1. Tổng quan.
Ceph trên container sẽ sử dụng các container để chạy các dịch vụ Ceph như OSDs, MONs, MGRs, v.v. trong các container Docker hoặc Podman thay vì trực tiếp trên máy chủ.

Có một số lợi ích khi triển khai Ceph trên container:
- Đóng gói: Các container cung cấp một môi trường đóng gói, giúp đảm bảo rằng các dịch vụ Ceph chạy trong một môi trường cô lập và có thể kiểm soát được.
- Tính di động: Các container có thể chạy trên bất kỳ máy chủ nào hỗ trợ Docker hoặc Podman, giúp dễ dàng di chuyển các dịch vụ Ceph giữa các máy chủ.
- Tự động hóa: Các công cụ như Kubernetes và OpenShift cung cấp khả năng tự động hóa việc triển khai và quản lý các container, giúp dễ dàng mở rộng và quản lý cụm Ceph.
- Cập nhật và quản lý phiên bản: Các container giúp dễ dàng cập nhật và quản lý phiên bản của các dịch vụ Ceph.
Ceph cung cấp hai công cụ chính để triển khai Ceph trên container: cephadm và Rook.
- cephadm là một công cụ mới trong Ceph giúp triển khai và quản lý cụm Ceph trên các container Docker hoặc Podman. Cephadm cung cấp một giao diện dòng lệnh để quản lý cụm Ceph và hỗ trợ tự động hóa nhiều tác vụ quản lý.
- Rook là một dự án mã nguồn mở giúp triển khai, quản lý và mở rộng cụm Ceph trên Kubernetes. Rook cung cấp một Custom Resource Definition (CRD) cho Kubernetes để quản lý cụm Ceph và các dịch vụ liên quan.
2. Sơ đồ LAB.
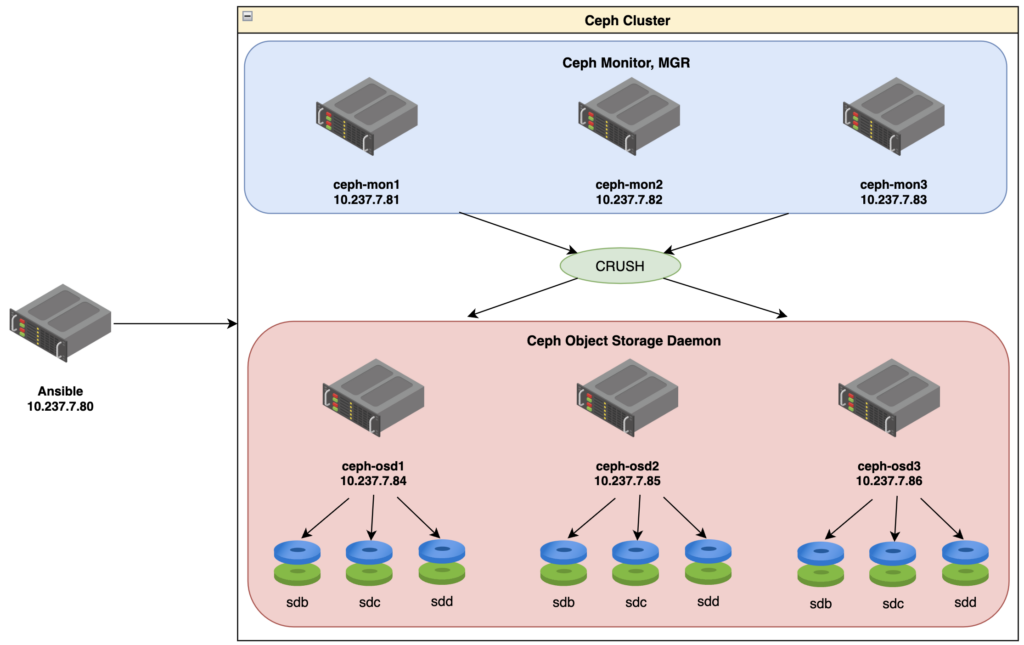
3. Triển khai môi trường và các thành phần cơ bản.
Vì mình chạy lệnh theo dạng shell nên trước khi triển khai bạn hãy chạy các biến sau.
registries_ipaddr='10.237.7.81'
generate_new_sshkey=true
your_username='hoanghd'
SITE_NAME="SITE_NAME"
CLUSTER_NAME="CLUSTER_NAME"
declare -A hosts
hosts=(
["10.237.7.81"]="ceph-mon1"
["10.237.7.82"]="ceph-mon2"
["10.237.7.83"]="ceph-mon3"
["10.237.7.84"]="ceph-osd1"
["10.237.7.85"]="ceph-osd2"
["10.237.7.86"]="ceph-osd3"
["10.237.7.87"]="ceph-osd4"
)
your_private_key='''PRIVATE KEY'''
your_public_key='''PUBLIC KEY'''3.1. Triển khai Ansible Node.
Cài đặt Ansible và các thành phần bổ sung cho việc triển khai Ceph trên Ansible Node.
# List of packages to check and install if not present
packages=("ansible" "python3-apt" "sshpass")
for package in "${packages[@]}"; do
if ! dpkg -s $package >/dev/null 2>&1; then
apt install $package -y
fi
doneTrỏ file host thông tin các Node cho Ansible Node.
declare -A hosts
hosts=(
["10.237.7.81"]="ceph-mon1"
["10.237.7.82"]="ceph-mon2"
["10.237.7.83"]="ceph-mon3"
["10.237.7.84"]="ceph-osd1"
["10.237.7.85"]="ceph-osd2"
["10.237.7.86"]="ceph-osd3"
["10.237.7.87"]="ceph-osd4"
)
sed -i '/^127.0.1.1/s/^/#/' /etc/hosts
for ip in "${!hosts[@]}"; do
host=${hosts[$ip]}
if ! grep -q "$ip $host" /etc/hosts; then
echo "$ip $host" >> /etc/hosts
fi
doneKhởi tạo sshkey.
your_username='hoanghd'
if [ "$generate_new_sshkey" = false ]; then
# Check if ssh keys exist
if [ ! -f /home/${your_username}/.ssh/id_rsa ] || [ ! -f /home/${your_username}/.ssh/id_rsa.pub ]; then
# Generate ssh key
mkdir -p /home/${your_username}/.ssh
chown ${your_username}:${your_username} /home/${your_username}/.ssh/*
chown -R ${your_username}:${your_username} /home/${your_username}/
chmod -R 700 /home/${your_username}/
ssh-keygen -t rsa -b 2048 -f /home/${your_username}/.ssh/id_rsa -N ""
chown ${your_username}:${your_username} /home/${your_username}/.ssh/*
chmod 600 /home/${your_username}/.ssh/*
fi
else
cat > /home/${your_username}/.ssh/id_rsa << 'OEF'
<private key>
OEF
cat > /home/${your_username}/.ssh/authorized_keys << 'OEF'
<public key>
OEFTạo file ansible.cfg tại thư mục gốc của playbook Ansible với nội dung dưới để bỏ qua bước xác nhận remote vào thiết bị mới.
cat > ./ansible.cfg << 'OEF'
[defaults]
host_key_checking = False
OEF3.2. Triển khai Docker registry.
Hãy chọn 1 node Ceph Mon làm Docker registry, ví dụ của mình sẽ chọn ceph-mon1.
3.2.1 Cài đặt Podman.
Podman là một công cụ quản lý container mã nguồn mở được phát triển bởi Red Hat. Nó cung cấp một giao diện dòng lệnh giống với Docker, nhưng có một số khác biệt quan trọng:
- Không có daemon: Docker sử dụng mô hình client-server, trong đó Docker daemon chạy như một quy trình nền và xử lý tất cả các yêu cầu từ Docker client. Ngược lại, Podman không sử dụng daemon. Mỗi lệnh Podman chạy như một quy trình riêng biệt và không cần tới quy trình nền.
- Podman được thiết kế để có thể chạy mà không cần quyền root: Docker yêu cầu quyền root để chạy, hoặc bạn phải thêm người dùng vào nhóm docker, điều này có thể gây ra các vấn đề về bảo mật. Podman được thiết kế để có thể chạy mà không cần quyền root, giúp giảm thiểu rủi ro bảo mật.
- Tích hợp với systemd: Podman có thể tạo và quản lý các container như các dịch vụ systemd, giúp dễ dàng quản lý và tự động khởi động các container.
- Pods: Podman hỗ trợ khái niệm “pods”, một nhóm các container chia sẻ một số tài nguyên, tương tự như trong Kubernetes. Docker không hỗ trợ pods.
Để cài đặt Podman hãy chạy các lệnh sau:
packages=("podman")
for package in "${packages[@]}"; do
if ! dpkg -s $package >/dev/null 2>&1; then
apt-get update
apt install $package -y
fi
doneTạo file /etc/containers/registries.conf và thêm các thông tin cấu hình như sau:
cat > /etc/containers/registries.conf <<OEF
[[registry]]
location="${registries_ipaddr}:5000"
insecure=true
OEF
systemctl restart podmanCấu hình này sẽ thêm một registry không an toàn (insecure) với địa chỉ IP 10.237.7.80 và port 5000 vào /etc/containers/registries.conf. Điều này có nghĩa là khi Podman tìm kiếm các image container, nó sẽ cũng tìm kiếm trên registry này.
Các thông số cụ thể:
location: Địa chỉ của registry. Trong trường hợp này, nó là10.237.7.80:5000.insecure: Nếu đặt làtrue, container runtime sẽ kết nối với registry mà không kiểm tra chứng chỉ SSL. Điều này hữu ích khi sử dụng các registry tự ký hoặc các registry không sử dụng SSL.
3.2. Triển khai Registry container.
Chạy các lệnh sau để run Registry container trên 1 Ceph Mon bất kỳ, trường hợp của mình sẽ chạy trên ceph-mon1 như đã lựa chọn.
# start registry
if ! podman ps -a | grep -q 'registry'; then
mkdir -p /var/lib/registry
podman pull registry:2
podman run --privileged -d \
--name registry \
-p 5000:5000 \
-v /var/lib/registry:/var/lib/registry \
--restart=always \
registry:2
fi3.2.2. Tạo Private Registry.
