1. Tổng quan.
Bài này mình sẽ triển khai tổng hợp các kiến thức của 7 bài trước, mình sẽ lab nhanh và không giải thích nhiều ở bài này nhé, các bạn có thể xem lại các bài trước nếu chưa rõ.
2. Sơ đồ LAB như sau.
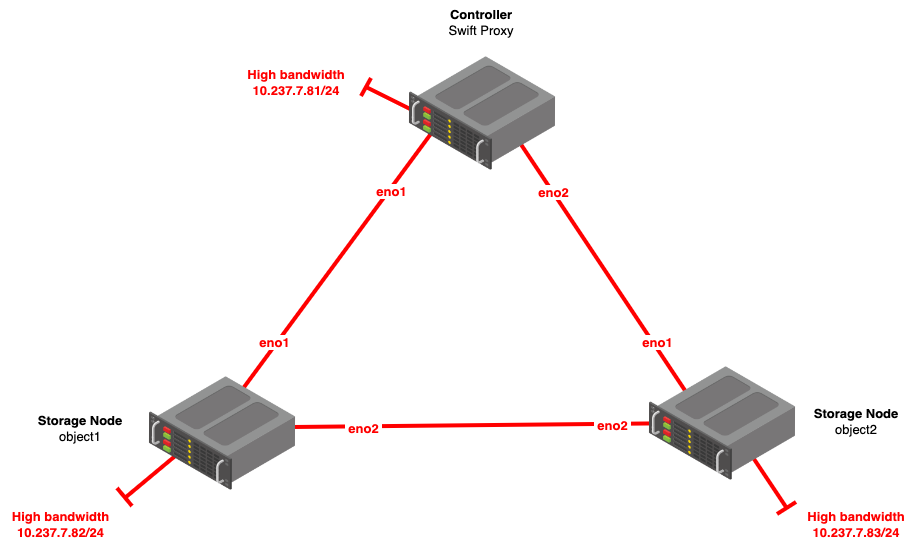
3. Chuẩn bị môi trường.
Để chuẩn bị môi trường cho OpenStack Swift thì trên tất cả các node, hãy thực hiện các bước sau.
Tạo biến môi trường.
cat > ./env << 'OEF'
export private_subnet=10.237.7.0/24
export controller_ipaddr=10.237.7.81
export storage1_ipaddr=10.237.7.82
export storage2_ipaddr=10.237.7.83
OEF
source ./envCài đặt hostname cho các node bằng lệnh hostnamectl set-hostname <node_name>.
# Controller (Swift Proxy)
hostnamectl set-hostname controller
# Object 1
hostnamectl set-hostname storage1
# Object 2
hostnamectl set-hostname storage2Comment hoặc xóa 127.0.1.1 trong file /etc/hosts.
sed -i '/^127.0.1.1/s/^/#/' /etc/hostsTrỏ domain local trong file /etc/hosts.
cat >> /etc/hosts << OEF
$controller_ipaddr controller
$storage1_ipaddr storage1
$storage2_ipaddr storage2
OEFDo môi trường lab nên mình sẽ dùng Firewall.
ufw disable
systemctl stop ufw
systemctl disable ufw
systemctl status ufw | grep active4. Cài đặt và cấu hình môi trường dành riêng cho Controller Node.
4.1. Cài đặt Python Openstack Client.
Cập nhật danh sách gói.
apt updateCài đặt Python Openstack Client.
add-apt-repository cloud-archive:yoga -y
apt install python3-openstackclient -y4.2. Cài đặt và cấu hình NTP Server.
Cài đặt Chrony làm NTP Server.
apt install chrony -yBackup file /etc/chrony/chrony.conf.
cp /etc/chrony/chrony.conf /etc/chrony/chrony.conf.bakChỉnh sửa file /etc/chrony/chrony.conf với nội dung sau.
echo """keyfile /etc/chrony/chrony.keys
driftfile /var/lib/chrony/chrony.drift
logdir /var/log/chrony
maxupdateskew 100.0
rtcsync
makestep 1 3
server 0.ubuntu.pool.ntp.org iburst
server 1.ubuntu.pool.ntp.org iburst
server 2.ubuntu.pool.ntp.org iburst
allow $private_subnet""" > /etc/chrony/chrony.confKhởi động lại dịch vụ và bật chế độ tự khởi động theo hệ thống.
systemctl restart chrony
systemctl enable chrony
systemctl status chrony | grep active4.3. Cài đặt và cấu hình Memcached.
