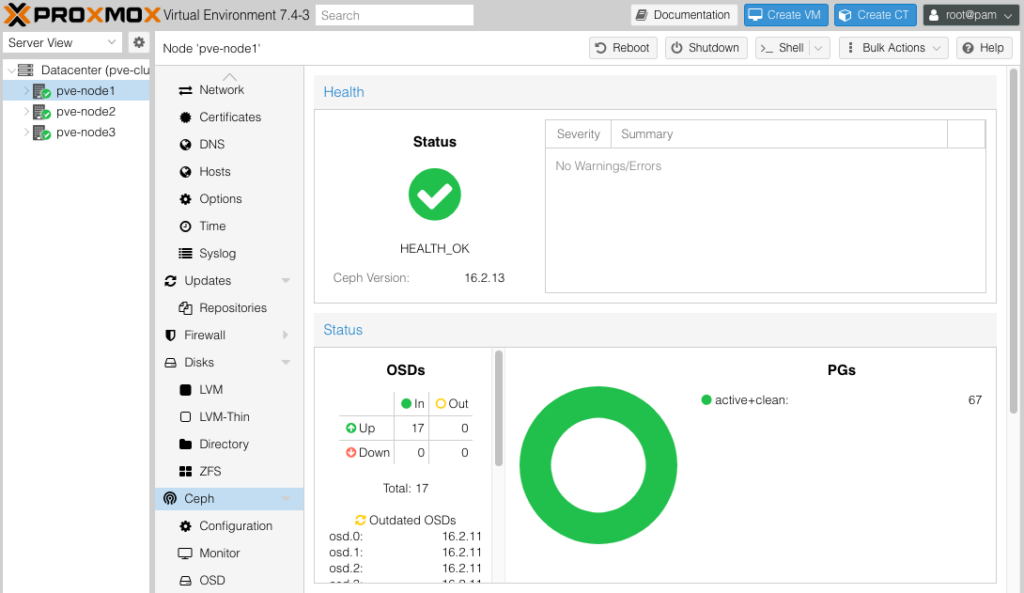
Hôm nay trong lúc làm CephFS tôi vô ý làm cho nó lỗi “error connecting to the cluster”.
Cụ thể thông báo lỗi của nó nếu bạn show bất kỳ lệnh nào liên quan đến kết nối Cluster của Ceph trên CLI như sau:
$ ceph -s
unable to get monitor info from DNS SRV with service name: ceph-mon
2023-06-06T12:09:34.167+0700 7f927fea1700 -1 failed for service _ceph-mon._tcp
2023-06-06T12:09:34.167+0700 7f927fea1700 -1 monclient: get_monmap_and_config cannot identify monitors to contact
[errno 2] RADOS object not found (error connecting to the cluster)Hoặc nếu bạn sử dụng Ceph Proxmox, trên GUI bạn sẽ nhận được thông báo:
– Lỗi khi bạn bấm vào xem Ceph Status.
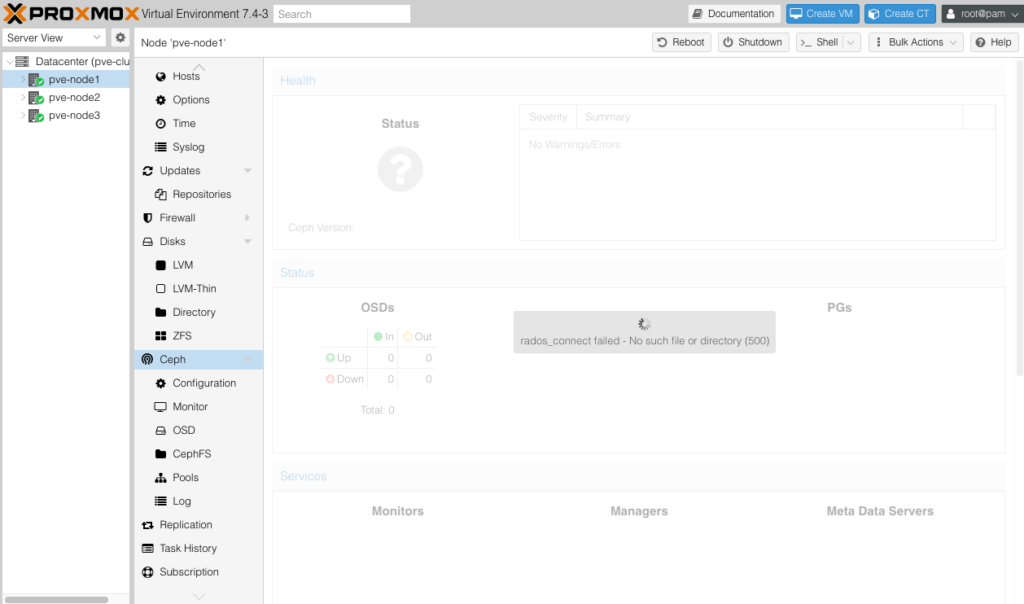
Lỗi không thế thấy các Node Manager và Monitor thì bạn không thấy thông tin cũng như trạng thái của nó.