Sử dụng podman pull để tải về các Docker image từ các Docker registry.
podman pull quay.io/ceph/ceph:v17.2.6
podman pull quay.io/prometheus/prometheus:v2.33.4
podman pull docker.io/grafana/loki:2.4.0
podman pull docker.io/grafana/promtail:2.4.0
podman pull quay.io/prometheus/node-exporter:v1.3.1
podman pull quay.io/prometheus/alertmanager:v0.23.0
podman pull quay.io/ceph/ceph-grafana:8.3.5
podman pull quay.io/ceph/haproxy:2.3
podman pull quay.io/ceph/keepalived:2.1.5
podman pull docker.io/maxwo/snmp-notifier:v1.2.1Trong đó:
quay.io/ceph/ceph:v17.2.6: Image này chứa Ceph.quay.io/prometheus/prometheus:v2.33.4: Image này chứa Prometheus, một hệ thống giám sát và cảnh báo mã nguồn mở. Prometheus được sử dụng để thu thập và lưu trữ các số liệu từ các ứng dụng và hệ thống.docker.io/grafana/loki:2.4.0: Image này chứa Loki, một hệ thống ghi log mã nguồn mở từ Grafana. Loki được thiết kế để hoạt động cùng với Grafana để cung cấp việc trực quan hóa log.docker.io/grafana/promtail:2.4.0: Image này chứa Promtail, một agent thu thập log cho Loki. Promtail theo dõi các file log và gửi chúng đến Loki.quay.io/prometheus/node-exporter:v1.3.1: Image này chứa Node Exporter, một exporter Prometheus dùng để thu thập thông tin về hệ thống như CPU, memory, disk I/O, network, vv…quay.io/prometheus/alertmanager:v0.23.0: Image này chứa Alertmanager, một ứng dụng xử lý cảnh báo từ Prometheus.quay.io/ceph/ceph-grafana:8.3.5: Image này chứa Grafana, một công cụ trực quan hóa số liệu mã nguồn mở. Image này được tùy chỉnh bởi Ceph để hiển thị các số liệu từ Ceph.quay.io/ceph/haproxy:2.3: Image này chứa HAProxy, một máy chủ cân bằng tải mã nguồn mở. HAProxy thường được sử dụng để cân bằng tải giữa nhiều máy chủ backend.quay.io/ceph/keepalived:2.1.5: Image này chứa Keepalived, một ứng dụng giữ IP ảo cho tính sẵn sàng cao. Keepalived thường được sử dụng cùng với HAProxy để cung cấp tính sẵn sàng cao cho máy chủ cân bằng tải.docker.io/maxwo/snmp-notifier:v1.2.1: Image này chứa SNMP Notifier, một ứng dụng gửi cảnh báo qua SNMP.
3.2.3. Gán một tag mới cho một Docker image (áp dụng cho ceph-mon1).
Lệnh podman tag được sử dụng để gán một tag mới cho một Docker image đã tồn tại. Ví dụ để dưới đây gán tag 10.237.7.80:5000/ceph/ceph:v17.2.6 cho image quay.io/ceph/ceph:v17.2.6.
podman tag quay.io/ceph/ceph:v17.2.6 10.237.7.80:5000/ceph/ceph:v17.2.6Điều này có nghĩa là sau khi chạy lệnh này, bạn có thể tham chiếu đến image quay.io/ceph/ceph:v17.2.6 bằng cách sử dụng tag mới 10.237.7.80:5000/ceph/ceph:v17.2.6.
Điều này hữu ích khi bạn muốn đẩy (push) image này lên một Docker registry khác. Trong trường hợp này, bạn có thể đẩy image này lên Docker registry tại 10.237.7.80:5000 bằng cách sử dụng lệnh podman push 10.237.7.80:5000/ceph/ceph:v17.2.6.
Lưu ý rằng lệnh này không tạo ra một bản sao của image, nó chỉ thêm một tag mới cho image đã tồn tại.
Quay lại bài Lab, hãy gán tag cho tất cả các image đã pull về ở bước trên.
podman tag quay.io/ceph/ceph:v17.2.6 10.237.7.80:5000/ceph/ceph:v17.2.6
podman tag quay.io/prometheus/prometheus:v2.33.4 10.237.7.80:5000/prometheus/prometheus:v2.33.4
podman tag docker.io/grafana/loki:2.4.0 10.237.7.80:5000/grafana/loki:2.4.0
podman tag docker.io/grafana/promtail:2.4.0 10.237.7.80:5000/grafana/promtail:2.4.0
podman tag quay.io/prometheus/node-exporter:v1.3.1 10.237.7.80:5000/prometheus/node-exporter:v1.3.1
podman tag quay.io/prometheus/alertmanager:v0.23.0 10.237.7.80:5000/prometheus/alertmanager:v0.23.0
podman tag quay.io/ceph/ceph-grafana:8.3.5 10.237.7.80:5000/ceph/ceph-grafana:8.3.5
podman tag quay.io/ceph/haproxy:2.3 10.237.7.80:5000/ceph/haproxy:2.3
podman tag quay.io/ceph/keepalived:2.1.5 10.237.7.80:5000/ceph/keepalived:2.1.5
podman tag docker.io/maxwo/snmp-notifier:v1.2.1 10.237.7.80:5000/maxwo/snmp-notifier:v1.2.13.2.4. Đẩy (push) một Docker image lên một Docker registry (áp dụng cho ceph-mon1)
Lệnh podman push được sử dụng để đẩy (push) một Docker image lên một Docker registry. Trong ví dụ dưới bạn để ý lệnh đầu tiên podman push 10.237.7.80:5000/ceph/ceph:v17.2.6, lệnh này đang đẩy image 10.237.7.80:5000/ceph/ceph:v17.2.6 lên Docker registry tại 10.237.7.80:5000.
Điều này có nghĩa là sau khi chạy lệnh này, image 10.237.7.80:5000/ceph/ceph:v17.2.6 sẽ được lưu trữ trên Docker registry tại 10.237.7.80:5000 và bạn hoặc bất kỳ ai khác có thể kéo (pull) image này từ registry này.
Điều này hữu ích khi bạn muốn chia sẻ các Docker image giữa nhiều máy hoặc môi trường, hoặc khi bạn muốn lưu trữ các Docker image của mình trên một registry trung tâm để dễ dàng triển khai và quản lý.
podman push 10.237.7.80:5000/ceph/ceph:v17.2.6
podman push 10.237.7.80:5000/prometheus/prometheus:v2.33.4
podman push 10.237.7.80:5000/grafana/loki:2.4.0
podman push 10.237.7.80:5000/grafana/promtail:2.4.0
podman push 10.237.7.80:5000/prometheus/node-exporter:v1.3.1
podman push 10.237.7.80:5000/prometheus/alertmanager:v0.23.0
podman push 10.237.7.80:5000/ceph/ceph-grafana:8.3.5
podman push 10.237.7.80:5000/ceph/haproxy:2.3
podman push 10.237.7.80:5000/ceph/keepalived:2.1.5
podman push 10.237.7.80:5000/maxwo/snmp-notifier:v1.2.1Trick: Để cho nhanh bạn có thể chạy shell này.
# List of images to check and pull if not present
images=(
"quay.io/ceph/ceph:v17.2.6"
"quay.io/prometheus/prometheus:v2.33.4"
"docker.io/grafana/loki:2.4.0"
"docker.io/grafana/promtail:2.4.0"
"quay.io/prometheus/node-exporter:v1.3.1"
"quay.io/prometheus/alertmanager:v0.23.0"
"quay.io/ceph/ceph-grafana:8.3.5"
"quay.io/ceph/haproxy:2.3"
"quay.io/ceph/keepalived:2.1.5"
"docker.io/maxwo/snmp-notifier:v1.2.1"
)
for image in "${images[@]}"; do
if ! podman images | grep -q "$image"; then
podman pull $image
# Extract the image name and tag
IFS=':' read -ra ADDR <<< "$image"
image_name=${ADDR[0]}
image_tag=${ADDR[1]}
# Tag and push the image
podman tag $image ${registries_ipaddr}:5000/$image_name:$image_tag
podman push ${registries_ipaddr}:5000/$image_name:$image_tag
fi
done3.3. Copy sshkey cho tất cả các Node.
# Copy SSH key to servers
for ip in "${!hosts[@]}"; do
sshpass -p ${your_username} ssh-copy-id -o StrictHostKeyChecking=no -i /home/${your_username}/.ssh/id_rsa.pub ${your_username}@$ip
done3.4. Triển khai các thành phần cơ bản trên Ansbile Playbook.
Chuẩn bị các thành phần cơ bản, bạn cần chú ý đến các thành phần sau trước khi chạy playbook.
File hosts.<SITE_NAME>.<CLUSTER_NAME>.
Khai beo cho đúng thông tin hệ thống của bạn.
[ceph_admin]
[ceph_mon]
ceph-mon1 alias=LAB-81 ansible_host=10.237.7.81
ceph-mon2 alias=LAB-82 ansible_host=10.237.7.82
ceph-mon3 alias=LAB-83 ansible_host=10.237.7.83
[ceph_osd]
ceph-osd1 alias=LAB-84 ansible_host=10.237.7.84
ceph-osd2 alias=LAB-85 ansible_host=10.237.7.85
ceph-osd3 alias=LAB-86 ansible_host=10.237.7.86
[ceph:children]
ceph_admin
ceph_mon
ceph_osd
[ceph:vars]
ceph_version=quincy
ceph_image="10.237.7.81:5000/ceph/ceph:v17.2.6"
ceph_registry_host="10.237.7.81:5000"
organization='LAB'
site="SITE_NAME"
cluster="CLUSTER_NAME"
admin_nodes="10.237.7.81"
# Proxy
http_proxy="http://10.237.7.250:3128"
https_proxy="http://10.237.7.250:3128"
#NTP
ntp_srv_1="10.237.7.81"
ntp_srv_2="10.237.7.82"
# Check_mk agent
check_mk=10.237.7.81
#snmp proxy
ip_snmp_proxy_tos=10.237.7.81Thư mục include.d.
Thư mục này được dùng để lưu trữ thông tin về các tên người dùng, được phân loại thành hai nhóm:
Nhóm đầu tiên bao gồm các tên người dùng dành cho quản trị viên. Tên file cho nhóm này sẽ tuân theo định dạng users-<organization>.yml.
Nhóm thứ hai chứa các tên người dùng được sử dụng cho việc tương tác giữa các thành phần trong hệ thống Ceph. Tên file cho nhóm này sẽ tuân theo định dạng <SITE_NAME>_<CLUSTER_NAME>.yml.
Thư mục ./roles/ssh/files/<CLUSTER_NAME>/cephadmin.pri.
Nơi đây sẽ chứa thông tin private key của cephadmin.
-----BEGIN RSA PRIVATE KEY-----
<Private key>
-----END RSA PRIVATE KEY-----Cài đặt biến môi trường.
sshuser='hoanghd'
rsa=/home/${sshuser}/.ssh/id_rsa
farmname="${SITE_NAME}.${CLUSTER_NAME}"Lệnh ssh-add /home/${sshuser}/.ssh/id_rsa thêm private key SSH tại đường dẫn /home/${sshuser}/.ssh/id_rsa vào ssh-agent. Khi bạn cố gắng kết nối đến một máy chủ qua SSH, ssh sẽ tìm kiếm khóa tương ứng trong ssh-agent trước khi tìm trong hệ thống.