Cài đặt Memcached.
apt install memcached python3-memcache -yThay đổi -l 127.0.0.1 sang -l <IP-ControllerNode>.
sed -i "s/-l 127.0.0.1/-l $controller_ipaddr/" /etc/memcached.confKhởi động lại dịch vụ và bật chế độ tự khởi động theo hệ thống.
systemctl restart memcached
systemctl enable memcached
systemctl status memcached | grep 'active'4.4. Cài đặt và cấu hình MariaDB.
Cài đặt mariadb-server và python3-pymysql.
apt install mariadb-server python3-pymysql -yTạo file /etc/mysql/mariadb.conf.d/99-openstack.cnf và thêm nội dung như script.
echo """[mysqld]
bind-address = $controller_ipaddr
default-storage-engine = innodb
innodb_file_per_table = on
max_connections = 4096
collation-server = utf8_general_ci
character-set-server = utf8""" > /etc/mysql/mariadb.conf.d/99-openstack.cnfKhởi động lại dịch vụ và bật chế độ tự khởi động theo hệ thống.
systemctl restart mariadb
systemctl enable mariadb
systemctl status mariadb | grep 'active'4.5. Cài đặt và cấu hình Keystone.
Tạo CSDL để lưu thông tin xác thực.
mysql -u root -pHoanghd164 -e "CREATE DATABASE keystone;"
mysql -u root -pHoanghd164 -e "GRANT ALL PRIVILEGES ON keystone.* TO 'keystone'@'localhost' IDENTIFIED BY 'KEYSTONE_DBPASS';"
mysql -u root -pHoanghd164 -e "GRANT ALL PRIVILEGES ON keystone.* TO 'keystone'@'%' IDENTIFIED BY 'KEYSTONE_DBPASS';"
mysql -u root -pHoanghd164 -e "FLUSH PRIVILEGES;"Cài đặt Keystone.
apt install keystone -yBackup file cấu hình /etc/keystone/keystone.conf.
cp /etc/keystone/keystone.conf /etc/keystone/keystone.conf.bakTạo lại file /etc/keystone/keystone.conf và nhớ sửa đội nội dung connection = mysql+pymysql://keystone:KEYSTONE_DBPASS@controller/keystone cho phù hợp với thông tin kết nối đến MariaDB của bạn.
cat > /etc/keystone/keystone.conf << 'OEF'
[DEFAULT]
log_dir = /var/log/keystone
[application_credential]
[assignment]
[auth]
[cache]
[catalog]
[cors]
[credential]
[database]
connection = mysql+pymysql://keystone:KEYSTONE_DBPASS@controller/keystone
[domain_config]
[endpoint_filter]
[endpoint_policy]
[eventlet_server]
[extra_headers]
Distribution = Ubuntu
[federation]
[fernet_receipts]
[fernet_tokens]
[healthcheck]
[identity]
[identity_mapping]
[jwt_tokens]
[ldap]
[memcache]
[oauth1]
[oslo_messaging_amqp]
[oslo_messaging_kafka]
[oslo_messaging_notifications]
[oslo_messaging_rabbit]
[oslo_middleware]
[oslo_policy]
[policy]
[profiler]
[receipt]
[resource]
[revoke]
[role]
[saml]
[security_compliance]
[shadow_users]
[token]
provider = fernet
[tokenless_auth]
[totp]
[trust]
[unified_limit]
[wsgi]
OEF
Đồng bộ thông tin Keystone vào CSDL.
su -s /bin/sh -c "keystone-manage db_sync" keystoneFernet tokens là loại token mặc định được sử dụng bởi Keystone. Swift sẽ sử dụng các token này để xác thực các yêu cầu. Lệnh dưới đây sẽ dùng để thiết lập các keys cho Fernet token.
keystone-manage fernet_setup --keystone-user keystone --keystone-group keystoneLệnh này thiết lập các credentials cho Keystone. Điều này cần thiết để Keystone có thể tương tác với các dịch vụ khác trong OpenStack, bao gồm Swift.
keystone-manage credential_setup --keystone-user keystone --keystone-group keystoneKhởi tạo Keystone, tạo ra một project, user và role admin và cung cấp một URL để truy cập Keystone. Swift sẽ sử dụng URL này để xác thực các yêu cầu.
keystone-manage bootstrap --bootstrap-password ADMIN_PASS \
--bootstrap-admin-url http://controller:5000/v3/ \
--bootstrap-internal-url http://controller:5000/v3/ \
--bootstrap-public-url http://controller:5000/v3/ \
--bootstrap-region-id RegionOneThêm ServerName controller vào cuối dòng của file /etc/apache2/apache2.conf.