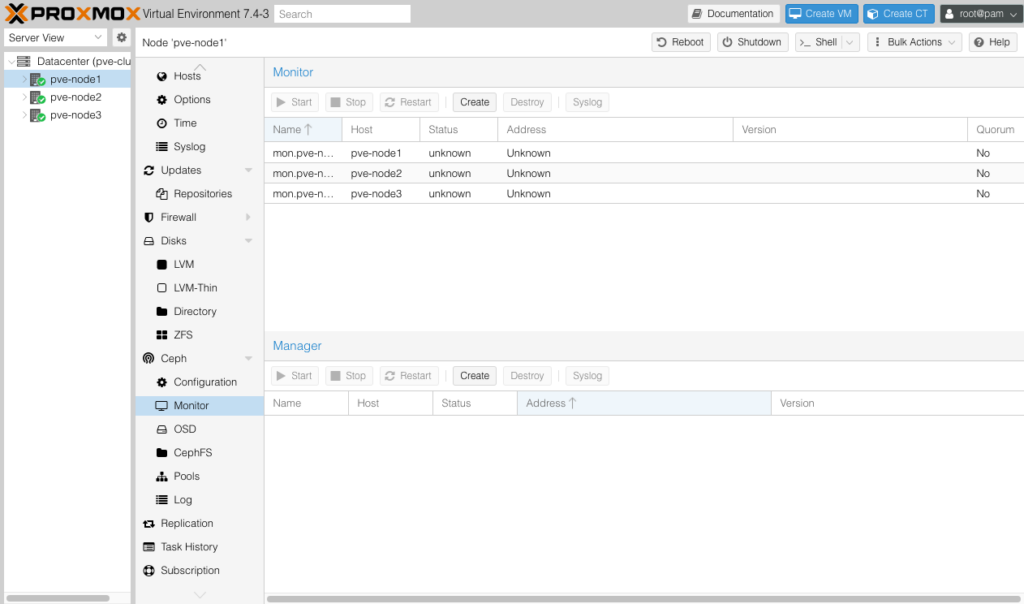
Ở phần OSD bạn không thấy một ODS nào được hiển thị.
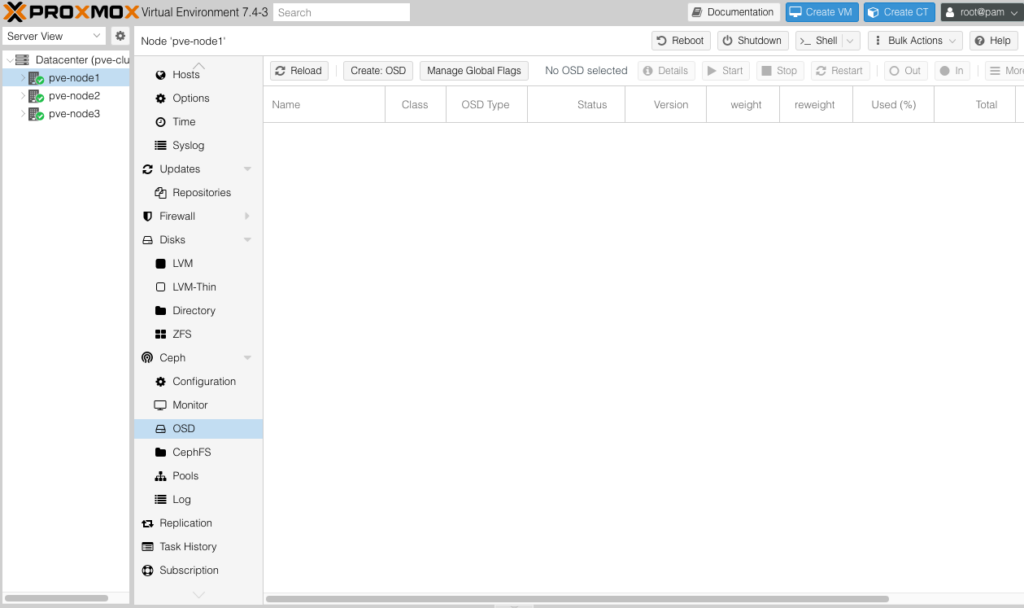
Tương tự Pools cũng vậy.
