1. Tổng quan.
Khi chúng ta có nhu cầu mở rộng site hoặc dung lượng thì chúng ta cần phải thêm node cùng với các ổ đĩa OSD mới. Quy trình thêm Node OSD vào Cluster Ceph sử dụng Container mình tóm tắt sơ qua thông thường sẽ bao gồm các bước sau:
Chuẩn bị Node OSD: Cài đặt hệ điều hành và cấu hình mạng cho Node OSD mới. Đảm bảo rằng nó có thể truy cập được tới các node khác trong cụm Ceph.
Cài đặt Docker hoặc Podman: Cài đặt Docker hoặc Podman trên Node OSD mới để có thể chạy Ceph dưới dạng các container.
Chạy Ceph OSD Container: Sử dụng lệnh docker run hoặc podman run để chạy container Ceph OSD. Trong lệnh này, bạn sẽ cần chỉ định các thông số như ID của cụm Ceph, keyring và đường dẫn tới ổ đĩa hoặc partition dùng để lưu trữ dữ liệu.
Thêm Node OSD vào CRUSH Map: Sử dụng lệnh ceph osd crush add để thêm Node OSD mới vào CRUSH map. CRUSH map là cấu trúc dữ liệu mà Ceph sử dụng để xác định cách phân phối dữ liệu trên các OSD.
Kiểm tra Node OSD: Sử dụng lệnh ceph osd tree để kiểm tra xem Node OSD mới đã được thêm vào cụm Ceph thành công hay chưa.
2. Sơ đồ.
Ví dụ dưới đây sẽ thêm ceph-osd4 với ip 10.237.7.87 vào cụm Ceph đang có với sơ đồ sau:
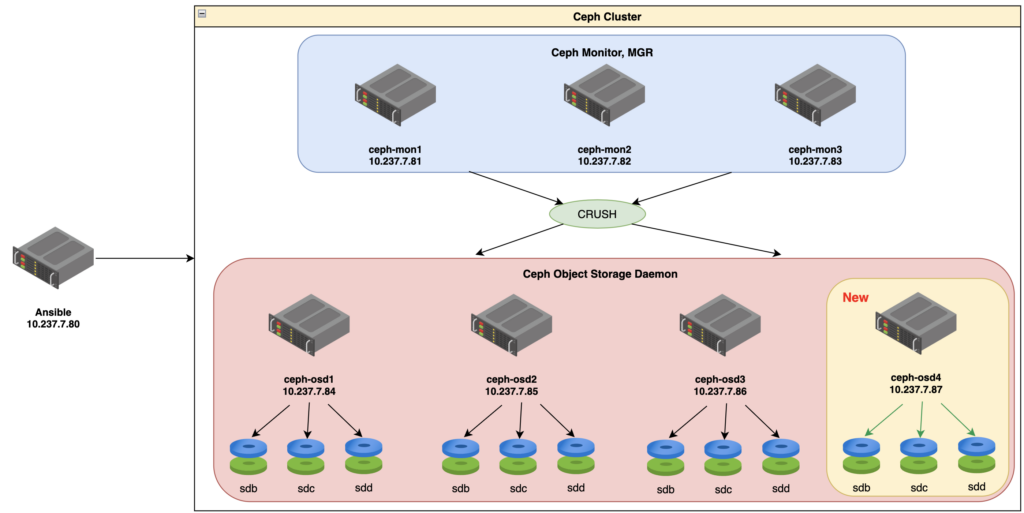
3. Chạy Ansible cài cắm và config các gói cơ bản.
Bổ sung thông tin của ceph-osd4 vào file SITE_NAME.CLUSTER_NAME. Do chúng ta thêm Node OSD nên mình sẽ thêm ceph-osd4 alias=LAB-87 ansible_host=10.237.7.87 vào group [ceph_osd]. Tất cả các trường khác bạn giữ nguyên.
[ceph_admin]
[ceph_mon]
ceph-mon1 alias=LAB-81 ansible_host=10.237.7.81
ceph-mon2 alias=LAB-82 ansible_host=10.237.7.82
ceph-mon3 alias=LAB-83 ansible_host=10.237.7.83
[ceph_osd]
ceph-osd1 alias=LAB-84 ansible_host=10.237.7.84
ceph-osd2 alias=LAB-85 ansible_host=10.237.7.85
ceph-osd3 alias=LAB-86 ansible_host=10.237.7.86
ceph-osd4 alias=LAB-87 ansible_host=10.237.7.87
[ceph:children]
ceph_admin
ceph_mon
ceph_osd
[ceph:vars]
ceph_version=quincy
ceph_image="10.237.7.83:5000/ceph/ceph:v17.2.6"
ceph_registry_host="10.237.7.83:5000"
organization='LAB'
site="SITE_NAME"
cluster="CLUSTER_NAME"
admin_nodes="10.237.7.81"
# Proxy
http_proxy="http://10.237.7.250:3128"
https_proxy="http://10.237.7.250:3128"Chạy playbook, truyền thông tin xác thực của bạn vào và nhớ truyền tham số --limit ceph-osd4 để chỉ truyển khai trên ceph-osd4 thông nhé.
ansible-playbook -i hosts.SITE_NAME.CLUSTER_NAME -u root --key-file ~/.ssh/id_rsa -b --ask-become-pass playbook.yml --extra-vars "force_ansible=yes" --limit ceph-osd4Thông báo khi bạn chạy playbook thành công.
shell> ansible-playbook -i hosts.SITE_NAME.CLUSTER_NAME -u root --key-file ~/.ssh/id_rsa -b --ask-become-pass playbook.yml --extra-vars "force_ansible=yes" --limit ceph-osd4
BECOME password:
[WARNING]: While constructing a mapping from /home/vng-ceph-ansible-ubuntu22/playbook.yml, line 2, column 3, found a duplicate dict key (pre_tasks). Using last defined value only.