echo 'ServerName controller' >> /etc/apache2/apache2.confKhởi động lại dịch vụ và bật chế độ tự khởi động theo hệ thống.
systemctl restart apache2
systemctl enable apache2
systemctl status apache2 | grep activeNếu curl http://controller:5000/v3 trả kết quả định dạng json như dưới là API đã hoạt động.
shell> curl http://controller:5000/v3
{"version": {"id": "v3.14", "status": "stable", "updated": "2020-04-07T00:00:00Z", "links": [{"rel": "self", "href": "http://controller:5000/v3/"}], "media-types": [{"base": "application/json", "type": "application/vnd.openstack.identity-v3+json"}]}}Tạo file environment với nội dung dưới.
echo '''export OS_USERNAME=admin
export OS_PASSWORD=ADMIN_PASS
export OS_PROJECT_NAME=admin
export OS_USER_DOMAIN_NAME=Default
export OS_PROJECT_DOMAIN_NAME=Default
export OS_AUTH_URL=http://controller:5000/v3
export OS_IDENTITY_API_VERSION=3''' > environmentVà chạy nó để cài đặt các biến môi trường theo nội dung đã khai báo trong file.
. environmentDo đang thử nghiệm mà mặc định domain default đã có sẵn nên mình chỉ tạo thêm project service vào trong domain default mà thôi.
openstack project create --domain default --description "Service Project" serviceTạo tiếp 2 file admin-openrc và demo-openrc để chúng ta sử dụng chúng để xác thực sau này.
File admin-openrc
echo '''export OS_PROJECT_DOMAIN_NAME=Default
export OS_USER_DOMAIN_NAME=Default
export OS_PROJECT_NAME=admin
export OS_USERNAME=admin
export OS_PASSWORD=ADMIN_PASS
export OS_AUTH_URL=http://controller:5000/v3
export OS_IDENTITY_API_VERSION=3
export OS_IMAGE_API_VERSION=2''' > admin-openrcFile demo-openrc.
echo '''export OS_PROJECT_DOMAIN_NAME=Default
export OS_USER_DOMAIN_NAME=Default
export OS_PROJECT_NAME=myproject
export OS_USERNAME=myuser
export OS_PASSWORD=MYUSER_PASS
export OS_AUTH_URL=http://controller:5000/v3
export OS_IDENTITY_API_VERSION=3
export OS_IMAGE_API_VERSION=2''' > demo-openrcGiờ hãy sử dụng username là admin, chạy file . admin-openrc.
. admin-openrcTạo username là swift với password là SWIFT_PASS.
openstack user create --domain default --password SWIFT_PASS swiftPhân quyền admin cho swift.
openstack role add --project service --user swift adminTạo các Endpoint cho OpenStack Object Storage.
openstack service create --name swift \
--description "OpenStack Object Storage" object-store
openstack endpoint create --region RegionOne \
object-store public http://controller:8080/v1/AUTH_%\(project_id\)s
openstack endpoint create --region RegionOne \
object-store internal http://controller:8080/v1/AUTH_%\(project_id\)s
openstack endpoint create --region RegionOne \
object-store admin http://controller:8080/v15. Cấu hình OpenStack Object Storage trên Controller Node.
Cài đặt các gói tin phụ thuộc liên quan đến OpenStack Object Storage.
apt-get install swift swift-proxy python3-swiftclient python3-keystoneclient python3-keystonemiddleware -yBạn có thể file mẫu proxy-server.conf-sample lưu về thư mục /etc/swift/để tự chỉnh sửa hoặc nếu không muốn tự chỉnh sửa thì bỏ qua bước này và làm tiếp bước tiếp theo để sử dụng file mẫu của mình.
curl -o /etc/swift/proxy-server.conf https://opendev.org/openstack/swift/raw/branch/master/etc/proxy-server.conf-sampleNội dung chỉnh sửa file /etc/swift/proxy-server.conf bạn xem lại bài https://wiki.hoanghd.com/swift-phan-3-cai-dat-va-cau-hinh-controller-node/. Giờ mình chạy script dưới để tạo ra file /etc/swift/proxy-server.conf và không giải thích gì thêm.
