán trong các bản sao khác nhau của một PG.
- Ceph đang scrub các bản sao của một PG.
- Ceph không có đủ dung lượng lưu trữ để hoàn thành các hoạt động backfilling.
Nếu một trong những tình huống này khiến Ceph hiển thị HEALTH WARN, bạn đừng quá lo lắng vì nhiều trường hợp, cụm sẽ phục hồi tự động. Tuy nhiên, trong một số trường hợp, bạn có thể cần phải kiểm tra thủ công. Một khía cạnh quan trọng của việc giám sát PG là kiểm tra trạng thái của chúng là Active/clean: tức là, quan trọng là đảm bảo rằng, khi cụm đang hoạt động, tất cả các PG đều active và (ưu tiên) clean. Để xem trạng thái của mỗi PG, hãy chạy lệnh sau:
ceph pg statKết quả xuất ra cung cấp các thông tin sau: tổng số PG (x), bao nhiêu PG ở trạng thái cụ thể như active+clean (y) và lượng dữ liệu được lưu trữ (z).
x pgs: y active+clean; z bytes data, aa MB used, bb GB / cc GB availLưu ý
Thường thì Ceph sẽ báo cáo nhiều trạng thái cho PG (ví dụ, active+clean, active+clean+remapped, active+clean+scrubbing.
Ở đây Ceph không chỉ hiển thị trạng thái PG, mà còn có dung lượng lưu trữ đã sử dụng (aa), lượng dung lượng lưu trữ còn lại (bb) và tổng dung lượng lưu trữ của PG. Những giá trị này có thể quan trọng trong một số trường hợp:
- Cụm đang gần near full ratio (gần đầy) hoặc full ratio (cụm đã đầy).
- Dữ liệu không được phân phối trên cụm do lỗi trong cấu hình CRUSH.
Ví dụ:
shell> ceph pg stat
161 pgs: 161 active+clean; 4.3 TiB data, 13 TiB used, 99 TiB / 112 TiB avail; 5.6 MiB/s rd, 1.7 MiB/s wr, 559 op/sPlacement Group IDs.
ID PG bao gồm pool-num (không phải tên pool) theo sau là một dấu chấm (.) và một số thập lục phân, đây chính là pg-id. Bạn có thể xem pool-num và tên của chúng từ đầu ra của lệnh ceph osd lspools. Ví dụ, pool đầu tiên được tạo tương ứng với số pool 1.
Một ID PG đủ điều kiện có dạng sau:
{pool-num}.{pg-id}Nó thường giống như sau:
1.1701bĐể lấy danh sách các PG, chạy lệnh sau:
ceph pg dumpĐể định dạng đầu ra theo định dạng JSON và lưu nó vào một file, chạy lệnh sau:
ceph pg dump -o {filename} --format=jsonĐể truy vấn một PG cụ thể, chạy lệnh sau:
ceph pg {poolnum}.{pg-id} queryCeph sẽ in đầu ra truy vấn theo định dạng JSON.
4. Các phần phụ sau đây mô tả chi tiết các trạng thái PG phổ biến nhất.
CREATING.
Khi bạn tạo một pool trong Ceph, bạn cần chỉ định tổng số Placement Groups (PGs) cho pool đó. Số lượng PGs này phụ thuộc vào kích thước của cluster và cấu hình của bạn. Mỗi PG sẽ được lưu trữ trên một tập hợp các OSD, được gọi là Acting Set.
Khi pool được tạo, Ceph sẽ tạo tất cả các PGs cho pool đó. Trong quá trình này, Ceph sẽ hiển thị trạng thái ‘creating’ cho mỗi PG. Điều này chỉ đơn giản là nghĩa là PG đang được tạo.

Sau khi mỗi PG được tạo, các OSD trong Acting Set của PG đó sẽ thực hiện một quá trình gọi là “peering”. Trong quá trình peering, OSD chính (OSD đầu tiên trong Acting Set) sẽ liên lạc với các OSD phụ trong Acting Set để đạt được sự đồng thuận về trạng thái hiện tại của PG.