PLAY [all] **********************************************************************************************************************************************************************************************************************************************************
TASK [ICMP Ping Check to Host] **************************************************************************************************************************************************************************************************************************************
ok: [ceph-osd4]
TASK [debug] ********************************************************************************************************************************************************************************************************************************************************
ok: [ceph-osd4] => {
"msg": "You are acting the 'CLUSTER_NAME' cluster at 'SITE_NAME', name ceph-osd4 , ansible_host 10.237.7.87 "
}
TASK [Checking this is the first-time run ansible] ******************************************************************************************************************************************************************************************************************
ok: [ceph-osd4]
TASK [Checking if this host was ansibled] ***************************************************************************************************************************************************************************************************************************
ok: [ceph-osd4] => {
"msg": "This is the FIRST-TIME running ansible on this host"
}
<đã lược bỏ bớt logs>
RUNNING HANDLER [tuning : restart udev] *****************************************************************************************************************************************************************************************************************************
changed: [ceph-osd4]
TASK [Ansible create file if it doesn't exist example] **************************************************************************************************************************************************************************************************************
changed: [ceph-osd4]
PLAY RECAP **********************************************************************************************************************************************************************************************************************************************************
ceph-osd4 : ok=78 changed=61 unreachable=0 failed=0 skipped=5 rescued=0 ignored=0Chạy playbook tiếp theo để trỏ file hosts thêm thông tin mới cho toàn bộ Node trong cluster.
ansible-playbook -i hosts.SITE_NAME.CLUSTER_NAME -u cephadmin --key-file /home/hoanghd/.ssh/id_rsa -b --ask-become-pass playbook.yml --extra-vars "force_ansible=yes" --tags "common:dns"Thông báo khi bạn chạy playbook thành công.
shell> ansible-playbook -i hosts.SITE_NAME.CLUSTER_NAME -u cephadmin --key-file /home/hoanghd/.ssh/id_rsa -b --ask-become-pass playbook.yml --extra-vars "force_ansible=yes" --tags "common:dns"
BECOME password:
[WARNING]: While constructing a mapping from /home/vng-ceph-ansible-ubuntu22/playbook.yml, line 2, column 3, found a duplicate dict key (pre_tasks). Using last defined value only.
PLAY [all] **********************************************************************************************************************************************************************************************************************************************************
TASK [ICMP Ping Check to Host] **************************************************************************************************************************************************************************************************************************************
ok: [ceph-mon3]
ok: [ceph-mon2]
ok: [ceph-mon1]
ok: [ceph-osd2]
ok: [ceph-osd1]
ok: [ceph-osd4]
ok: [ceph-osd3]
<Đã lược bỏ bớt logs>
TASK [common : Create /etc/hosts for region CLUSTER_NAME cho role mon] **********************************************************************************************************************************************************************************************
skipping: [ceph-mon1]
skipping: [ceph-mon2]
skipping: [ceph-mon3]
skipping: [ceph-osd1]
skipping: [ceph-osd2]
skipping: [ceph-osd3]
skipping: [ceph-osd4]
TASK [tuning : Tuning theo role mon] ********************************************************************************************************************************************************************************************************************************
included: /home/vng-ceph-ansible-ubuntu22/roles/tuning/tasks/role-osd.yaml for ceph-osd1, ceph-osd2, ceph-osd3, ceph-osd4
PLAY RECAP **********************************************************************************************************************************************************************************************************************************************************
ceph-mon1 : ok=6 changed=1 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
ceph-mon2 : ok=5 changed=1 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
ceph-mon3 : ok=5 changed=1 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
ceph-osd1 : ok=6 changed=1 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
ceph-osd2 : ok=6 changed=2 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
ceph-osd3 : ok=6 changed=1 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0
ceph-osd4 : ok=6 changed=0 unreachable=0 failed=0 skipped=1 rescued=0 ignored=0Bạn có thể check lại một số node trong cluster để chắc chắn thông tin của node mới 10.237.7.87 ceph-osd4 LAB-87 đã được thêm thành công.
shell> cat /etc/hosts
127.0.0.1 localhost
127.0.1.1 ubuntu2204
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
#*** BEGIN - HOSTS ADDED WITH ANSIBLE ***
10.237.7.81 ceph-mon1 LAB-81
10.237.7.82 ceph-mon2 LAB-82
10.237.7.83 ceph-mon3 LAB-83
10.237.7.84 ceph-osd1 LAB-84
10.237.7.85 ceph-osd2 LAB-85
10.237.7.86 ceph-osd3 LAB-86
10.237.7.87 ceph-osd4 LAB-87
#*** END - HOSTS ADDED WITH ANSIBLE ***4. Kiểm tra trạng thái Cluster và Node mới trước khi thêm vào Cluster.