cat > /etc/swift/proxy-server.conf << 'OEF'
[DEFAULT]
# bind_ip = 0.0.0.0
bind_port = 8080
# keep_idle = 600
# bind_timeout = 30
# backlog = 4096
swift_dir = /etc/swift
user = swift
# Enables exposing configuration settings via HTTP GET /info.
# expose_info = true
# Key to use for admin calls that are HMAC signed. Default is empty,
# which will disable admin calls to /info.
# admin_key = secret_admin_key
#
# Allows the ability to withhold sections from showing up in the public calls
# to /info. You can withhold subsections by separating the dict level with a
# ".". Default value is 'swift.valid_api_versions, swift.auto_create_account_prefix'
# which allows all registered features to be listed via HTTP GET /info except
# swift.valid_api_versions and swift.auto_create_account_prefix information.
# As an example, the following would cause the sections 'container_quotas' and
# 'tempurl' to not be listed, and the key max_failed_deletes would be removed from
# bulk_delete.
# disallowed_sections = swift.valid_api_versions, container_quotas, tempurl, bulk_delete.max_failed_deletes
# Use an integer to override the number of pre-forked processes that will
# accept connections. Should default to the number of effective cpu
# cores in the system. It's worth noting that individual workers will
# use many eventlet co-routines to service multiple concurrent requests.
# workers = auto
#
# Maximum concurrent requests per worker
# max_clients = 1024
#
# Set the following two lines to enable SSL. This is for testing only.
# cert_file = /etc/swift/proxy.crt
# key_file = /etc/swift/proxy.key
#
# expiring_objects_container_divisor = 86400
# expiring_objects_account_name = expiring_objects
#
# You can specify default log routing here if you want:
# log_name = swift
# log_facility = LOG_LOCAL0
# log_level = INFO
# log_headers = false
# log_address = /dev/log
# The following caps the length of log lines to the value given; no limit if
# set to 0, the default.
# log_max_line_length = 0
#
# This optional suffix (default is empty) that would be appended to the swift transaction
# id allows one to easily figure out from which cluster that X-Trans-Id belongs to.
# This is very useful when one is managing more than one swift cluster.
# trans_id_suffix =
#
# comma separated list of functions to call to setup custom log handlers.
# functions get passed: conf, name, log_to_console, log_route, fmt, logger,
# adapted_logger
# log_custom_handlers =
#
# If set, log_udp_host will override log_address
# log_udp_host =
# log_udp_port = 514
#
# You can enable StatsD logging here:
# log_statsd_host =
# log_statsd_port = 8125
# log_statsd_default_sample_rate = 1.0
# log_statsd_sample_rate_factor = 1.0
# log_statsd_metric_prefix =
#
# List of origin hosts that are allowed for CORS requests in addition to what
# the container has set.
# Use a comma separated list of full URL (http://foo.bar:1234,https://foo.bar)
# cors_allow_origin =
# If True (default) then CORS requests are only allowed if their Origin header
# matches an allowed origin. Otherwise, any Origin is allowed.
# strict_cors_mode = True
#
# Comma separated list of headers to expose through Access-Control-Expose-Headers,
# in addition to the defaults and any headers set in container metadata (see
# CORS documentation).
# cors_expose_headers =
#
# General timeout when sending to or receiving from clients.
# client_timeout = 60.0
#
# Timeout to use when looking for pipelined requests. Set to zero to disable
# request pipelining. Defaults to client_timeout. Requires eventlet>=0.33.4;
# with earlier eventlet, any non-zero value is treated as client_timeout.
# keepalive_timeout =
#
# Note: enabling evenlet_debug might reveal sensitive information, for example
# signatures for temp urls
# eventlet_debug = false
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are IOPRIO_CLASS_RT (realtime), IOPRIO_CLASS_BE (best-effort) and
# IOPRIO_CLASS_IDLE (idle). I/O niceness priority is a number which goes from
# 0 to 7. The higher the value, the lower the I/O priority of the process.
# Work only with ionice_class.
# ionice_class =
# ionice_priority =
[pipeline:main]
# This sample pipeline uses tempauth and is used for SAIO dev work and
# testing. See below for a pipeline using keystone.
pipeline = catch_errors gatekeeper healthcheck proxy-logging cache listing_formats container_sync bulk ratelimit copy container-quotas account-quotas slo dlo versioned_writes symlink proxy-logging proxy-server