Kết hợp, hai lệnh này khởi chạy ssh-agent và thêm một private key vào nó, giúp tự động xác thực các kết nối SSH sau này trong phiên làm việc hiện tại mà không cần nhập mật khẩu cho khóa.
shell> eval `ssh-agent` && ssh-add /home/${sshuser}/.ssh/id_rsa
Agent pid 39008
Identity added: /home/hoanghd/.ssh/id_rsa (/home/hoanghd/.ssh/id_rsa)Sử dụng ansible-playbook để chạy playbook Ansible.
ansible-playbook -i hosts.${farmname} -u ${sshuser} --key-file ${rsa} -b --ask-become-pass playbook.yml --extra-vars "force_ansible=yes"Trong đó:
-i hosts.${farmname}: Đây là tham số inventory, nó chỉ định file inventory mà Ansible sẽ sử dụng. Trong trường hợp này, nó sẽ sử dụng filehosts.${farmname}.-u ${sshuser}: Tham số này chỉ định tên người dùng mà Ansible sẽ sử dụng khi kết nối đến remote server. Trong trường hợp này, nó sẽ sử dụng giá trị của biếnsshuser.--key-file ${rsa}: Tham số này chỉ định file chứa SSH private key mà Ansible sẽ sử dụng khi kết nối đến các máy chủ từ xa. Trong trường hợp này, nó sẽ sử dụng file được chỉ định bởi biếnrsa.-b: Tham số này cho phép chế độ become, cho phép Ansible thực thi các lệnh với quyền superuser.--ask-become-pass: Tham số này yêu cầu Ansible hỏi mật khẩu become (thường là mật khẩu của người dùng root hoặc sudo) khi playbook được chạy.playbook.yml: Đây là playbook mà Ansible sẽ chạy.--extra-vars "force_ansible=yes": Tham số này truyền một biến bổ sung vào playbook. Trong trường hợp này, biếnforce_ansibleđược đặt thànhyes.
4. Khởi tạo một cụm Ceph.
Cài đặt gói ceph-common bằng apt install ceph-common -y, gói này chứa các công cụ và thư viện chung cần thiết để làm việc với Ceph.
apt install ceph-common -yKhởi tạo một cụm Ceph mới bằng cách sử dụng cephadm bootstrap.
cephadm --image ${registries_ipaddr}:5000/ceph/ceph:v17.2.6 bootstrap \
--cluster-network ${cluster_network}\
--mon-ip ${cephmon_ipaddr} \
--ssh-user cephadmin \
--ssh-private-key /home/cephadmin/.ssh/id_rsa \
--ssh-public-key /home/cephadmin/.ssh/authorized_keys \
--initial-dashboard-user admin \
--initial-dashboard-password "${dashboard_passwd}" \
--skip-pull- Cụ thể, các tham số có nghĩa như sau:
--image 10.237.7.80:5000/ceph/ceph:v17.2.6: Sử dụng Docker image10.237.7.80:5000/ceph/ceph:v17.2.6cho các container Ceph.--cluster-network 10.237.7.0/24: Đặt mạng của cụm Ceph là10.237.7.0/24.--mon-ip 10.237.7.81: Đặt địa chỉ IP của monitor Ceph đầu tiên là10.237.7.81.--ssh-user cephadmin: Sử dụng người dùngcephadmincho các kết nối SSH.--ssh-private-key /home/cephadmin/.ssh/id_rsavà--ssh-public-key /home/cephadmin/.ssh/authorized_keys: Sử dụng khóa SSH từ các file chỉ định.--initial-dashboard-user adminvà--initial-dashboard-password "admin@storage": Đặt tên người dùng và mật khẩu ban đầu cho dashboard Ceph.--skip-pull: Không kéo image từ Docker registry, sử dụng image đã có trên máy cục bộ.
Nếu chạy đúng, đầu ra của bạn sẽ có logs dạng sau:
Adding key to cephadmin@localhost authorized_keys...
key already in cephadmin@localhost authorized_keys...
Verifying podman|docker is present...
Verifying lvm2 is present...
Verifying time synchronization is in place...
Unit chrony.service is enabled and running
Repeating the final host check...
podman (/usr/bin/podman) version 3.4.4 is present
systemctl is present
lvcreate is present
Unit chrony.service is enabled and running
Host looks OK
Cluster fsid: 239e0f34-103b-11ef-ad01-458af4713339
Verifying IP 10.237.7.81 port 3300 ...
Verifying IP 10.237.7.81 port 6789 ...
Mon IP `10.237.7.81` is in CIDR network `10.237.7.0/24`
Mon IP `10.237.7.81` is in CIDR network `10.237.7.0/24`
Ceph version: ceph version 17.2.6 (d7ff0d10654d2280e08f1ab989c7cdf3064446a5) quincy (stable)
Extracting ceph user uid/gid from container image...
Creating initial keys...
Creating initial monmap...
Creating mon...
Waiting for mon to start...
Waiting for mon...
mon is available
Assimilating anything we can from ceph.conf...
Generating new minimal ceph.conf...
Restarting the monitor...
Setting public_network to 10.237.7.0/24 in mon config section
Setting cluster_network to 10.237.7.0/24
Wrote config to /etc/ceph/ceph.conf
Wrote keyring to /etc/ceph/ceph.client.admin.keyring
Creating mgr...
Verifying port 9283 ...
Waiting for mgr to start...
Waiting for mgr...
mgr not available, waiting (1/15)...
mgr not available, waiting (2/15)...
mgr not available, waiting (3/15)...
mgr not available, waiting (4/15)...
mgr is available
Enabling cephadm module...
Waiting for the mgr to restart...
Waiting for mgr epoch 5...
mgr epoch 5 is available
Setting orchestrator backend to cephadm...
Using provided ssh keys...
Adding key to cephadmin@localhost authorized_keys...
key already in cephadmin@localhost authorized_keys...
Adding host ceph-mon1...
Deploying mon service with default placement...
Deploying mgr service with default placement...
Deploying crash service with default placement...
Deploying prometheus service with default placement...
Deploying grafana service with default placement...
Deploying node-exporter service with default placement...
Deploying alertmanager service with default placement...
Enabling the dashboard module...
Waiting for the mgr to restart...
Waiting for mgr epoch 9...
mgr epoch 9 is available
Generating a dashboard self-signed certificate...
Creating initial admin user...
Fetching dashboard port number...
Ceph Dashboard is now available at:
URL: https://ceph-mon1:8443/
User: admin
Password: Hoanghd164
Enabling client.admin keyring and conf on hosts with "admin" label
Saving cluster configuration to /var/lib/ceph/239e0f34-103b-11ef-ad01-458af4713339/config directory
Enabling autotune for osd_memory_target
You can access the Ceph CLI as following in case of multi-cluster or non-default config:
sudo /usr/local/bin/cephadm shell --fsid 239e0f34-103b-11ef-ad01-458af4713339 -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Or, if you are only running a single cluster on this host:
sudo /usr/local/bin/cephadm shell
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/master/mgr/telemetry/
Bootstrap complete.5. Truy cập Dashboard.
Bạn có thể truy cập https://ceph-mon1:8443 để vào giao diện của Dashboard nhé.

Bạn sẽ được yêu cầu thay đổi mật khẩu khi đăng nhập lần đầu.

Và đây là kết quả.
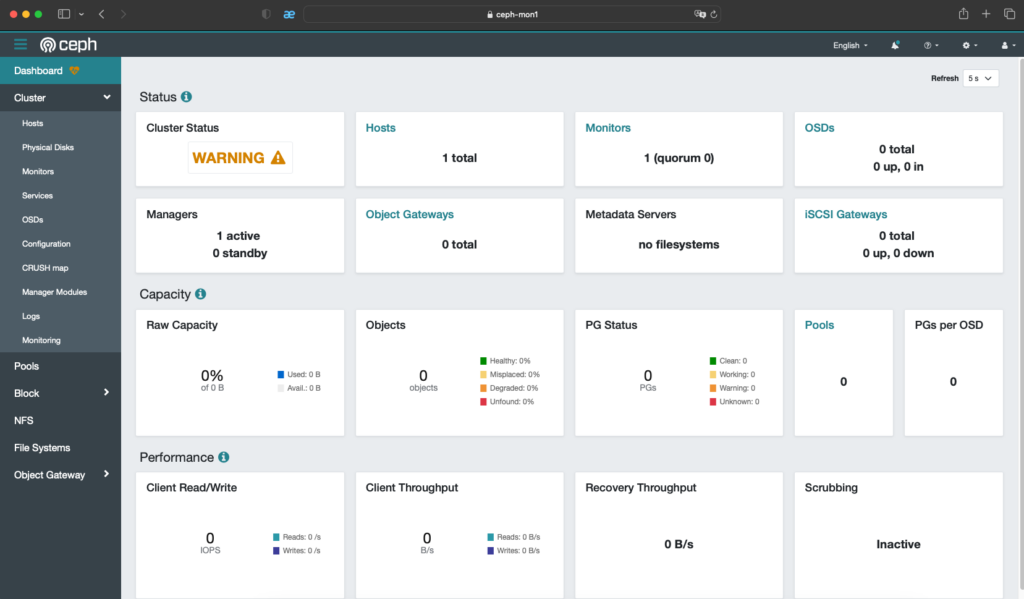
6. Khởi tạo các dịch vụ Ceph.
Khởi tạo MON services.
Chúng ta đang thêm các nhãn _admin, mon và mgr cho host ceph-mon1. Nhãn này sẽ được sử dụng để xác định nơi các dịch vụ Ceph sẽ chạy.
ceph orch host label add ceph-mon1 _admin
ceph orch host label add ceph-mon1 mon
ceph orch host label add ceph-mon1 mgrThêm 3 MON servers.
Thêm ceph-mon2 và ceph-mon3 vào cụm với các nhãn _admin, mon, và mgr.
ceph orch host add ceph-mon2 10.237.7.82 _admin mon mgr
ceph orch host add ceph-mon3 10.237.7.83 _admin mon mgrÁp dụng dịch vụ mon và mgr trên 3 MON servers.
Gửi yêu cầu tới Ceph Orchestrator để triển khai các dịch vụ mon và mgr trên các host có nhãn mon và mgr.
ceph orch apply mon --placement="label:mon"
ceph orch apply mgr --placement="label:mgr"Cấu hình các images được sử dụng.