Trước lúc thay đổi hệ thống, nhất là hệ thống lớn chạy mô hình cluster. Chúng ta nên tập thói quen review 1 vòng về cluster đang chạy trước khi thay đổi nó.
Kiểm tra trạng thái Cluster.
shell> ceph -s
cluster:
id: 4d726630-1bd4-11ef-ac2d-013818cf3990
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-mon1,ceph-mon2,ceph-mon3 (age 5h)
mgr: ceph-mon1.kqyjql(active, since 5h), standbys: ceph-mon2.gmtarc, ceph-mon3.zngjzp
osd: 15 osds: 15 up (since 4h), 15 in (since 4h)
data:
pools: 2 pools, 1025 pgs
objects: 2 objects, 449 KiB
usage: 146 MiB used, 450 GiB / 450 GiB avail
pgs: 1025 active+cleanXem quá trình phục hồi và backfill của OSD (Object Storage Daemon) ở thời điểm hiện tại.
Lệnh ceph config dump | grep -iE "osd_recovery_max_active_ssd|osd_mclock_profile|osd_mclock_override_recovery_settings|osd_max_backfills" được sử dụng để lọc và hiển thị các cấu hình cụ thể của Ceph liên quan đến quá trình phục hồi và backfill của OSD (Object Storage Daemon).
Những giá trị này có thể được điều chỉnh để tối ưu hóa hiệu suất và độ tin cậy của cụm Ceph của bạn.
shell> ceph config dump | grep -iE "osd_recovery_max_active_ssd|osd_mclock_profile|osd_mclock_override_recovery_settings|osd_max_backfills"
osd advanced osd_max_backfills 2
osd advanced osd_mclock_override_recovery_settings true
osd advanced osd_mclock_profile high_client_ops
osd advanced osd_recovery_max_active_ssd 2Cụ thể:
osd_recovery_max_active_ssd: Đây là số lượng tối đa các hoạt động phục hồi đồng thời trên mỗi OSD cho SSD.osd_mclock_profile: Đây là hồ sơ mClock được sử dụng, mClock là một thuật toán lập lịch I/O.osd_mclock_override_recovery_settings: Nếu được đặt thành true, các cài đặt phục hồi mClock sẽ ghi đè lên các cài đặt phục hồi mặc định.osd_max_backfills: Đây là số lượng tối đa các hoạt động backfill đồng thời trên mỗi OSD.
Kết quả trên sẽ cho thấy các giá trị cấu hình hiện tại của Ceph cho các tùy chọn liên quan đến quá trình phục hồi và backfill của OSD (Object Storage Daemon):
osd_max_backfills: Giá trị này cho biết số lượng tối đa các hoạt động backfill đồng thời trên mỗi OSD là 2.osd_mclock_override_recovery_settings: Giá trị này cho biết các cài đặt phục hồi mClock có được ghi đè lên các cài đặt phục hồi mặc định hay không. Trong trường hợp này, giá trị làtrue, tức là các cài đặt phục hồi mClock sẽ ghi đè lên các cài đặt phục hồi mặc định.osd_mclock_profile: Giá trị này cho biết hồ sơ mClock hiện tại đang được sử dụng làhigh_client_ops. mClock là một thuật toán lập lịch I/O.osd_recovery_max_active_ssd: Giá trị này cho biết số lượng tối đa các hoạt động phục hồi đồng thời trên mỗi OSD cho SSD là 2.
Kiểm tra toàn bộ node đang có trong cluster.
Sử dụng lệnh ceph orch host ls để xem các node đang tồn tại trong cluster.
shell> ceph orch host ls
HOST ADDR LABELS STATUS
ceph-mon1 10.237.7.81 _admin mon mgr
ceph-mon2 10.237.7.82 _admin mon mgr
ceph-mon3 10.237.7.83 _admin mon mgr
ceph-osd1 10.237.7.84 osd
ceph-osd2 10.237.7.85 osd
ceph-osd3 10.237.7.86 osd
6 hosts in clusterBạn cũng nên vỉew qua thông tin của OSD Type.
shell> ceph orch ls --export --service-type osd
service_type: osd
service_id: osd_SSD_30GB
service_name: osd.osd_SSD_30GB
placement:
host_pattern: '*'
label: osd
spec:
data_devices:
rotational: 0
size: 10G:40G
filter_logic: AND
objectstore: bluestore
osds_per_device: 1Xem thông tin của Ceph pool.
Lệnh ceph df được sử dụng để hiển thị thông tin về việc sử dụng lưu trữ trong cụm Ceph. Nó cung cấp một cái nhìn tổng quan về việc sử dụng lưu trữ trên tất cả các pools và các OSD (Object Storage Daemons).
shell> ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
ssd 450 GiB 450 GiB 146 MiB 146 MiB 0.03
TOTAL 450 GiB 450 GiB 146 MiB 146 MiB 0.03
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
.mgr 1 1 1.1 MiB 2 2.2 MiB 0 214 GiB
CLUSTER_NAME-SSD-01 2 1024 0 B 0 0 B 0 142 GiBKiểm tra kết nối icmp, time response, ttl.
shell> ping -c 6 ceph-osd4
PING ceph-osd4 (10.237.7.87) 56(84) bytes of data.