Một khi quá trình peering hoàn tất, trạng thái của PG sẽ trở thành ‘active+clean’. Trạng thái ‘active’ có nghĩa là PG đang hoạt động và sẵn sàng để nhận dữ liệu. Trạng thái ‘clean’ có nghĩa là không có dữ liệu nào đang chờ để được ghi vào PG. Khi một PG ở trạng thái ‘active+clean’, các client Ceph có thể bắt đầu ghi dữ liệu vào PG đó.
PEERING.
Khi một Placement Group (PG) trong Ceph đồng bộ, các OSD (Object Storage Daemons) lưu trữ các bản sao của dữ liệu của nó đồng thuận về trạng thái của dữ liệu và metadata trong PG đó. Điều này có nghĩa là tất cả các OSD đều đồng ý về trạng thái hiện tại của PG, bao gồm cả dữ liệu và metadata.
Khi một client thực hiện một hoạt động ghi, Ceph sẽ không xác nhận hoạt động ghi đó với client cho đến khi dữ liệu đã được lưu trữ bởi mỗi OSD trong Acting Set (tập hợp các OSD mà Ceph hiện đang sử dụng để lưu trữ dữ liệu cho PG đó). Điều này đảm bảo rằng ít nhất một thành viên của Acting Set sẽ có một hồ sơ về mỗi hoạt động ghi được xác nhận kể từ lần đồng bộ thành công cuối cùng. Điều này có nghĩa là, mặc dù một PG có thể đã hoàn thành quá trình đồng bộ, nhưng nếu một hoạt động ghi mới được thực hiện sau đó, thì có thể không phải tất cả các OSD trong Acting Set đều có bản sao mới nhất của dữ liệu. Chỉ khi hoạt động ghi đó đã được lưu trữ bởi tất cả các OSD trong Acting Set, Ceph mới xác nhận hoạt động ghi đó với client.
Ví dụ có một file lớn như 1TB sẽ được chia thành nhiều object nhỏ hơn để lưu trữ. Kích thước của mỗi object phụ thuộc vào cấu hình của hệ thống, nhưng thường là trong khoảng từ vài MB đến vài GB.
Khi một object được ghi vào OSD chính, nó sẽ được đồng bộ hóa với các OSD phụ trong Acting Set. Quá trình này diễn ra song song với việc ghi các object khác, nên ngay cả khi bạn đang ghi một file lớn, bạn vẫn có thể nhận được phản hồi từ Ceph trong thời gian tương đối ngắn.
Với một hồ sơ chính xác về mỗi hoạt động ghi được xác nhận, Ceph có thể xây dựng một lịch sử mới có thẩm quyền của PG. Điều này có nghĩa là Ceph có thể tạo ra một tập hợp hoàn chỉnh và hoàn toàn được sắp xếp của các hoạt động mà nếu thực hiện nó sẽ cập nhật bản sao của OSD của PG. Điều này giúp đảm bảo tính nhất quán và độ tin cậy của dữ liệu trong Ceph.
ACTIVE.
Trạng thái “active” của một Placement Group (PG) trong Ceph có nghĩa là PG đó đang hoạt động và sẵn sàng để nhận dữ liệu.
Khi Ceph hoàn thành quá trình peering, một PG sẽ ở trạng thái hoạt động. Quá trình peering là quá trình mà các OSD trong Acting Set (tập hợp các OSD mà Ceph hiện đang sử dụng để lưu trữ dữ liệu cho PG đó) liên lạc với nhau để đạt được sự đồng thuận về trạng thái hiện tại của PG.
Khi một PG ở trạng thái “active”, dữ liệu trong PG đó nói chung có sẵn cho các hoạt động đọc và ghi. Điều này có nghĩa là các client có thể đọc dữ liệu từ PG đó và ghi dữ liệu vào PG đó. Các hoạt động đọc và ghi này được thực hiện trên các OSD chính và phụ, tùy thuộc vào cấu hình của Ceph và trạng thái của các OSD.
CLEAN.