Cấu hình Ceph để sử dụng các Docker image cụ thể cho các dịch vụ Prometheus, Grafana, Alertmanager và Node Exporter.
ceph config set mgr mgr/cephadm/container_image_prometheus 10.237.7.80:5000/prometheus/prometheus:v2.33.4
ceph config set mgr mgr/cephadm/container_image_grafana 10.237.7.80:5000/ceph/ceph-grafana:8.3.5
ceph config set mgr mgr/cephadm/container_image_alertmanager 10.237.7.80:5000/prometheus/alertmanager:v0.23.0
ceph config set mgr mgr/cephadm/container_image_node_exporter 10.237.7.80:5000/prometheus/node-exporter:v1.3.1Khởi tạo các OSD nodes.
Thêm host ceph-osd1, ceph-osd2 và ceph-osd3 vào cụm bằng cách sử dụng lệnh ceph orch host add.
ceph orch host add ceph-osd1 10.237.7.84
ceph orch host add ceph-osd2 10.237.7.85
ceph orch host add ceph-osd3 10.237.7.86Sau khi đã thêm xong các host OSD xong, bạn có thể tạo và áp dụng cấu hình OSD của mình bằng cách sử dụng file osd_spec.yaml.
cat > ./osd_spec.yaml << 'OEF'
service_type: osd
service_id: osd_SSD_30GB
service_name: osd.osd_SSD_30GB
placement:
host_pattern: '*'
label: osd
spec:
data_devices:
paths:
- /dev/sdb
- /dev/sdc
- /dev/sdd
- /dev/sde
- /dev/sdf
objectstore: bluestore
osds_per_device: 1
OEFĐây là một đoạn cấu hình cho dịch vụ OSD (Object Storage Daemon) trong Ceph, trong đó.
service_type: osd: Định nghĩa loại dịch vụ, trong trường hợp này là OSD.service_id: osd_SSD_30GB: Định danh duy nhất cho dịch vụ OSD này.service_name: osd.osd_SSD_30GB: Tên của dịch vụ, thường là sự kết hợp củaservice_typevàservice_id.placement: Định nghĩa nơi dịch vụ sẽ được triển khai.host_pattern: '*': Dịch vụ sẽ được triển khai trên tất cả các host phù hợp với mẫu này, trong trường hợp này là tất cả các host.label: osd: Dịch vụ sẽ được triển khai trên các host có nhãn “osd”.
spec: Mô tả cụ thể cho dịch vụ OSD.data_devices: Định nghĩa các thiết bị sẽ được sử dụng để lưu trữ dữ liệu.paths: Danh sách các đường dẫn đến các thiết bị sẽ được sử dụng.
objectstore: bluestore: Định nghĩa loại lưu trữ đối tượng sẽ được sử dụng, trong trường hợp này là Bluestore.osds_per_device: 1: Số lượng OSD sẽ được tạo trên mỗi ổ đĩa.
Áp dụng config.
ceph orch apply -i osd_spec.yamlXác nhận lại config đã được áp dụng thành công.
shell> ceph orch ls --export --service-type osd
service_type: osd
service_id: osd_SSD_30GB
service_name: osd.osd_SSD_30GB
placement:
host_pattern: '*'
label: osd
spec:
data_devices:
paths:
- /dev/sdb
- /dev/sdc
- /dev/sdd
- /dev/sde
- /dev/sdf
filter_logic: AND
objectstore: bluestore
osds_per_device: 1Bạn có thể kiểm tra trạng thái disk sau khi apply config trên ở 1 node OSD bất kỳ, bạn sẽ thấy các ổ đĩa đã được /dev/sdb – sdf đã được tạo các lvm như dưới.
cephadmin@ceph-osd1:~$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
loop0 7:0 0 62M 1 loop /snap/core20/1587
loop1 7:1 0 79.9M 1 loop /snap/lxd/22923
loop2 7:2 0 47M 1 loop /snap/snapd/16292
sda 8:0 0 50G 0 disk
├─sda1 8:1 0 1M 0 part
├─sda2 8:2 0 2G 0 part /boot
└─sda3 8:3 0 48G 0 part
└─ubuntu--vg-ubuntu--lv 253:0 0 24G 0 lvm /var/lib/containers/storage/overlay
/
sdb 8:16 0 30G 0 disk
└─ceph--cfd5a7fa--9f89--4c74--aae8--4f549de85ebf-osd--block--eb50d414--d478--4626--9805--a70ae269bff2 253:1 0 30G 0 lvm
sdc 8:32 0 30G 0 disk
└─ceph--fdd07a6a--11f7--47e9--b8a1--c28f6a0b423e-osd--block--0a614c2e--30b6--4dd6--b97b--3d9cbba81b90 253:2 0 30G 0 lvm
sdd 8:48 0 30G 0 disk
└─ceph--28a18ab0--8d90--4b4c--87b3--f59e53859acc-osd--block--fad80fd3--1061--4922--bdad--81fcfa510f80 253:3 0 30G 0 lvm
sde 8:64 0 30G 0 disk
└─ceph--f9e5bc13--29cb--4b3c--bbe5--3698aff0f2a0-osd--block--5da994f8--3714--40ee--bf05--434f5796a482 253:4 0 30G 0 lvm
sdf 8:80 0 30G 0 disk
└─ceph--af90d1de--2d56--450a--a9be--7cf8bb9fb99e-osd--block--9677f293--c438--4cae--8960--afc569fb17fb 253:5 0 30G 0 lvm
sr0 11:0 1 1024M 0 rom Thêm nhãn osd cho các host ceph-osd1, ceph-osd2 và ceph-osd3.
ceph orch host label add ceph-osd1 osd
ceph orch host label add ceph-osd2 osd
ceph orch host label add ceph-osd3 osdLệnh ceph orch device zap được sử dụng để xóa tất cả dữ liệu và metadata từ một thiết bị, chuẩn bị nó để sử dụng như một OSD (Object Storage Daemon) trong cụm Ceph.
Bạn hãy “zap” trên các thiết bị /dev/sdb, /dev/sdc, /dev/sdd, /dev/sde và /dev/sdf trên mỗi host, chuẩn bị chúng để sử dụng như các OSDs.
# ceph-osd1
ceph orch device zap ceph-osd1 /dev/sdb --force
ceph orch device zap ceph-osd1 /dev/sdc --force
ceph orch device zap ceph-osd1 /dev/sdd --force
ceph orch device zap ceph-osd1 /dev/sde --force
ceph orch device zap ceph-osd1 /dev/sdf --force
# ceph-osd2
ceph orch device zap ceph-osd2 /dev/sdb --force
ceph orch device zap ceph-osd2 /dev/sdc --force
ceph orch device zap ceph-osd2 /dev/sdd --force
ceph orch device zap ceph-osd2 /dev/sde --force
ceph orch device zap ceph-osd2 /dev/sdf --force
# ceph-osd3
ceph orch device zap ceph-osd3 /dev/sdb --force
ceph orch device zap ceph-osd3 /dev/sdc --force
ceph orch device zap ceph-osd3 /dev/sdd --force
ceph orch device zap ceph-osd3 /dev/sde --force
ceph orch device zap ceph-osd3 /dev/sdf --forceLưu ý rằng việc zap một thiết bị sẽ xóa tất cả dữ liệu trên đó, vì vậy hãy chắc chắn rằng bạn không mất dữ liệu quan trọng nào.
Nếu khi zap bạn gặp lỗi dưới đây thì hãy xử lý như sau:
shell> ceph orch device zap ceph-osd1 /dev/sdb --force
Error EINVAL: Zap failed:
Non-zero exit code 1 from /usr/bin/podman run --rm --ipc=host --stop-signal=SIGTERM --net=host --entrypoint /usr/sbin/ceph-volume --privileged --group-add=disk --init -e CONTAINER_IMAGE=10.237.7.80:5000/ceph/ceph@sha256:86f3a1cb9b4ea008df94f1eba06f7bf60b51078dce1d0649840f061510b5512e -e NODE_NAME=ceph-osd1 -e CEPH_USE_RANDOM_NONCE=1 -e CEPH_VOLUME_SKIP_RESTORECON=yes -e CEPH_VOLUME_DEBUG=1 -v /var/run/ceph/4c6753e4-107c-11ef-a794-973e8f2ccc15:/var/run/ceph:z -v /var/log/ceph/4c6753e4-107c-11ef-a794-973e8f2ccc15:/var/log/ceph:z -v /var/lib/ceph/4c6753e4-107c-11ef-a794-973e8f2ccc15/crash:/var/lib/ceph/crash:z -v /run/systemd/journal:/run/systemd/journal -v /dev:/dev -v /run/udev:/run/udev -v /sys:/sys -v /run/lvm:/run/lvm -v /run/lock/lvm:/run/lock/lvm -v /:/rootfs 10.237.7.80:5000/ceph/ceph@sha256:86f3a1cb9b4ea008df94f1eba06f7bf60b51078dce1d0649840f061510b5512e lvm zap --destroy /dev/sdb
/usr/bin/podman: stderr --> Zapping: /dev/sdb
/usr/bin/podman: stderr --> Zapping lvm member /dev/sdb. lv_path is /dev/ceph-cfd5a7fa-9f89-4c74-aae8-4f549de85ebf/osd-block-eb50d414-d478-4626-9805-a70ae269bff2
/usr/bin/podman: stderr Running command: /usr/bin/dd if=/dev/zero of=/dev/ceph-cfd5a7fa-9f89-4c74-aae8-4f549de85ebf/osd-block-eb50d414-d478-4626-9805-a70ae269bff2 bs=1M count=10 conv=fsync
/usr/bin/podman: stderr stderr: 10+0 records in
/usr/bin/podman: stderr 10+0 records out
/usr/bin/podman: stderr stderr: 10485760 bytes (10 MB, 10 MiB) copied, 0.0466303 s, 225 MB/s
/usr/bin/podman: stderr --> Only 1 LV left in VG, will proceed to destroy volume group ceph-cfd5a7fa-9f89-4c74-aae8-4f549de85ebf
/usr/bin/podman: stderr Running command: nsenter --mount=/rootfs/proc/1/ns/mnt --ipc=/rootfs/proc/1/ns/ipc --net=/rootfs/proc/1/ns/net --uts=/rootfs/proc/1/ns/uts /sbin/vgremove -v -f ceph-cfd5a7fa-9f89-4c74-aae8-4f549de85ebf
/usr/bin/podman: stderr stderr: Logical volume ceph-cfd5a7fa-9f89-4c74-aae8-4f549de85ebf/osd-block-eb50d414-d478-4626-9805-a70ae269bff2 in use.