64 bytes from ceph-osd4 (10.237.7.87): icmp_seq=1 ttl=64 time=0.107 ms
64 bytes from ceph-osd4 (10.237.7.87): icmp_seq=2 ttl=64 time=0.121 ms
64 bytes from ceph-osd4 (10.237.7.87): icmp_seq=3 ttl=64 time=0.119 ms
64 bytes from ceph-osd4 (10.237.7.87): icmp_seq=4 ttl=64 time=0.114 ms
64 bytes from ceph-osd4 (10.237.7.87): icmp_seq=5 ttl=64 time=0.136 ms
64 bytes from ceph-osd4 (10.237.7.87): icmp_seq=6 ttl=64 time=0.104 ms
--- ceph-osd4 ping statistics ---
6 packets transmitted, 6 received, 0% packet loss, time 5121ms
rtt min/avg/max/mdev = 0.104/0.116/0.136/0.010 msKiểm tra xem máy chủ có đủ điều kiện để chạy Cephadm hay không?
Lệnh cephadm check-host được sử dụng để kiểm tra xem một máy chủ có đủ điều kiện để chạy Cephadm hay không. Cephadm là một công cụ giúp cài đặt, cấu hình và quản lý cụm Ceph.
Khi bạn chạy lệnh cephadm check-host, nó sẽ kiểm tra các điều kiện sau:
podmanhoặcdocker: Cephadm sử dụng container để chạy các dịch vụ Ceph, vì vậy nó cần một công cụ quản lý container như Podman hoặc Docker. Trong trường hợp của bạn, Podman đã được cài đặt và phiên bản là 3.4.4.systemctl: Cephadm sử dụng systemd để quản lý và giám sát các dịch vụ Ceph, vì vậy nó cần systemctl.lvcreate: Cephadm có thể sử dụng LVM để quản lý các ổ đĩa, vì vậy nó cần lvcreate.ntp.service: Để đảm bảo rằng thời gian trên tất cả các máy chủ đều được đồng bộ, Cephadm cần dịch vụ NTP. Trong trường hợp của bạn, dịch vụ NTP đã được kích hoạt và đang chạy.
Nếu tất cả các điều kiện trên đều được thỏa mãn, lệnh sẽ in ra “Host looks OK”, cho biết máy chủ đã sẵn sàng để chạy Cephadm.
shell> cephadm check-host
podman (/usr/bin/podman) version 3.4.4 is present
systemctl is present
lvcreate is present
Unit ntp.service is enabled and running
Host looks OKBạn cũng nên kiểm tra card mạng của bạn có sẵn sàng và đáp ứng được nhu cầu cho một storage không nhé.
shell> ethtool eno12399 | grep -E "Link detected|Speed"
Speed: 25000Mb/s
Link detected: yes
shell> ethtool eno12409 | grep -E "Link detected|Speed"
Speed: 25000Mb/s
Link detected: yes
shell> ethtool bond0 | grep -E "Link detected|Speed"
Speed: 50000Mb/s
Link detected: yesZAP device all in OSD node (ceph-osd4).
Trước khi thêm một OSD (Object Storage Daemon) mới vào cụm Ceph, việc “zapping” (xóa tất cả dữ liệu và cấu hình) các thiết bị lưu trữ trên node OSD là một bước quan trọng để đảm bảo rằng không có dữ liệu hoặc cấu hình cũ nào còn tồn tại có thể gây rối hoặc xung đột với việc cài đặt và cấu hình OSD mới.
Cụ thể, việc zapping một thiết bị sẽ thực hiện các công việc sau:
- Xóa tất cả dữ liệu trên thiết bị, bao gồm cả dữ liệu người dùng và dữ liệu hệ thống.
- Xóa tất cả các phân vùng trên thiết bị.
- Xóa tất cả các dấu vết của bất kỳ hệ thống file nào đã được tạo trên thiết bị.
- Xóa tất cả các dấu vết của bất kỳ hệ thống Ceph nào đã sử dụng thiết bị.
Để zap disk bạn có thể sử dụng một trong 2 công cụ sgdisk hoặc ceph-volume. Nếu sử dụng ceph-volume và ceph-common bạn cần cài đặt nó bằng lệnh dưới. Nếu sử dụng sgdisk thì bạn không cần cài đặt gì thêm vì đây là công cụ có sẵn trên Linux.
apt install ceph-volume ceph-common -yCú pháp zap disk với sgdisk là sgdisk –zap-all /dev/<device_name>.
Ví dụ:
sgdisk --zap-all /dev/sdb
sgdisk --zap-all /dev/sdc
sgdisk --zap-all /dev/sdd
sgdisk --zap-all /dev/sde
sgdisk --zap-all /dev/sdfVí dụ output của lệnh sgdisk.
shell> sgdisk --zap-all /dev/sdb
Creating new GPT entries in memory.