Trạng thái “clean” của một Placement Group (PG) trong Ceph có nghĩa là tất cả các OSD (Object Storage Daemons) chứa dữ liệu và metadata của PG đó đã hoàn thành quá trình peering thành công và không có bản sao nào lạc hậu.
Quá trình peering là quá trình mà các OSD trong Acting Set (tập hợp các OSD mà Ceph hiện đang sử dụng để lưu trữ dữ liệu cho PG đó) liên lạc với nhau để đạt được sự đồng thuận về trạng thái hiện tại của PG.
Khi một PG ở trạng thái “clean”, điều này cũng có nghĩa là Ceph đã sao chép tất cả các đối tượng trong PG đúng số lần theo cấu hình. Ví dụ, nếu bạn cấu hình Ceph để sao chép mỗi đối tượng 3 lần, thì khi một PG ở trạng thái “clean”, mỗi đối tượng trong PG đó sẽ được sao chép 3 lần trên các OSD khác nhau.
DEGRADED.
Trạng thái hạ cấp (Degraded State): Một PG chuyển vào trạng thái Degraded State khi không phải tất cả các bản sao của một đối tượng đều được cập nhật. Điều này có thể xảy ra, ví dụ khi một client ghi một đối tượng vào OSD chính và OSD chính chịu trách nhiệm sao chép đối tượng đó vào các OSD phụ. PG sẽ ở trong trạng thái Degraded State cho đến khi OSD chính nhận được xác nhận từ các OSD phụ rằng họ đã tạo thành công các bản sao của đối tượng.
Trạng thái active+degraded: Một PG có thể ở trong trạng thái active+degraded nếu một OSD đang hoạt động nhưng không giữ tất cả các đối tượng của PG. Nếu một OSD gặp sự cố, Ceph sẽ đánh dấu mỗi PG được gán cho OSD là Degraded State. Các PG phải thực hiện peering lại khi OSD trở lại online. Tuy nhiên, một client vẫn có thể ghi một đối tượng mới vào một PG Degraded State nếu nó đang hoạt động.
Remapping: Nếu một OSD gặp sự cố và trạng thái Degraded State kéo dài, Ceph có thể đánh dấu OSD loại bỏ OSD này khỏi cụm và remap dữ liệu từ OSD gặp sự cố đến OSD khác. Thời gian giữa việc được đánh dấu gặp sự cố và được đánh dấu loại bỏ OSD này khỏi cụm được xác định bởi mon_osd_down_out_interval, mặc định là 600 giây.
Đối tượng bị thiếu (Missing Objects): Một PG cũng có thể ở trong trạng thái Degraded State nếu có một hoặc nhiều đối tượng mà Ceph mong đợi tìm thấy trong PG nhưng không thể tìm thấy. Mặc dù bạn không thể đọc hoặc ghi vào các đối tượng bị thiếu, bạn vẫn có thể truy cập tất cả các đối tượng khác trong PG Degraded State. Trong trường hợp một đối tượng bị thiếu, Ceph sẽ không tự động tạo ra một đối tượng mới ở OSD khác. Thay vào đó, Ceph sẽ cố gắng khôi phục đối tượng bị thiếu từ các bản sao khác (nếu có) hoặc từ lịch sử ghi dữ liệu (nếu có).
RECOVERING.
Khi một OSD (Object Storage Daemon – tiến trình lưu trữ đối tượng) gặp sự cố, dữ liệu trên đó có thể bị cũ so với các bản sao khác trong PG (Placement Group – nhóm đặt). Khi OSD hoạt động trở lại, nội dung của PG cần được cập nhật để phản ánh trạng thái hiện tại của cụm. Trong thời gian này, OSD có thể ở trong trạng thái đang phục hồi.
Việc phục hồi không phải lúc nào cũng đơn giản, đặc biệt khi có lỗi phần cứng liên tiếp ảnh hưởng đến nhiều OSD. Ví dụ, nếu một storage switch gặp sự cố, dữ liệu trên nhiều OSD có thể bị cũ so với trạng thái hiện tại của cụm. Trong trường hợp này, việc phục hồi chỉ có thể thực hiện được khi mỗi OSD phục hồi sau khi lỗi đã được giải quyết.