/usr/bin/podman: stderr --> Unable to remove vg ceph-cfd5a7fa-9f89-4c74-aae8-4f549de85ebf
/usr/bin/podman: stderr Traceback (most recent call last):
/usr/bin/podman: stderr File "/usr/sbin/ceph-volume", line 11, in <module>
/usr/bin/podman: stderr load_entry_point('ceph-volume==1.0.0', 'console_scripts', 'ceph-volume')()
/usr/bin/podman: stderr File "/usr/lib/python3.6/site-packages/ceph_volume/main.py", line 41, in __init__
/usr/bin/podman: stderr self.main(self.argv)
/usr/bin/podman: stderr File "/usr/lib/python3.6/site-packages/ceph_volume/decorators.py", line 59, in newfunc
/usr/bin/podman: stderr return f(*a, **kw)
/usr/bin/podman: stderr File "/usr/lib/python3.6/site-packages/ceph_volume/main.py", line 153, in main
/usr/bin/podman: stderr terminal.dispatch(self.mapper, subcommand_args)
/usr/bin/podman: stderr File "/usr/lib/python3.6/site-packages/ceph_volume/terminal.py", line 194, in dispatch
/usr/bin/podman: stderr instance.main()
/usr/bin/podman: stderr File "/usr/lib/python3.6/site-packages/ceph_volume/devices/lvm/main.py", line 46, in main
/usr/bin/podman: stderr terminal.dispatch(self.mapper, self.argv)
/usr/bin/podman: stderr File "/usr/lib/python3.6/site-packages/ceph_volume/terminal.py", line 194, in dispatch
/usr/bin/podman: stderr instance.main()
/usr/bin/podman: stderr File "/usr/lib/python3.6/site-packages/ceph_volume/devices/lvm/zap.py", line 406, in main
/usr/bin/podman: stderr self.zap()
/usr/bin/podman: stderr File "/usr/lib/python3.6/site-packages/ceph_volume/decorators.py", line 16, in is_root
/usr/bin/podman: stderr return func(*a, **kw)
/usr/bin/podman: stderr File "/usr/lib/python3.6/site-packages/ceph_volume/devices/lvm/zap.py", line 275, in zap
/usr/bin/podman: stderr self.zap_lvm_member(device)
/usr/bin/podman: stderr File "/usr/lib/python3.6/site-packages/ceph_volume/devices/lvm/zap.py", line 234, in zap_lvm_member
/usr/bin/podman: stderr self.zap_lv(Device(lv.lv_path))
/usr/bin/podman: stderr File "/usr/lib/python3.6/site-packages/ceph_volume/devices/lvm/zap.py", line 185, in zap_lv
/usr/bin/podman: stderr api.remove_vg(device.vg_name)
/usr/bin/podman: stderr File "/usr/lib/python3.6/site-packages/ceph_volume/api/lvm.py", line 733, in remove_vg
/usr/bin/podman: stderr fail_msg=fail_msg,
/usr/bin/podman: stderr File "/usr/lib/python3.6/site-packages/ceph_volume/process.py", line 147, in run
/usr/bin/podman: stderr raise RuntimeError(msg)
/usr/bin/podman: stderr RuntimeError: command returned non-zero exit status: 5
Traceback (most recent call last):
File "/var/lib/ceph/4c6753e4-107c-11ef-a794-973e8f2ccc15/cephadm.7ab03136237675497d535fb1b85d1d0f95bbe5b95f32cd4e6f3ca71a9f97bf3c", line 9653, in <module>
main()
File "/var/lib/ceph/4c6753e4-107c-11ef-a794-973e8f2ccc15/cephadm.7ab03136237675497d535fb1b85d1d0f95bbe5b95f32cd4e6f3ca71a9f97bf3c", line 9641, in main
r = ctx.func(ctx)
File "/var/lib/ceph/4c6753e4-107c-11ef-a794-973e8f2ccc15/cephadm.7ab03136237675497d535fb1b85d1d0f95bbe5b95f32cd4e6f3ca71a9f97bf3c", line 2153, in _infer_config
return func(ctx)
File "/var/lib/ceph/4c6753e4-107c-11ef-a794-973e8f2ccc15/cephadm.7ab03136237675497d535fb1b85d1d0f95bbe5b95f32cd4e6f3ca71a9f97bf3c", line 2069, in _infer_fsid
return func(ctx)
File "/var/lib/ceph/4c6753e4-107c-11ef-a794-973e8f2ccc15/cephadm.7ab03136237675497d535fb1b85d1d0f95bbe5b95f32cd4e6f3ca71a9f97bf3c", line 2181, in _infer_image
return func(ctx)
File "/var/lib/ceph/4c6753e4-107c-11ef-a794-973e8f2ccc15/cephadm.7ab03136237675497d535fb1b85d1d0f95bbe5b95f32cd4e6f3ca71a9f97bf3c", line 2056, in _validate_fsid
return func(ctx)
File "/var/lib/ceph/4c6753e4-107c-11ef-a794-973e8f2ccc15/cephadm.7ab03136237675497d535fb1b85d1d0f95bbe5b95f32cd4e6f3ca71a9f97bf3c", line 6254, in command_ceph_volume
out, err, code = call_throws(ctx, c.run_cmd(), verbosity=CallVerbosity.QUIET_UNLESS_ERROR)
File "/var/lib/ceph/4c6753e4-107c-11ef-a794-973e8f2ccc15/cephadm.7ab03136237675497d535fb1b85d1d0f95bbe5b95f32cd4e6f3ca71a9f97bf3c", line 1853, in call_throws
raise RuntimeError('Failed command: %s' % ' '.join(command))
RuntimeError: Failed command: /usr/bin/podman run --rm --ipc=host --stop-signal=SIGTERM --net=host --entrypoint /usr/sbin/ceph-volume --privileged --group-add=disk --init -e CONTAINER_IMAGE=10.237.7.80:5000/ceph/ceph@sha256:86f3a1cb9b4ea008df94f1eba06f7bf60b51078dce1d0649840f061510b5512e -e NODE_NAME=ceph-osd1 -e CEPH_USE_RANDOM_NONCE=1 -e CEPH_VOLUME_SKIP_RESTORECON=yes -e CEPH_VOLUME_DEBUG=1 -v /var/run/ceph/4c6753e4-107c-11ef-a794-973e8f2ccc15:/var/run/ceph:z -v /var/log/ceph/4c6753e4-107c-11ef-a794-973e8f2ccc15:/var/log/ceph:z -v /var/lib/ceph/4c6753e4-107c-11ef-a794-973e8f2ccc15/crash:/var/lib/ceph/crash:z -v /run/systemd/journal:/run/systemd/journal -v /dev:/dev -v /run/udev:/run/udev -v /sys:/sys -v /run/lvm:/run/lvm -v /run/lock/lvm:/run/lock/lvm -v /:/rootfs 10.237.7.80:5000/ceph/ceph@sha256:86f3a1cb9b4ea008df94f1eba06f7bf60b51078dce1d0649840f061510b5512e lvm zap --destroy /dev/sdbLỗi này xảy ra khi bạn cố gắng zap một ổ đĩa mà đang được sử dụng bởi một logical volume (LV) trong Ceph. Trong trường hợp này, LV đang được sử dụng bởi OSD Ceph.
Bạn hãy remote vào node ceph osd và sử dụng lệnh ceph-volume lvm zap. Lệnh này sẽ “zap” tất cả các LV trên ổ đĩa, không chỉ LV được sử dụng bởi Ceph.
Đầu tiên bạn cần cài 2 gói ceph-common và ceph-volume vào ceph osd bạn mà sẽ sử dụng lệnh ceph-volume lvm zap để xoá metadata.
apt install ceph-common ceph-volume -yTiếp theo hãy chạy lệnh ceph-volume lvm zap <device> như dưới.
shell> ceph-volume lvm zap /dev/sdb
--> Zapping: /dev/sdb
--> --destroy was not specified, but zapping a whole device will remove the partition table
Running command: /usr/bin/dd if=/dev/zero of=/dev/sdb bs=1M count=10 conv=fsync
stderr: 10+0 records in
10+0 records out
10485760 bytes (10 MB, 10 MiB) copied, 0.0316393 s, 331 MB/s
stderr:
--> Zapping successful for: <Raw Device: /dev/sdb>Nếu bạn gặp lỗi dưới, hãy đọc tiếp nhé.
shell> ceph-volume lvm zap /dev/sdb
--> Zapping: /dev/sdb
--> Zapping lvm member /dev/sdb. lv_path is /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/osd-block-e97174e0-aa27-4220-a919-224631269516
Running command: /usr/bin/dd if=/dev/zero of=/dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/osd-block-e97174e0-aa27-4220-a919-224631269516 bs=1M count=10 conv=fsync
stderr: 10+0 records in
10+0 records out
stderr: 10485760 bytes (10 MB, 10 MiB) copied, 0.0450667 s, 233 MB/s
--> --destroy was not specified, but zapping a whole device will remove the partition table
stderr: wipefs: error: /dev/sdb: probing initialization failed: Device or resource busy
--> failed to wipefs device, will try again to workaround probable race condition
stderr: wipefs: error: /dev/sdb: probing initialization failed: Device or resource busy
--> failed to wipefs device, will try again to workaround probable race condition
stderr: wipefs: error: /dev/sdb: probing initialization failed: Device or resource busy
--> failed to wipefs device, will try again to workaround probable race condition
stderr: wipefs: error: /dev/sdb: probing initialization failed: Device or resource busy
--> failed to wipefs device, will try again to workaround probable race condition
stderr: wipefs: error: /dev/sdb: probing initialization failed: Device or resource busy
--> failed to wipefs device, will try again to workaround probable race condition
stderr: wipefs: error: /dev/sdb: probing initialization failed: Device or resource busy
--> failed to wipefs device, will try again to workaround probable race condition
stderr: wipefs: error: /dev/sdb: probing initialization failed: Device or resource busy
--> failed to wipefs device, will try again to workaround probable race condition
stderr: wipefs: error: /dev/sdb: probing initialization failed: Device or resource busy
--> failed to wipefs device, will try again to workaround probable race condition
--> RuntimeError: could not complete wipefs on device: /dev/sdbLỗi này xảy ra khi ceph-volume lvm zap không thể xóa các phân vùng trên thiết bị do thiết bị đang bận. Điều này có thể xảy ra nếu có một quá trình nào đó đang sử dụng thiết bị.
Bạn có thể sử dụng lệnh lsof hoặc fuser để xem quá trình nào đang sử dụng thiết bị:
sudo lsof /dev/sdbHoặc
sudo fuser -m /dev/sdbNếu có quá trình nào đang sử dụng thiết bị, bạn sẽ cần dừng hoặc giết chúng trước khi chạy ceph-volume lvm zap một lần nữa.