GPT data structures destroyed! You may now partition the disk using fdisk or
other utilities.Đối với ceph-volume sử dụng cú pháp ceph-volume lvm zap /dev/<device_name> hoặc ceph-volume lvm zap /dev/<device_name> --destroy.
ceph-volume lvm zap /dev/sdb --destroy
ceph-volume lvm zap /dev/sdc --destroy
ceph-volume lvm zap /dev/sdd --destroy
ceph-volume lvm zap /dev/sde --destroy
ceph-volume lvm zap /dev/sdf --destroyDưới đây là ví dụ cho output của ceph-volume.
shell> ceph-volume lvm zap /dev/sdb --destroy
--> Zapping: /dev/sdb
Running command: /usr/bin/dd if=/dev/zero of=/dev/sdb bs=1M count=10 conv=fsync
stderr: 10+0 records in
10+0 records out
10485760 bytes (10 MB, 10 MiB) copied, 0.0692594 s, 151 MB/s
stderr:
--> Zapping successful for: <Raw Device: /dev/sdb>Kết quả sau khi zap phải như thế này.
shell> lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
loop0 7:0 0 62M 1 loop /snap/core20/1587
loop1 7:1 0 79.9M 1 loop /snap/lxd/22923
loop2 7:2 0 47M 1 loop /snap/snapd/16292
sda 8:0 0 447.1G 0 disk
├─sda1 8:1 0 1G 0 part /boot/efi
├─sda2 8:2 0 2G 0 part /boot
└─sda3 8:3 0 444G 0 part
└─ubuntu--vg-ubuntu--lv 253:0 0 100G 0 lvm /
sdb 259:1 0 30G 0 disk
sdc 259:1 0 30G 0 disk
sdd 259:1 0 30G 0 disk
sde 259:1 0 30G 0 disk
sdf 259:1 0 30G 0 diskSau khi zapping, thiết bị sẽ ở trong trạng thái sạch, giống như khi nó mới xuất xưởng và sẵn sàng để cài đặt và cấu hình OSD mới.
Lưu ý: Nếu là ổ đĩa mới chưa sử dụng lần nào bạn có thể bỏ qua bước zip disk.
5. Tiến hành Join Node mới vào Cluster.
Lệnh ceph orch host add được sử dụng để thêm một máy chủ vào cụm Ceph.
shell> ceph orch host add ceph-osd4 10.237.7.87 osd _no_schedule
Added host 'ceph-osd4' with addr '10.237.7.87'Trong câu lệnh này nó có ý nghĩa như sau:
ceph-osd4là tên của máy chủ bạn muốn thêm vào cụm.10.237.7.87là địa chỉ IP của máy chủ.osdlà vai trò của máy chủ trong cụm. Trong trường hợp này, máy chủ sẽ hoạt động như một Object Storage Daemon (OSD), đó là nơi dữ liệu thực sự được lưu trữ trong cụm Ceph._no_schedulelà một label được gán cho máy chủ. Label này có nghĩa là không có dịch vụ mới nào sẽ được lên lịch để chạy trên máy chủ này cho đến khi label này được gỡ bỏ.
Vì vậy, lệnh này thêm máy chủ ceph-osd4 với địa chỉ IP 10.237.7.87 vào cụm Ceph như một OSD và gán label _no_schedule cho nó.
Sử dụng lệnh ceph orch device ls ceph-osd4 để liệt kê các thiết bị lưu trữ trên máy chủ ceph-osd4. Bạn sẽ thấy danh sách các ổ đĩa sẽ được thêm vào cluster làm sử dụng cho dịch vụ OSD.
shell> ceph orch device ls ceph-osd4
HOST PATH TYPE DEVICE ID SIZE AVAILABLE REFRESHED REJECT REASONS
ceph-osd4 /dev/sdb ssd 32.2G Yes 13s ago
ceph-osd4 /dev/sdc ssd 32.2G Yes 13s ago
ceph-osd4 /dev/sdd ssd 32.2G Yes 13s ago
ceph-osd4 /dev/sde ssd 32.2G Yes 13s ago
ceph-osd4 /dev/sdf ssd 32.2G Yes 13s agoTriển khai OSD trên ceph-osd4.
Sử dụng lệnh ceph orch host label rm để xóa một label từ một máy chủ trong cụm Ceph.
shell> ceph orch host label rm ceph-osd4 _no_schedule
Removed label _no_schedule from host ceph-osd4Trong đó:
ceph-osd4là tên của máy chủ mà bạn muốn xóa label._no_schedulelà label mà bạn muốn xóa.
Vì vậy, lệnh này xóa label _no_schedule khỏi máy chủ ceph-osd4.
Label _no_schedule thường được sử dụng để ngăn Ceph Orchestrator lên lịch chạy dịch vụ mới trên máy chủ. Khi bạn xóa label này, Ceph Orchestrator có thể bắt đầu lên lịch chạy dịch vụ mới trên máy chủ.
Remote vào ceph-osd4 kiểm tra và chắc chắn các pod liên quan đến dịch vụ OSD của ceph-osd4 đã ở trạng thái running.