- Ceph cung cấp một số cài đặt để điều chỉnh cách cụm xử lý việc cân nhắc giữa việc xử lý yêu cầu dịch vụ mới và việc phục hồi dữ liệu. Các cài đặt này bao gồm:
osd_recovery_delay_start: Cài đặtosd_recovery_delay_startcho phép OSD có thời gian để thực hiện các hoạt động này trước khi bắt đầu quá trình phục hồi dữ liệu. Điều này giúp đảm bảo rằng OSD có thể tiếp tục xử lý các yêu cầu mới mà không cần phải chờ đợi quá trình phục hồi hoàn tất.osd_recovery_thread_timeout: Cài đặtosd_recovery_thread_timeoutcho phép bạn xác định thời gian chờ tối đa cho một luồng phục hồi. Nếu một luồng phục hồi không hoàn thành công việc của mình trong thời gian này, nó sẽ bị gián đoạn và công việc của nó sẽ được chuyển cho một luồng phục hồi khác. Điều này giúp đảm bảo rằng quá trình phục hồi dữ liệu không bị chậm trễ quá lâu do một luồng phục hồi bị “kẹt”.osd_recovery_max_active: Giới hạn số lượng yêu cầu phục hồi mà một OSD có thể xử lý đồng thời. Mục đích của cài đặt này là để ngăn chặn OSD từ việc bị quá tải do xử lý quá nhiều yêu cầu phục hồi cùng một lúc, điều này có thể làm giảm hiệu suất của OSD và ảnh hưởng đến khả năng phục vụ các yêu cầu khác.osd_recovery_max_chunk: Giới hạn kích thước của các khối dữ liệu được phục hồi. Mục đích của cài đặt này là để ngăn chặn tắc nghẽn mạng do việc truyền tải các khối dữ liệu quá lớn trong quá trình phục hồi. Bằng cách giới hạn kích thước của các khối dữ liệu, Ceph có thể đảm bảo rằng quá trình phục hồi không gây ra tắc nghẽn mạng và ảnh hưởng đến hiệu suất của cụm.
BACK FILLING.
Khi một OSD (Object Storage Daemon) mới được thêm vào cụm, hệ thống CRUSH sẽ phân chia lại PGs (Placement Groups) từ các OSD hiện có sang OSD mới. Điều này có thể tạo ra áp lực lớn cho OSD mới, vì nó phải chấp nhận nhiều PGs ngay lập tức. Quá trình “backfill” cho phép việc này diễn ra một cách từ từ, giúp giảm áp lực cho OSD mới.
Trong quá trình “backfill”, có thể có nhiều trạng thái khác nhau. “backfill_wait” nghĩa là quá trình “backfill” đang chờ đợi để bắt đầu. “backfilling” nghĩa là quá trình “backfill” đang diễn ra. “backfill_toofull” nghĩa là quá trình “backfill” không thể hoàn thành do không đủ dung lượng lưu trữ.
Ceph cung cấp một số cài đặt để quản lý việc tăng tải khi phân chia lại PGs cho một OSD. Ví dụ, “osd_max_backfills” xác định số lượng tối đa của các hoạt động “backfill” đồng thời. “backfill_full_ratio” cho phép một OSD từ chối một yêu cầu “backfill” nếu OSD đang gần đầy. “osd_backfill_retry_interval” cho phép một OSD thử lại yêu cầu “backfill” sau một khoảng thời gian nhất định.
REMAPPED.
Khi tập hợp các OSD (Object Storage Daemon) phục vụ một PG (Placement Group) thay đổi, dữ liệu cần được di chuyển từ tập hợp OSD cũ sang tập hợp OSD mới. Điều này có thể mất một thời gian nhất định.
Trong quá trình di chuyển dữ liệu, OSD chính cũ có thể được yêu cầu tiếp tục phục vụ các yêu cầu cho PG, để đảm bảo rằng dịch vụ không bị gián đoạn.