Nếu không có quá trình nào đang sử dụng thiết bị, bạn có thể thử chạy ceph-volume lvm zap với tùy chọn --destroy để xóa tất cả dữ liệu và metadata trên thiết bị:
ceph-volume lvm zap /dev/sdb --destroyLưu ý rằng tùy chọn --destroy sẽ xóa tất cả dữ liệu và metadata trên thiết bị, vì vậy hãy chắc chắn rằng bạn đã sao lưu bất kỳ dữ liệu quan trọng nào trước khi chạy lệnh này.
shell> ceph-volume lvm zap /dev/sdb --destroy
--> Zapping: /dev/sdb
--> Zapping lvm member /dev/sdb. lv_path is /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/osd-block-e97174e0-aa27-4220-a919-224631269516
Running command: /usr/bin/dd if=/dev/zero of=/dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/osd-block-e97174e0-aa27-4220-a919-224631269516 bs=1M count=10 conv=fsync
stderr: 10+0 records in
10+0 records out
stderr: 10485760 bytes (10 MB, 10 MiB) copied, 0.0480255 s, 218 MB/s
--> Only 1 LV left in VG, will proceed to destroy volume group ceph-4da020f9-4417-4f76-871b-99aae8443289
Running command: vgremove -v -f ceph-4da020f9-4417-4f76-871b-99aae8443289
stderr: Logical volume ceph-4da020f9-4417-4f76-871b-99aae8443289/osd-block-e97174e0-aa27-4220-a919-224631269516 in use.
--> Unable to remove vg ceph-4da020f9-4417-4f76-871b-99aae8443289
--> RuntimeError: command returned non-zero exit status: 5Nếu gặp lỗi RuntimeError: command returned non-zero exit status như trên hãy làm tiếp các bước sau đây.
shell> sudo lsof /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/osd-block-e97174e0-aa27-4220-a919-224631269516
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
ceph-osd 21910 ceph 32u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 33u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 34u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 35u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 36u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 37u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 38u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 39u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 40u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 41u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 42u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 43u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 44u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 45u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 46u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 47u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 48u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 49u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 50u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 51u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 52u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 53u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 54u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1
ceph-osd 21910 ceph 55u BLK 253,1 0t0 791 /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/../dm-1Hoặc.
shell> sudo fuser -m /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/osd-block-e97174e0-aa27-4220-a919-224631269516
/dev/dm-1: 21910Kết quả cho thấy quá trình ceph-osd với PID 21910 đang sử dụng logical volume. Bạn cần dừng hoặc giết quá trình này trước khi tiếp tục.
Bạn có thể dừng quá trình này bằng cách sử dụng lệnh kill hoặc killall:
kill 21910Hoặc.
killall ceph-osdHãy chắc chắn rằng sau khi kill thì bạn chạy lại lệnh sudo fuser -m /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/osd-block-e97174e0-aa27-4220-a919-224631269516 thì không có kết quả nào trả về.
Tiếp theo bạn có thể thử chạy lại lệnh ceph-volume lvm zap để xóa logical volume và group volume, và dưới đây là kết quả.
shell> ceph-volume lvm zap /dev/sdb --destroy
--> Zapping: /dev/sdb
--> Zapping lvm member /dev/sdb. lv_path is /dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/osd-block-e97174e0-aa27-4220-a919-224631269516
Running command: /usr/bin/dd if=/dev/zero of=/dev/ceph-4da020f9-4417-4f76-871b-99aae8443289/osd-block-e97174e0-aa27-4220-a919-224631269516 bs=1M count=10 conv=fsync
stderr: 10+0 records in
10+0 records out
stderr: 10485760 bytes (10 MB, 10 MiB) copied, 0.0861038 s, 122 MB/s
--> Only 1 LV left in VG, will proceed to destroy volume group ceph-4da020f9-4417-4f76-871b-99aae8443289
Running command: vgremove -v -f ceph-4da020f9-4417-4f76-871b-99aae8443289
stderr: Removing ceph--4da020f9--4417--4f76--871b--99aae8443289-osd--block--e97174e0--aa27--4220--a919--224631269516 (253:1)
stderr: Archiving volume group "ceph-4da020f9-4417-4f76-871b-99aae8443289" metadata (seqno 6).
stderr: Releasing logical volume "osd-block-e97174e0-aa27-4220-a919-224631269516"
stderr: /dev/sdb: BLKDISCARD ioctl at offset 1048576 size 32208060416 failed: Input/output error.
stderr: Creating volume group backup "/etc/lvm/backup/ceph-4da020f9-4417-4f76-871b-99aae8443289" (seqno 7).
stdout: Logical volume "osd-block-e97174e0-aa27-4220-a919-224631269516" successfully removed
stderr: Removing physical volume "/dev/sdb" from volume group "ceph-4da020f9-4417-4f76-871b-99aae8443289"
stdout: Volume group "ceph-4da020f9-4417-4f76-871b-99aae8443289" successfully removed
Running command: pvremove -v -f -f /dev/sdb
stdout: Labels on physical volume "/dev/sdb" successfully wiped.
Running command: /usr/bin/dd if=/dev/zero of=/dev/sdb bs=1M count=10 conv=fsync
stderr: 10+0 records in
10+0 records out
stderr: 10485760 bytes (10 MB, 10 MiB) copied, 0.0568991 s, 184 MB/s
--> Zapping successful for: <Raw Device: /dev/sdb>Có một mẹo tránh lỗi này là trước khi thêm một disk vào cluster Ceph, bạn nên “zap” nó để đảm bảo rằng không còn dữ liệu cũ nào tồn tại. “Zapping” một disk sẽ xóa tất cả dữ liệu trên đó và chuẩn bị nó cho việc sử dụng trong Ceph.
Sau khi zap xong thì ổ đĩa sdb tạm thời sẽ bị xoá, unmount,… nhưng hãy cho nó thời gian, Ceph sẽ tự động khởi tạo lại dịch vụ osd cho ổ đĩa này và khi dùng lệnh lsblk bạn cũng thấy ổ đĩa đã được khởi tạo và join lại vào dịch vụ osd của Ceph.
shell> lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
loop0 7:0 0 62M 1 loop /snap/core20/1587
loop1 7:1 0 79.9M 1 loop /snap/lxd/22923
loop3 7:3 0 38.8M 1 loop /snap/snapd/21759
loop4 7:4 0 63.9M 1 loop /snap/core20/2318
loop5 7:5 0 87M 1 loop /snap/lxd/28373
sda 8:0 0 50G 0 disk
├─sda1 8:1 0 1M 0 part
├─sda2 8:2 0 2G 0 part /boot
└─sda3 8:3 0 48G 0 part
└─ubuntu--vg-ubuntu--lv 253:0 0 24G 0 lvm /var/lib/containers/storage/overlay
/
sdb 8:16 0 30G 0 disk
└─ceph--3efa5fc0--cb4a--4aa0--bf57--ae0797ba602d-osd--block--b3dea2cd--2659--43a6--9172--a9bceb0ea9a9 253:1 0 30G 0 lvm
sdc 8:32 0 30G 0 disk
└─ceph--a6fb266c--e923--484b--bafb--317a2eb248e2-osd--block--1e3b7ef1--b4be--4bd8--b222--3c26cc4bad7b 253:2 0 30G 0 lvm
sdd 8:48 0 30G 0 disk
└─ceph--206423b0--2be7--43a3--83ae--e5b0ad468974-osd--block--8c8d5158--525e--4833--8f4f--620ceb9dc2ff 253:3 0 30G 0 lvm
sde 8:64 0 30G 0 disk
└─ceph--bdc94023--17d9--4721--b739--32c704fb8270-osd--block--723c41c7--ac75--4966--a73a--1d45be0cf43d 253:4 0 30G 0 lvm
sdf 8:80 0 30G 0 disk
└─ceph--ebbfa131--3cec--4d35--8d1c--311ae599a590-osd--block--864bd159--4eae--441e--9db3--1a407974a5b2 253:5 0 30G 0 lvm
sr0Kiểm tra trạng thái của OSD bằng lệnh ceph osd tree. Điều này sẽ cho bạn biết OSD nào đang hoạt động (up) và OSD nào không hoạt động (down). Và kết quả dưới đây ceph-osd1 đang có 1 osd bị down và nó có tới 6 osd (thực tế chỉ có 5 osd như 2 node còn lại), lý do là do chúng ta zap thì osd.0 đã bị loại bỏ và chuyển sang trạng thái down đồng thời ceph cũng đã thêm lại osd này vào lại cụm và do osd.0 đã tồn tại nên nó sinh ra osd id khác, vì vậy node này sẽ bị dư 1 osd.0. Chúng ta cần xoá nó ra khỏi cụm.
shell> ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.46875 root default
-3 0.17578 host ceph-osd1
0 ssd 0.02930 osd.0 down 0 1.00000
3 ssd 0.02930 osd.3 up 1.00000 1.00000
8 ssd 0.02930 osd.8 up 1.00000 1.00000
9 ssd 0.02930 osd.9 up 1.00000 1.00000
12 ssd 0.02930 osd.12 up 1.00000 1.00000
15 ssd 0.02930 osd.15 up 1.00000 1.00000
-7 0.14648 host ceph-osd2
2 ssd 0.02930 osd.2 up 1.00000 1.00000
4 ssd 0.02930 osd.4 up 1.00000 1.00000
6 ssd 0.02930 osd.6 up 1.00000 1.00000
11 ssd 0.02930 osd.11 up 1.00000 1.00000
14 ssd 0.02930 osd.14 up 1.00000 1.00000
-5 0.14648 host ceph-osd3
1 ssd 0.02930 osd.1 up 1.00000 1.00000
5 ssd 0.02930 osd.5 up 1.00000 1.00000
7 ssd 0.02930 osd.7 up 1.00000 1.00000
10 ssd 0.02930 osd.10 up 1.00000 1.00000
13 ssd 0.02930 osd.13 up 1.00000 1.00000Đầu tiên, bạn cần xóa OSD bị down bằng lệnh: ceph osd out osd.<osd-id> và ceph osd purge osd.<osd-id> --yes-i-really-mean-it.
shell> ceph osd out osd.0
osd.0 is already out
shell> ceph osd purge osd.0 --yes-i-really-mean-it
purged osd.0Kiểm tra lại trạng thái của OSD bằng lệnh ceph osd tree để xem osd.0 đã bị xoá hay chưa và chúng ta có kết quả.
shell> ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.46875 root default
-3 0.17578 host ceph-osd1
3 ssd 0.02930 osd.3 up 1.00000 1.00000
8 ssd 0.02930 osd.8 up 1.00000 1.00000
9 ssd 0.02930 osd.9 up 1.00000 1.00000
12 ssd 0.02930 osd.12 up 1.00000 1.00000
15 ssd 0.02930 osd.15 up 1.00000 1.00000
-7 0.14648 host ceph-osd2
2 ssd 0.02930 osd.2 up 1.00000 1.00000
4 ssd 0.02930 osd.4 up 1.00000 1.00000
6 ssd 0.02930 osd.6 up 1.00000 1.00000
11 ssd 0.02930 osd.11 up 1.00000 1.00000
14 ssd 0.02930 osd.14 up 1.00000 1.00000
-5 0.14648 host ceph-osd3
1 ssd 0.02930 osd.1 up 1.00000 1.00000
5 ssd 0.02930 osd.5 up 1.00000 1.00000
7 ssd 0.02930 osd.7 up 1.00000 1.00000
10 ssd 0.02930 osd.10 up 1.00000 1.00000
13 ssd 0.02930 osd.13 up 1.00000 1.00000Verify lại cụm bằng ceph -s bạn có kết quả.
shell> ceph -s
cluster:
id: 4d726630-1bd4-11ef-ac2d-013818cf3990
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-mon1,ceph-mon2,ceph-mon3 (age 89m)
mgr: ceph-mon1.kqyjql(active, since 92m), standbys: ceph-mon2.gmtarc, ceph-mon3.zngjzp
osd: 15 osds: 15 up (since 43m), 15 in (since 43m)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 449 KiB
usage: 123 MiB used, 450 GiB / 450 GiB avail
pgs: 1 active+clea7. Khởi tạo cấu trúc pools.