shell> podman ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6952467b43e1 10.237.7.83:5000/ceph/ceph@sha256:86f3a1cb9b4ea008df94f1eba06f7bf60b51078dce1d0649840f061510b5512e -n client.crash.c... 3 minutes ago Up 3 minutes ago ceph-4d726630-1bd4-11ef-ac2d-013818cf3990-crash-ceph-osd4
88536245982b 10.237.7.83:5000/ceph/ceph@sha256:86f3a1cb9b4ea008df94f1eba06f7bf60b51078dce1d0649840f061510b5512e -n osd.0 -f --set... 2 minutes ago Up 2 minutes ago ceph-4d726630-1bd4-11ef-ac2d-013818cf3990-osd-0
e8205798cb5c 10.237.7.83:5000/ceph/ceph@sha256:86f3a1cb9b4ea008df94f1eba06f7bf60b51078dce1d0649840f061510b5512e -n osd.16 -f --se... 2 minutes ago Up 2 minutes ago ceph-4d726630-1bd4-11ef-ac2d-013818cf3990-osd-16
b68a75cc68df 10.237.7.83:5000/ceph/ceph@sha256:86f3a1cb9b4ea008df94f1eba06f7bf60b51078dce1d0649840f061510b5512e -n osd.17 -f --se... 2 minutes ago Up 2 minutes ago ceph-4d726630-1bd4-11ef-ac2d-013818cf3990-osd-17
fa6d4337b503 10.237.7.83:5000/ceph/ceph@sha256:86f3a1cb9b4ea008df94f1eba06f7bf60b51078dce1d0649840f061510b5512e -n osd.18 -f --se... 2 minutes ago Up 2 minutes ago ceph-4d726630-1bd4-11ef-ac2d-013818cf3990-osd-18
3279d1f6cc70 10.237.7.83:5000/ceph/ceph@sha256:86f3a1cb9b4ea008df94f1eba06f7bf60b51078dce1d0649840f061510b5512e -n osd.19 -f --se... 2 minutes ago Up 2 minutes ago ceph-4d726630-1bd4-11ef-ac2d-013818cf3990-osd-19Sử dụng lệnh ceph -s để kiểm tra lại trạng thái cluster, số lượng OSD đã tăng từ 15 lên 20 OSDs.
shell> ceph -s
cluster:
id: 4d726630-1bd4-11ef-ac2d-013818cf3990
health: HEALTH_OK
clock skew detected on mon.ceph-mon2, mon.ceph-mon3
services:
mon: 3 daemons, quorum ceph-mon1,ceph-mon2,ceph-mon3 (age 6h)
mgr: ceph-mon2.gmtarc(active, since 3h), standbys: ceph-mon1.kqyjql, ceph-mon3.zngjzp
osd: 20 osds: 20 up (since 3m), 20 in (since 4m)
data:
pools: 2 pools, 1025 pgs
objects: 2 objects, 449 KiB
usage: 204 MiB used, 600 GiB / 600 GiB avail
pgs: 1025 active+cleanSử dụng lệnh ceph osd tree bạn sẽ thấy node ceph-osd4 đang nằm tại rule default và đang trạng thái up.
shell> ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-10 0.14648 root default
-9 0.14648 host ceph-osd4
0 ssd 0.02930 osd.0 up 1.00000 1.00000
16 ssd 0.02930 osd.16 up 1.00000 1.00000
17 ssd 0.02930 osd.17 up 1.00000 1.00000
18 ssd 0.02930 osd.18 up 1.00000 1.00000
19 ssd 0.02930 osd.19 up 1.00000 1.00000
-1 0.43945 root ssd-01
-3 0.14648 host ceph-osd1
3 ssd 0.02930 osd.3 up 1.00000 1.00000
8 ssd 0.02930 osd.8 up 1.00000 1.00000
9 ssd 0.02930 osd.9 up 1.00000 1.00000
12 ssd 0.02930 osd.12 up 1.00000 1.00000
15 ssd 0.02930 osd.15 up 1.00000 1.00000
-7 0.14648 host ceph-osd2
2 ssd 0.02930 osd.2 up 1.00000 1.00000
4 ssd 0.02930 osd.4 up 1.00000 1.00000
6 ssd 0.02930 osd.6 up 1.00000 1.00000
11 ssd 0.02930 osd.11 up 1.00000 1.00000
14 ssd 0.02930 osd.14 up 1.00000 1.00000
-5 0.14648 host ceph-osd3
1 ssd 0.02930 osd.1 up 1.00000 1.00000
5 ssd 0.02930 osd.5 up 1.00000 1.00000
7 ssd 0.02930 osd.7 up 1.00000 1.00000
10 ssd 0.02930 osd.10 up 1.00000 1.00000
13 ssd 0.02930 osd.13 up 1.00000 1.00000Lưu ý quan trọng là các OSDs mới thêm vào của ceph-osd4 phải ở trạng thái up mới đủ điều kiện để qua bước tiếp theo nhé.
Reweight toàn bộ OSDs trên node mới ceph-osd4 về 0 weight.
Lệnh ceph osd crush reweight được sử dụng để thay đổi trọng số của một OSD (Object Storage Daemon) trong bản đồ CRUSH của Ceph.
Khi bạn thiết lập trọng số của một OSD thành 0 bằng lệnh ceph osd crush reweight osd.<id> 0, bạn đang nói với Ceph để không đặt dữ liệu mới nào trên OSD đó. Điều này hữu ích khi bạn muốn thêm một OSD mới hoặc một node chứa nhiều OSD mới vào cụm Ceph của mình.