Sau khi quá trình di chuyển dữ liệu hoàn tất, PG sẽ được ánh xạ để sử dụng OSD chính mới từ tập hợp OSD mới. Điều này nghĩa là, từ thời điểm này trở đi, tất cả các yêu cầu đến PG sẽ được phục vụ bởi OSD chính mới.
STALE.
Ceph sử dụng cơ chế “heartbeat” để kiểm tra xem các host và daemons có đang hoạt động hay không. Tuy nhiên, trong một số trường hợp, các daemons ceph-osd có thể rơi vào trạng thái “bị kẹt”, nơi mà chúng không thể gửi các báo cáo thống kê kịp thời. Điều này có thể xảy ra do một số lỗi mạng tạm thời.
Theo mặc định, các daemons OSD sẽ gửi báo cáo về PG (Placement Group), trạng thái khởi động và các thống kê lỗi của chúng mỗi nửa giây. Đây là tần suất gửi báo cáo thường xuyên hơn so với các báo cáo được xác định bởi các ngưỡng “heartbeat”.
Nếu OSD chính của một PG không gửi báo cáo cho monitor hoặc nếu các OSD khác đã báo cáo rằng OSD chính đã ngừng hoạt động, thì monitor sẽ đánh dấu PG là “stale” (cũ, không còn cập nhật).
Đây là cách bạn có thể xử lý tình huống này:
- Kiểm tra trạng thái của các OSD: Sử dụng lệnh
ceph osd treeđể xem trạng thái của tất cả các OSD trong cụm. Nếu có OSD nào đang ở trạng thái down, hãy thử khởi động lại chúng. - Kiểm tra lỗi mạng: Lỗi mạng tạm thời có thể ngăn OSD gửi báo cáo trạng thái. Kiểm tra cấu hình mạng và đảm bảo rằng tất cả các OSD đều có thể liên lạc với monitor.
- Kiểm tra tài nguyên hệ thống: Nếu một OSD không có đủ tài nguyên (như CPU, bộ nhớ, hoặc băng thông mạng), nó có thể không thể gửi báo cáo trạng thái kịp thời. Sử dụng các công cụ như
top,freevàiftopđể kiểm tra tài nguyên hệ thống. - Kiểm tra log của OSD: Log của OSD có thể cung cấp thông tin chi tiết về vì sao nó không gửi báo cáo trạng thái. Bạn có thể tìm log của OSD trong thư mục
/var/log/ceph. - Sử dụng lệnh
ceph pg repair: Nếu một PG bị hỏng, bạn có thể sử dụng lệnhceph pg repair <pgid>để cố gắng sửa chữa nó. Hãy lưu ý rằng lệnh này chỉ nên được sử dụng như một biện pháp cuối cùng, vì nó có thể gây ra mất dữ liệu.
Xác định sự cố PGS.
Khi một client ghi một đối tượng vào OSD (Object Storage Daemon) chính, OSD chính chịu trách nhiệm ghi các bản sao vào các OSD phụ. Sau khi OSD chính ghi đối tượng vào bộ nhớ, PG (Placement Group) sẽ ở trong trạng thái “degraded” (hạ cấp) cho đến khi OSD chính nhận được xác nhận từ các OSD phụ rằng Ceph đã tạo thành công các đối tượng bản sao.
Một PG có thể ở trạng thái “active+degraded” vì một OSD có thể hoạt động ngay cả khi nó chưa giữ tất cả các đối tượng của PG. Nếu một OSD bị hỏng, Ceph sẽ đánh dấu mỗi PG được gán cho OSD là “degraded”. Các PG phải thực hiện quá trình “peering” lại khi OSD trở lại online. Tuy nhiên, một client vẫn có thể ghi một đối tượng mới vào một PG “degraded” nếu nó đang hoạt động.
Nếu một OSD bị hỏng và tình trạng “degraded” kéo dài, Ceph có thể đánh dấu OSD hỏng như ngoài cụm và di chuyển dữ liệu từ OSD hỏng đến OSD khác. Thời gian giữa việc được đánh dấu hỏng và được đánh dấu ra ngoài được xác định bởi “mon_osd_down_out_interval”, mặc định được đặt là 600 giây.