7.1 Lý thuyết.
Dữ liệu được lưu trữ trong các pools. Mỗi pool chứa một tập hợp các objects, và mỗi object là một đơn vị dữ liệu mà Ceph quản lý.
Cấu trúc “Root → rules → pool” mô tả cách mà Ceph phân phối dữ liệu giữa các OSD (Object Storage Daemons):
- Root: Đây là một bucket trong CRUSH map của Ceph. CRUSH (Controlled Replication Under Scalable Hashing) là thuật toán mà Ceph sử dụng để xác định cách phân phối dữ liệu trên các OSD. Một bucket là một nhóm các OSD hoặc các bucket khác.
- Rules: Các rules CRUSH xác định cách mà Ceph phân phối dữ liệu giữa các OSD. Một rule có thể chỉ định, ví dụ, rằng một bản sao của mỗi object nên được lưu trữ trên mỗi rack trong một trung tâm dữ liệu, để đảm bảo rằng dữ liệu không bị mất nếu một rack gặp sự cố.
- Pool: Mỗi pool chứa một tập hợp các objects. Khi bạn tạo một pool, bạn chỉ định một rule CRUSH, và Ceph sẽ sử dụng rule này để xác định cách phân phối dữ liệu trong pool giữa các OSD.
CRUSH (Controlled Replication Under Scalable Hashing) là thuật toán mà Ceph sử dụng để xác định cách phân phối dữ liệu trên các OSD (Object Storage Daemons) trong cụm. CRUSH map là cấu trúc dữ liệu mà CRUSH sử dụng để mô tả cấu trúc và cấu hình của cụm.
Một bucket trong CRUSH map là một nhóm các OSD hoặc các bucket khác. Đổi tên một bucket có thể hữu ích nếu bạn muốn thay đổi cách mà Ceph xem xét cấu trúc của cụm, ví dụ, để phản ánh việc thay đổi phần cứng hoặc cấu hình mạng.
7.2. Thực hành.
Mình sẽ đặt tên cho root và pool giống nhau để dễ dàng quản lý, giúp chúng ta quản lý hệ thống dễ dàng nhận biết mối quan hệ giữa các pools và các bucket CRUSH.
7.2.1. Đổi tên root bucket default thành ssd-01
Bạn hãy dụng lệnh ceph osd crush rename-bucket default ssd-01 được sử dụng để đổi tên một bucket trong CRUSH map của Ceph từ default thành ssd-01. Với ssd-01 là tên mới của bucket trong CRUSH map của Ceph.
shell> ceph osd crush rename-bucket default ssd-01
renamed bucket default into ssd-01Tên ssd-01 có thể được chọn để phản ánh một số thông tin về bucket hoặc các OSD bên trong nó. Ví dụ, nó có thể chỉ ra rằng các OSD trong bucket này đều nằm trên các ổ đĩa SSD, hoặc rằng đây là bucket SSD đầu tiên trong một loạt các bucket.
Bạn có thể sử dụng lệnh ceph osd crush tree để xem cấu trúc CRUSH map hiện tại.
shell> ceph osd crush tree
ID CLASS WEIGHT TYPE NAME
-1 0.43945 root ssd-01
-3 0.14648 host ceph-osd1
3 ssd 0.02930 osd.3
8 ssd 0.02930 osd.8
9 ssd 0.02930 osd.9
12 ssd 0.02930 osd.12
15 ssd 0.02930 osd.15
-7 0.14648 host ceph-osd2
2 ssd 0.02930 osd.2
4 ssd 0.02930 osd.4
6 ssd 0.02930 osd.6
11 ssd 0.02930 osd.11
14 ssd 0.02930 osd.14
-5 0.14648 host ceph-osd3
1 ssd 0.02930 osd.1
5 ssd 0.02930 osd.5
7 ssd 0.02930 osd.7
10 ssd 0.02930 osd.10
13 ssd 0.02930 osd.13Nếu lệnh rename-bucket đã hoạt động thành công, bạn sẽ thấy tên ssd-01 thay vì default trong kết quả.
7.2.1. Tạo rule replicated_ssd_01
Trong Ceph, một rule là một tập hợp các hướng dẫn mà hệ thống CRUSH (Controlled Replication Under Scalable Hashing) sử dụng để xác định cách phân phối và sao lưu dữ liệu trên các OSD (Object Storage Daemon) trong cụm.
CRUSH là thuật toán mà Ceph sử dụng để xác định cách lưu trữ và truy xuất dữ liệu trong cụm một cách hiệu quả. CRUSH cho phép Ceph có thể mở rộng linh hoạt, tự động cân bằng tải và hỗ trợ sự chịu lỗi.
Câu lệnh ceph osd crush rule create-replicated <rule_name> <root_name> host ssd tạo một rule mới trong CRUSH map. Trong câu lệnh này:
ceph osd crush rule create-replicated <rule_name> <root_name> host ssdTrong lệnh này:
<rule_name>là tên của rule mới. Bạn sẽ sử dụng tên này khi tạo hoặc cập nhật pools để chỉ định rằng Ceph nên sử dụng rule này khi phân phối dữ liệu.<root_name>là tên của bucket root trong CRUSH map mà rule sẽ áp dụng. Bucket root là một nhóm các OSD hoặc các bucket khác.hostvàssdlà các tiêu chí mà rule sẽ sử dụng để chọn OSD. Trong trường hợp này, rule sẽ chỉ chọn các OSD nằm trên các host có ổ đĩa SSD.
Ví dụ, nếu bạn muốn tạo một rule tên là replicated_ssd_01 cho bucket root ssd-01 và chỉ sử dụng các OSD trên ổ đĩa SSD, bạn sẽ chạy lệnh sau:
ceph osd crush rule create-replicated replicated_ssd_01 ssd-01 host ssdBạn có thể sử dụng lệnh ceph osd crush rule ls để liệt kê tất cả các rule trong CRUSH map.
shell> ceph osd crush rule ls
replicated_rule
replicated_ssd_01Nếu lệnh create-replicated đã hoạt động thành công, bạn sẽ thấy tên replicated_ssd_01 trong danh sách.
7.2.2. Tạo pool.
Cú pháp.
Lệnh ceph osd pool create <pool_name> <pg_num> <pgp_num> replicated <rule_name> được sử dụng để tạo một pool mới trong Ceph.
ceph osd pool create <pool_name> <pg_num> <pgp_num> replicated <rule_name> Trong lệnh này:
<pool_name>là tên của pool mới. Mỗi pool chứa một tập hợp các objects, và mỗi object là một đơn vị dữ liệu mà Ceph quản lý.<pg_num>và<pgp_num>là số lượng placement groups (PGs) và PGs for placement (PGPs) trong pool. PGs là các đơn vị mà Ceph sử dụng để phân phối dữ liệu giữa các OSD (Object Storage Daemons). Số lượng PGs và PGPs cần được chọn cẩn thận để cân nhắc giữa hiệu suất và độ chính xác của việc phân phối dữ liệu.replicatedchỉ ra rằng pool này sẽ sử dụng kiểu lưu trữ replicated, trong đó mỗi object sẽ được lưu trữ trên nhiều OSD để đảm bảo sự an toàn của dữ liệu.<rule_name>là tên của rule CRUSH mà pool sẽ sử dụng để phân phối dữ liệu giữa các OSD. Rule CRUSH xác định cách mà Ceph phân phối dữ liệu giữa các OSD.
Tính toán số lượng PG.
Số lượng placement groups (PGs) trong một pool Ceph có ảnh hưởng đến hiệu suất và độ chính xác của việc phân phối dữ liệu. Việc cân nhắc giữa hiệu suất và độ chính xác thường liên quan đến việc chọn số lượng placement groups (PGs) cho mỗi pool.
- Ưu tiên hiệu suất: Nếu bạn muốn tối ưu hiệu suất, bạn có thể muốn giảm số lượng PGs. Một số lượng PGs nhỏ hơn có thể giảm overhead cho quá trình quản lý của Ceph, giúp tăng hiệu suất. Tuy nhiên, điều này có thể làm giảm độ chính xác của việc phân phối dữ liệu.
- Ưu tiên độ chính xác: Nếu bạn muốn tối ưu độ chính xác của việc phân phối dữ liệu, bạn có thể muốn tăng số lượng PGs. Một số lượng PGs lớn hơn có thể giúp dữ liệu được phân phối đều hơn giữa các OSDs. Tuy nhiên, điều này có thể tạo ra overhead cho quá trình quản lý của Ceph và làm giảm hiệu suất.
Một quy tắc thô thông thường là mục tiêu khoảng 100 PGs cho mỗi OSD. Tuy nhiên, số lượng PGs cần phải là một số mũ của 2 (ví dụ, 1024, 2048, 4096, v.v.).
Để tính toán số lượng PGs tối ưu, bạn có thể sử dụng công thức sau:
pg_num = (total_osd * 100) / max_replication_countTrong đó:
total_osdlà tổng số OSDs trong cụm của bạn.max_replication_countlà số lượng bản sao tối đa của mỗi object, thường là 3 trong một cụm Ceph chịu lỗi.
Sau đó, làm tròn pg_num lên đến gần nhất số mũ của 2.
Ví dụ, trường hợp bài lab của mình đang có 15 OSDs và mỗi object được sao chép 2 lần, mình sẽ tính toán số lượng PGs như sau:
pg_num = (15 * 100) / 2 = 750Số mũ của 2 gần nhất với 750 là 1024, vì vậy bạn sẽ chọn 1024 làm số lượng PGs.
pg_num = (15 * 100) / 2 = 750Lưu ý rằng Số lượng placement groups (PGs) trong một pool Ceph không trực tiếp phụ thuộc vào dung lượng của disk hay OSD. Tuy nhiên, nó có liên quan đến số lượng OSDs trong cụm của bạn.