Khi bạn thêm một OSD mới, nếu bạn cho phép Ceph phân phối dữ liệu một cách tự nhiên, nó có thể dẫn đến việc OSD mới nhận một lượng lớn dữ liệu ngay lập tức, điều này có thể làm quá tải OSD và làm giảm hiệu suất của cụm. Để tránh điều này, bạn có thể thêm OSD với trọng số 0, sau đó tăng trọng số lên từ từ, cho phép dữ liệu được phân phối một cách đồng đều hơn và giảm bớt sự ảnh hưởng đến hiệu suất.
ceph osd crush reweight osd.0 0
ceph osd crush reweight osd.16 0
ceph osd crush reweight osd.17 0
ceph osd crush reweight osd.18 0
ceph osd crush reweight osd.19 0 Output của lệnh reweight.
reweighted item id 0 name 'osd.0' to 0 in crush map
reweighted item id 16 name 'osd.16' to 0 in crush map
reweighted item id 17 name 'osd.17' to 0 in crush map
reweighted item id 18 name 'osd.18' to 0 in crush map
reweighted item id 19 name 'osd.19' to 0 in crush mapXác minh lại kết quả reweight cho các OSDs của ceph-osd4, lúc này các OSDs trên node này vẫn đang nằm ở rule default.
shell> ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-10 0 root default
-9 0 host ceph-osd4
0 ssd 0 osd.0 up 1.00000 1.00000
16 ssd 0 osd.16 up 1.00000 1.00000
17 ssd 0 osd.17 up 1.00000 1.00000
18 ssd 0 osd.18 up 1.00000 1.00000
19 ssd 0 osd.19 up 1.00000 1.00000
-1 0.43945 root ssd-01
-3 0.14648 host ceph-osd1
3 ssd 0.02930 osd.3 up 1.00000 1.00000
8 ssd 0.02930 osd.8 up 1.00000 1.00000
9 ssd 0.02930 osd.9 up 1.00000 1.00000
12 ssd 0.02930 osd.12 up 1.00000 1.00000
15 ssd 0.02930 osd.15 up 1.00000 1.00000
-7 0.14648 host ceph-osd2
2 ssd 0.02930 osd.2 up 1.00000 1.00000
4 ssd 0.02930 osd.4 up 1.00000 1.00000
6 ssd 0.02930 osd.6 up 1.00000 1.00000
11 ssd 0.02930 osd.11 up 1.00000 1.00000
14 ssd 0.02930 osd.14 up 1.00000 1.00000
-5 0.14648 host ceph-osd3
1 ssd 0.02930 osd.1 up 1.00000 1.00000
5 ssd 0.02930 osd.5 up 1.00000 1.00000
7 ssd 0.02930 osd.7 up 1.00000 1.00000
10 ssd 0.02930 osd.10 up 1.00000 1.00000
13 ssd 0.02930 osd.13 up 1.00000 1.00000Di chuyển node ceph-osd4 sang rule ssd-01.
Giờ đây mọi thứ đã sẵn sàng, bạn hãy di chuyển node này sang rule chính ssd-01 theo thiết kế hệ thống của bạn.
shell> ceph osd crush move ceph-osd4 root=ssd-01
moved item id -9 name 'ceph-osd4' to location {root=ssd-01} in crush mapKiểm tra daemons.
Lệnh ceph orch ps hiển thị thông tin về các dịch vụ Ceph đang chạy trên các host ceph-osd4.
shell> ceph orch ps ceph-osd4
NAME HOST PORTS STATUS REFRESHED AGE MEM USE MEM LIM VERSION IMAGE ID CONTAINER ID
crash.ceph-osd4 ceph-osd4 running (18m) 72s ago 18m 18.1M - 17.2.6 2747c7f13104 6952467b43e1
node-exporter.ceph-osd4 ceph-osd4 *:9100 error 72s ago 16m - - <unknown> <unknown> <unknown>
osd.0 ceph-osd4 running (17m) 72s ago 17m 50.7M 4096M 17.2.6 2747c7f13104 88536245982b
osd.16 ceph-osd4 running (17m) 72s ago 17m 46.4M 4096M 17.2.6 2747c7f13104 e8205798cb5c
osd.17 ceph-osd4 running (17m) 72s ago 17m 46.1M 4096M 17.2.6 2747c7f13104 b68a75cc68df
osd.18 ceph-osd4 running (17m) 72s ago 17m 46.4M 4096M 17.2.6 2747c7f13104 fa6d4337b503
osd.19 ceph-osd4 running (17m) 72s ago 17m 45.1M 4096M 17.2.6 2747c7f13104 3279d1f6cc70Trong đó:
NAME: Tên của dịch vụ. Đây có thể là một dịch vụ Ceph nhưosd.0hoặc một dịch vụ hỗ trợ nhưnode-exporter.HOST: Tên của host mà dịch vụ đang chạy trên đó.PORTS: Cổng mà dịch vụ đang lắng nghe. Trong trường hợp của bạn,node-exporterđang lắng nghe trên cổng 9100.STATUS: Trạng thái hiện tại của dịch vụ. Các giá trị có thể làrunning,error, v.v.REFRESHED: Thời gian kể từ lần cuối cùng thông tin về dịch vụ được cập nhật.AGE: Thời gian kể từ khi dịch vụ bắt đầu chạy.MEM USE: Lượng bộ nhớ mà dịch vụ đang sử dụng.MEM LIM: Giới hạn bộ nhớ cho dịch vụ. Nếu không có giới hạn, giá trị sẽ là-.VERSION: Phiên bản của dịch vụ.IMAGE ID: ID của image Docker mà dịch vụ đang sử dụng.CONTAINER ID: ID của container Docker mà dịch vụ đang chạy trong đó.