Một PG cũng có thể ở trong trạng thái “degraded” vì có một hoặc nhiều đối tượng mà Ceph mong đợi tìm thấy trong PG nhưng Ceph không thể tìm thấy. Mặc dù bạn không thể đọc hoặc ghi vào các đối tượng không tìm thấy, bạn vẫn có thể truy cập tất cả các đối tượng khác trong PG “degraded”.
Để xác định PGs bị kẹt, hãy chạy lệnh sau:
ceph pg dump_stuck [unclean|inactive|stale|undersized|degraded]Để biết thêm chi tiết, xem Hệ thống nhóm đặt. Để khắc phục sự cố PGs bị kẹt, xem Khắc phục sự cố PG.
Tìm vị trí của Object.
- Để lưu trữ dữ liệu đối tượng trong Ceph Object Store, một client Ceph phải:
- Đặt tên cho đối tượng
- Chỉ định một pool
- Đây là quy trình mà Ceph sử dụng để xác định vị trí lưu trữ của một đối tượng trong hệ thống:
- Client Ceph lấy bản đồ cluster mới nhất: Bản đồ cluster chứa thông tin về cấu trúc và trạng thái của cụm Ceph, bao gồm các OSD, các pool và các PG.
- Thuật toán CRUSH tính toán cách ánh xạ đối tượng đến một PG: CRUSH (Controlled Replication Under Scalable Hashing) là thuật toán mà Ceph sử dụng để xác định vị trí lưu trữ của mỗi đối tượng. CRUSH nhận vào tên đối tượng và tên pool và trả về ID của PG mà đối tượng nên được lưu trữ.
- Thuật toán CRUSH tính toán cách gán động PG đến một OSD: Sau khi xác định được PG, CRUSH tiếp tục xác định OSD nào sẽ chứa PG đó.
Để tìm vị trí của một đối tượng chỉ với tên đối tượng và tên pool, bạn có thể chạy một lệnh có dạng sau:
ceph osd map {poolname} {object-name} [namespace]Bài tập xác định vị trí của một đối tượng.
Hãy tạo một đối tượng, chúng ta có thể chỉ định tên đối tượng, một đường dẫn đến một file chứa một số dữ liệu đối tượng và tên pool bằng cách sử dụng lệnh rados put trên dòng lệnh. Ví dụ:
rados put {object-name} {file-path} --pool=data
rados put test-object-1 testfile.txt --pool=dataĐể xác nhận rằng Ceph Object Store đã lưu trữ đối tượng, chạy lệnh sau:
rados -p data lsĐể xác định vị trí của đối tượng, chạy các lệnh sau:
ceph osd map {pool-name} {object-name}
ceph osd map data test-object-1Ceph sẽ xuất ra vị trí của đối tượng. Ví dụ:
osdmap e537 pool 'data' (1) object 'test-object-1' -> pg 1.d1743484 (1.4) -> up ([0,1], p0) acting ([0,1], p0)Để xóa đối tượng, chỉ cần xóa nó bằng cách chạy lệnh rados rm. Ví dụ:
rados rm test-object-1 --pool=dataMột trong những tính năng chính của Ceph là khả năng tự động cân bằng tải, tức là nó có thể tự động phân phối dữ liệu trên các máy chủ để đảm bảo rằng không có máy chủ nào bị quá tải.
Khi bạn thêm hoặc xóa một máy chủ từ cụm Ceph, Ceph sẽ tự động di chuyển dữ liệu giữa các máy chủ để cân bằng tải. Điều này có nghĩa là vị trí của một đối tượng (một đơn vị dữ liệu trong Ceph) có thể thay đổi theo thời gian.
Lợi ích của việc cân bằng tự động này là nó giảm bớt gánh nặng thực hiện di chuyển dữ liệu một cách thủ công. Thay vì phải quản lý vị trí của từng đối tượng, bạn chỉ cần quản lý số lượng máy chủ trong cụm và để Ceph tự động quản lý vị trí của các đối tượng.