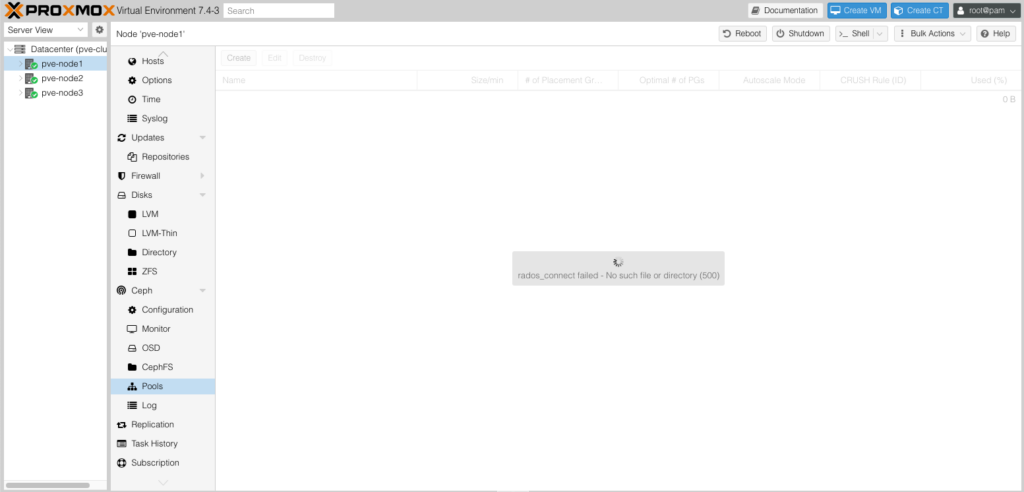
Nhưng rất may là các OSD vẫn đang hoạt động bình thường nên hệ thống không bị sập.
Vậy lý do lỗi này là gì và làm sao để chúng ta lấy lại được trạng thái Cluster.
Qua kiểm tra thì lỗi đơn giản do mình làm hỏng file ceph.conf nên hệ thống không thể kết nối đến cluster để lấy thông tin. Điều này dẫn đến chúng ta không thể mount Ceph vào bất kỳ client nào và cũng không thể thực hiện thêm bớt (osd, mds,…).
$ tree /etc/ceph/
/etc/ceph/
├── ceph.client.admin.keyring
├── ceph.client.cephfs.keyring
├── ceph.client.hoanghd.keyring
├── ceph.conf -> /etc/pve/ceph.conf
└── rbdmap
0 directories, 5 filesKinh nghiệm là bạn nên backup file ceph.conf này và lưu nó ở một nơi nào đó để lỡ vô tình nó bị hỏng hay vô tình xoá hay chỉnh sửa nó dẫn đến bị lỗi thì bạn có thể khôi phục lại nó. Và dưới đây là file ceph.conf của mình.
Bạn chỉ cần copy vào một node bất kỳ và Ceph tự động đồng bộ sang các Node khác trong cluster.
[global]
auth_client_required = cephx
auth_cluster_required = cephx
auth_service_required = cephx
cluster_network = 10.0.0.225/24
fsid = 1d447334-e065-4745-b494-99bc76c7dff8
mon_allow_pool_delete = true
mon_host = 192.168.13.226 192.168.13.225 192.168.13.227
ms_bind_ipv4 = true
ms_bind_ipv6 = false
osd_pool_default_min_size = 2
osd_pool_default_size = 3
public_network = 192.168.13.225/23
[client]
keyring = /etc/pve/priv/$cluster.$name.keyring
[mon.pve-node1]
public_addr = 192.168.13.225
[mon.pve-node2]
public_addr = 192.168.13.226
[mon.pve-node3]
public_addr = 192.168.13.227Bạn không cần phải restart lại dịch vụ gì cả, Ceph luôn luôn quét file này khi nó cần và đây là kết quả.
$ ceph -s
cluster:
id: 1d447334-e065-4745-b494-99bc76c7dff8
health: HEALTH_OK
services:
mon: 3 daemons, quorum pve-node2,pve-node1,pve-node3 (age 2d)
mgr: pve-node2(active, since 6d), standbys: pve-node3, pve-node1
mds: 1/1 daemons up
osd: 17 osds: 17 up (since 2d), 17 in (since 10d)
data:
volumes: 1/1 healthy
pools: 5 pools, 67 pgs
objects: 20.14k objects, 74 GiB
usage: 229 GiB used, 15 TiB / 15 TiB avail
pgs: 67 active+clean
io:
client: 73 MiB/s rd, 142 KiB/s wr, 117 op/s rd, 13 op/s wrTrên GUI của Proxmox.