Nếu bạn sử dụng lệnh ceph osd tree bạn sẽ thấy ceph-node4 đã nằm trong rule ssd-01, weight là 0 và đang ở trạng thái up.
shell> ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-10 0 root default
-1 0.43945 root ssd-01
-3 0.14648 host ceph-osd1
3 ssd 0.02930 osd.3 up 1.00000 1.00000
8 ssd 0.02930 osd.8 up 1.00000 1.00000
9 ssd 0.02930 osd.9 up 1.00000 1.00000
12 ssd 0.02930 osd.12 up 1.00000 1.00000
15 ssd 0.02930 osd.15 up 1.00000 1.00000
-7 0.14648 host ceph-osd2
2 ssd 0.02930 osd.2 up 1.00000 1.00000
4 ssd 0.02930 osd.4 up 1.00000 1.00000
6 ssd 0.02930 osd.6 up 1.00000 1.00000
11 ssd 0.02930 osd.11 up 1.00000 1.00000
14 ssd 0.02930 osd.14 up 1.00000 1.00000
-5 0.14648 host ceph-osd3
1 ssd 0.02930 osd.1 up 1.00000 1.00000
5 ssd 0.02930 osd.5 up 1.00000 1.00000
7 ssd 0.02930 osd.7 up 1.00000 1.00000
10 ssd 0.02930 osd.10 up 1.00000 1.00000
13 ssd x osd.13 up 1.00000 1.00000
-9 0 host ceph-osd4
0 ssd 0 osd.0 up 1.00000 1.00000
16 ssd 0 osd.16 up 1.00000 1.00000
17 ssd 0 osd.17 up 1.00000 1.00000
18 ssd 0 osd.18 up 1.00000 1.00000
19 ssd 0 osd.19 up 1.00000 1.00000Giờ đây bạn có thể sử dụng lệnh reweight để tăng weight lên từ từ tuỳ vào hệ thống của bạn đáp ứng. Bạn có thể thiết kế 1 script nhỏ để làm việc này. Hiện tại đang là hệ thống lab và chưa có data nên mình sẽ reweight lên max cùng thông số với các node khác trong cluster luôn.
ceph osd crush reweight osd.0 0.02930
ceph osd crush reweight osd.16 0.02930
ceph osd crush reweight osd.17 0.02930
ceph osd crush reweight osd.18 0.02930
ceph osd crush reweight osd.19 0.02930Kết quả đầu ra.
reweighted item id 0 name 'osd.0' to 0.0293 in crush map
reweighted item id 16 name 'osd.16' to 0.0293 in crush map
reweighted item id 17 name 'osd.17' to 0.0293 in crush map
reweighted item id 18 name 'osd.18' to 0.0293 in crush map
reweighted item id 19 name 'osd.19' to 0.0293 in crush mapKết quả.
shell> ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-10 0 root default
-1 0.58594 root ssd-01
-3 0.14648 host ceph-osd1
3 ssd 0.02930 osd.3 up 1.00000 1.00000
8 ssd 0.02930 osd.8 up 1.00000 1.00000
9 ssd 0.02930 osd.9 up 1.00000 1.00000
12 ssd 0.02930 osd.12 up 1.00000 1.00000
15 ssd 0.02930 osd.15 up 1.00000 1.00000
-7 0.14648 host ceph-osd2
2 ssd 0.02930 osd.2 up 1.00000 1.00000
4 ssd 0.02930 osd.4 up 1.00000 1.00000
6 ssd 0.02930 osd.6 up 1.00000 1.00000
11 ssd 0.02930 osd.11 up 1.00000 1.00000
14 ssd 0.02930 osd.14 up 1.00000 1.00000
-5 0.14648 host ceph-osd3
1 ssd 0.02930 osd.1 up 1.00000 1.00000
5 ssd 0.02930 osd.5 up 1.00000 1.00000
7 ssd 0.02930 osd.7 up 1.00000 1.00000
10 ssd 0.02930 osd.10 up 1.00000 1.00000
13 ssd 0.02930 osd.13 up 1.00000 1.00000
-9 0.14648 host ceph-osd4
0 ssd 0.02930 osd.0 up 1.00000 1.00000
16 ssd 0.02930 osd.16 up 1.00000 1.00000
17 ssd 0.02930 osd.17 up 1.00000 1.00000
18 ssd 0.02930 osd.18 up 1.00000 1.00000
19 ssd 0.02930 osd.19 up 1.00000 1.00000Hãy sử dụng các lệnh dưới để verify lần cuối trước khi đưa vào sử dụng.
watch ceph -s
ceph -w6. Tổng kết.
Việc thêm một node mới vào cụm Ceph giúp bạn mở rộng khả năng lưu trữ và xử lý của cụm. Node mới có thể chứa thêm các OSD (Object Storage Daemons), tăng khả năng lưu trữ tổng thể và cung cấp khả năng chịu đựng lỗi tốt hơn cho cụm.
Nếu node mới cũng chạy các dịch vụ khác như Ceph Monitor hoặc Ceph Manager, điều này cũng có thể giúp cải thiện hiệu suất và độ tin cậy của cụm.
Tuy nhiên, việc thêm node mới cũng đòi hỏi phải cân nhắc về việc phân phối dữ liệu, vì Ceph sẽ cố gắng phân phối dữ liệu một cách đồng đều trên tất cả các OSD, có thể dẫn đến việc OSD mới nhận một lượng lớn dữ liệu ngay lập tức. Điều này có thể được giải quyết bằng cách sử dụng lệnh ceph osd crush reweight để điều chỉnh trọng số của OSD mới.