Tạo pool.
Dựa trên thông tin đã tính toán ở trên, mình có 15 OSDs và mỗi object được sao chép 2 lần. Số lượng PGs tối ưu đã được tính toán là 1024.
Giả sử bạn muốn tạo một pool mới với tên là “my_new_pool” và sử dụng rule mặc định cho việc sao chép, bạn có thể sử dụng lệnh sau:
shell> ceph osd pool create CLUSTER_NAME-SSD-01 1024 1024 replicated replicated_ssd_01
pool 'CLUSTER_NAME-SSD-01' createdTrong đó:
CLUSTER_NAME-SSD-01là tên của pool mới.1024là số lượng PGs và PGP (Placement Group for Placement) – thường được đặt giống nhau để tránh cảnh báo.replicatedchỉ ra rằng pool này sẽ sử dụng kiểu sao chép.replicated_ssd_01là tên của rule sao chép. Trong trường hợp này, tôi đã giả định rằng bạn muốn sử dụng rule mặc định cho việc sao chép. Bạn có thể thay đổi nó tùy thuộc vào cấu hình cụ thể của cụm Ceph của bạn.
Nếu bạn tính toán sai, bạn có thể sẽ gặp lỗi như sau:
shell> ceph osd pool create CLUSTER_NAME-SSD-01 16384 16384 replicated replicated_ssd_01
Error ERANGE: pg_num 16384 size 3 for this pool would result in 3276 cumulative PGs per OSD (49152 total PG replicas on 15 'in' root OSDs by crush rule) which exceeds the mon_max_pg_per_osd value of 250Lỗi này xuất hiện khi số lượng placement groups (PGs) trên mỗi OSD vượt quá giới hạn được thiết lập bởi mon_max_pg_per_osd. Trong trường hợp này, giới hạn là 250 PGs trên mỗi OSD.
Đặt số lượng bản sao của mỗi object.
Lệnh ceph osd pool set <pool_name> size <replica_count> được sử dụng để đặt số lượng bản sao của mỗi object trong pool Ceph.
Trong Ceph, “size” đề cập đến số lượng bản sao của mỗi object được lưu trữ trong pool. Mặc định, Ceph sẽ sao chép mỗi object 3 lần (size = 3) để đảm bảo dữ liệu có thể chịu được lỗi. Tuy nhiên, bạn có thể thay đổi số lượng bản sao này bằng cách sử dụng lệnh ceph osd pool set.
Ví dụ:
ceph osd pool set CLUSTER_NAME-SSD-01 size 2Trong trường hợp này, lệnh ceph osd pool set CLUSTER_NAME-SSD-01 size 2 sẽ giảm số lượng bản sao của mỗi object trong pool “CLUSTER_NAME-SSD-01” xuống còn 2. Điều này có thể giúp tiết kiệm không gian lưu trữ, nhưng cũng có thể làm giảm khả năng chịu lỗi của dữ liệu.
Bạn có thể sử dụng lệnh ceph osd pool ls detail để liệt kê tất cả các pool trong cụm Ceph của bạn cùng với thông tin chi tiết về chúng.
shell> ceph osd pool ls detail
pool 1 '.mgr' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 28 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr
pool 2 'CLUSTER_NAME-SSD-01' replicated size 3 min_size 2 crush_rule 1 object_hash rjenkins pg_num 1024 pgp_num 1024 autoscale_mode on last_change 57 flags hashpspool stripe_width 0Nếu lệnh pool create đã hoạt động thành công, bạn sẽ thấy pool CLUSTER_NAME-SSD-01 trong danh sách, với 1024 placement groups và sử dụng rule replicated_ssd_01 để phân phối dữ liệu.
Lưu ý: Trong lệnh pool create, CLUSTER_NAME nên được thay thế bằng tên thực sự của cụm Ceph của bạn.
Cấu hình monitoring.
Lệnh ceph config set mgr mgr/prometheus/rbd_stats_pools <pool_name>được sử dụng để cấu hình Prometheus, một hệ thống giám sát và cảnh báo mã nguồn mở, để thu thập thống kê từ pool RBD (RADOS Block Device) có tên là <pool_name> trong cụm Ceph.
Trong Ceph, RBD là một giao diện cho phép Ceph block devices được gắn kết như một block device trên máy chủ Linux. RBD hỗ trợ snapshot, sao chép và tính năng chia sẻ đồng thời, giúp nó trở thành lựa chọn tốt cho việc lưu trữ block-level trong môi trường cloud.
mgr/prometheus/rbd_stats_pools là một cấu hình của Ceph Manager (mgr) module cho Prometheus. Nó xác định các pool RBD mà Prometheus sẽ thu thập thống kê.
Ví dụ, trong trường hợp này, chỉ có pool “CLUSTER_NAME-SSD-01” được cấu hình để thu thập thống kê.
ceph config set mgr mgr/prometheus/rbd_stats_pools CLUSTER_NAME-SSD-01Kích hoạt RBD (RADOS Block Device).
Trong Ceph, một ứng dụng không phải là một ứng dụng phần mềm truyền thống, mà là một cách để gắn nhãn pool với một loại dữ liệu cụ thể. Các ứng dụng thường gặp bao gồm “rbd” cho RADOS Block Devices, “rgw” cho RADOS Gateway và “cephfs” cho Ceph Filesystem.
RBD là một giao diện cho phép Ceph block devices được gắn kết như một block device trên máy chủ Linux. RBD hỗ trợ snapshot, sao chép và tính năng chia sẻ đồng thời, giúp nó trở thành lựa chọn tốt cho việc lưu trữ block-level trong môi trường cloud.
Khi bạn kích hoạt ứng dụng RBD trên một pool, bạn đang thông báo cho Ceph rằng pool này sẽ được sử dụng để lưu trữ dữ liệu RBD. Điều này giúp Ceph tối ưu hóa việc quản lý dữ liệu và cung cấp thông tin hữu ích cho người quản trị.
Lệnh ceph osd pool application enable <pool_name> rbd được sử dụng để kích hoạt ứng dụng RBD (RADOS Block Device) trên pool Ceph có tên là <pool_name>.
Ví dụ.
shell> ceph osd pool application enable CLUSTER_NAME-SSD-01 rbd
enabled application 'rbd' on pool 'CLUSTER_NAME-SSD-01'Config chung áp dụng cho toàn cluster.
Dưới đây là một số config chung áp dụng phạm vi 1 cluster.
ceph config set global osd_pool_default_size 2
ceph osd pool set .mgr size 2
ceph config set global osd_pool_default_pg_autoscale_mode off
ceph config set global log_to_file true
ceph config set global mon_cluster_log_to_file true
ceph config set global log_to_stderr false
ceph config set global mon_cluster_log_to_stderr false
ceph config set global log_to_journald false
ceph config set global mon_cluster_log_to_journald false
ceph config set mon mon_memory_target 32G
ceph dashboard feature disable nfs rgw cephfs iscsi
ceph config set mon auth_allow_insecure_global_id_reclaim true
ceph config set global mon_osd_down_out_subtree_limit host
ceph config set mon mon_pg_warn_max_object_skew 0.5
ceph config set mon auth_allow_insecure_global_id_reclaim true
ceph config set mon mon_warn_on_insecure_global_id_reclaim_allowed falseTrong đó:
ceph config set global osd_pool_default_size 2: Đặt số lượng bản sao mặc định của mỗi object trong tất cả các pool mới thành 2.ceph osd pool set .mgr size 2: Đặt số lượng bản sao của mỗi object trong pool .mgr thành 2.ceph config set global osd_pool_default_pg_autoscale_mode off: Tắt chế độ tự động điều chỉnh số lượng placement groups (PGs) cho tất cả các pool mới.ceph config set global log_to_file true: Kích hoạt ghi log vào file cho toàn bộ cluster.ceph config set global mon_cluster_log_to_file true: Kích hoạt ghi log của monitor vào file cho toàn bộ cluster.ceph config set global log_to_stderr falsevàceph config set global mon_cluster_log_to_stderr false: Tắt ghi log vào stderr cho toàn bộ cluster và cho monitor.ceph config set global log_to_journald falsevàceph config set global mon_cluster_log_to_journald false: Tắt ghi log vào journald cho toàn bộ cluster và cho monitor.ceph config set mon mon_memory_target 32G: Đặt mục tiêu sử dụng bộ nhớ cho monitor là 32GB.ceph dashboard feature disable nfs rgw cephfs iscsi: Tắt các tính năng nfs, rgw, cephfs, và iscsi trên dashboard.ceph config set mon auth_allow_insecure_global_id_reclaim true: Cho phép việc lấy lại ID global một cách không an toàn.ceph config set global mon_osd_down_out_subtree_limit host: Đặt giới hạn subtree cho việc xử lý OSDs bị down hoặc out là host.ceph config set mon mon_pg_warn_max_object_skew 0.5: Đặt giới hạn cảnh báo cho sự chênh lệch object tối đa trên mỗi PG là 0.5.ceph config set mon mon_warn_on_insecure_global_id_reclaim_allowed false: Tắt cảnh báo khi cho phép lấy lại ID global một cách không an toàn.
Kiểm tra lại toàn bộ trạng thái cluster.
Sử dụng các lệnh dưới kiểm tra lại trạng thái cluster sau khi triển khai xong cụm Ceph nhé.
ceph orch ls: Liệt kê tất cả các dịch vụ được quản lý bởi Ceph Orchestrator.ceph orch ps: Liệt kê tất cả các daemons được quản lý bởi Ceph Orchestrator.ceph orch device ls: Liệt kê tất cả các thiết bị được Ceph Orchestrator biết đến.ceph -s: Hiển thị tình trạng tổng quan của cluster Ceph.ceph health detail: Hiển thị thông tin chi tiết về tình trạng sức khỏe của cluster Ceph.ceph osd tree: Hiển thị cấu trúc cây của các OSD (Object Storage Daemons) trong cluster.ceph df: Hiển thị thông tin về việc sử dụng không gian lưu trữ của cluster và các pool.ceph osd pool ls: Liệt kê tất cả các pool trong cluster.ceph config dump: Hiển thị tất cả các cấu hình hiện tại của cluster.ceph config get osd.1: Hiển thị cấu hình cho OSD có ID là 1.ceph config show osd.1: Hiển thị cấu hình hiện tại cho OSD có ID là 1.ceph osd crush rule ls: Liệt kê tất cả các quy tắc CRUSH trong cluster.ceph osd crush rule dump: Hiển thị thông tin chi tiết về tất cả các quy tắc CRUSH.