# The following pipeline shows keystone integration. Comment out the one
# above and uncomment this one. Additional steps for integrating keystone are
# covered further below in the filter sections for authtoken and keystoneauth.
#pipeline = catch_errors gatekeeper healthcheck proxy-logging cache container_sync bulk tempurl ratelimit authtoken keystoneauth copy container-quotas account-quotas slo dlo versioned_writes symlink proxy-logging proxy-server
[app:proxy-server]
use = egg:swift#proxy
# You can override the default log routing for this app here:
# set log_name = proxy-server
# set log_facility = LOG_LOCAL0
# set log_level = INFO
# set log_address = /dev/log
#
# When deployed behind a proxy, load balancer, or SSL terminator that is
# configured to speak the human-readable (v1) PROXY protocol (see
# http://www.haproxy.org/download/1.7/doc/proxy-protocol.txt), you should set
# this option to true. The proxy-server will populate the client connection
# information using the PROXY protocol and reject any connection missing a
# valid PROXY line with a 400. Only v1 (human-readable) of the PROXY protocol
# is supported.
# require_proxy_protocol = false
#
# log_handoffs = true
# recheck_account_existence = 60
# recheck_container_existence = 60
#
# How long the proxy should cache a set of shard ranges for a container when
# the set is to be used for directing object updates.
# Note that stale shard range info should be fine; updates will still
# eventually make their way to the correct shard. As a result, you can
# usually set this much higher than the existence checks above.
# recheck_updating_shard_ranges = 3600
#
# How long the proxy should cache a set of shard ranges for a container when
# the set is to be used for gathering object listings.
# Note that stale shard range info might result in incomplete object listings
# so this value should be set less than recheck_updating_shard_ranges.
# recheck_listing_shard_ranges = 600
#
# For particularly active containers, having information age out of cache can
# be quite painful: suddenly thousands of requests per second all miss and
# have to go to disk. By (rarely) going direct to disk regardless of whether
# data is present in memcache, we can periodically refresh the data in memcache
# without causing a thundering herd. Values around 0.0 - 0.1 (i.e., one in
# every thousand requests skips cache, or fewer) are recommended.
# container_existence_skip_cache_pct = 0.0
# container_updating_shard_ranges_skip_cache_pct = 0.0
# container_listing_shard_ranges_skip_cache_pct = 0.0
# account_existence_skip_cache_pct = 0.0
#
# object_chunk_size = 65536
# client_chunk_size = 65536
#
# How long the proxy server will wait on responses from the a/c/o servers.
# node_timeout = 10
#
# How long the proxy server will wait for an initial response and to read a
# chunk of data from the object servers while serving GET / HEAD requests.
# Timeouts from these requests can be recovered from so setting this to
# something lower than node_timeout would provide quicker error recovery
# while allowing for a longer timeout for non-recoverable requests (PUTs).
# Does not apply to requests with a truthy X-Newest header value.
# Defaults to node_timeout, should be overridden if node_timeout is set to a
# high number to prevent client timeouts from firing before the proxy server
# has a chance to retry.
# recoverable_node_timeout = node_timeout
#
# conn_timeout = 0.5
#
# How long to wait for requests to finish after a quorum has been established.
# post_quorum_timeout = 0.5
#
# How long without an error before a node's error count is reset. This will
# also be how long before a node is reenabled after suppression is triggered.
# Set to 0 to disable error-limiting.
# error_suppression_interval = 60.0
#
# How many errors can accumulate before a node is temporarily ignored.
# error_suppression_limit = 10
#
# If set to 'true' any authorized user may create and delete accounts; if
# 'false' no one, even authorized, can.
# allow_account_management = false
#
# If set to 'true' authorized accounts that do not yet exist within the Swift
# cluster will be automatically created.
account_autocreate = true
#
# If set to a positive value, trying to create a container when the account
# already has at least this maximum containers will result in a 403 Forbidden.
# Note: This is a soft limit, meaning a user might exceed the cap for
# recheck_account_existence before the 403s kick in.
# max_containers_per_account = 0
#
# This is a comma separated list of account hashes that ignore the
# max_containers_per_account cap.
# max_containers_whitelist =
#
# Comma separated list of Host headers to which the proxy will deny requests.
# deny_host_headers =
#
# During GET and HEAD requests, storage nodes can be chosen at random
# (shuffle), by using timing measurements (timing), or by using an explicit
# region/zone match (affinity). Using timing measurements may allow for lower
# overall latency, while using affinity allows for finer control. In both the
# timing and affinity cases, equally-sorting nodes are still randomly chosen to
# spread load.
# The valid values for sorting_method are "affinity", "shuffle", or "timing".
# This option may be overridden in a per-policy configuration section.
# sorting_method = shuffle
#
# If the "timing" sorting_method is used, the timings will only be valid for
# the number of seconds configured by timing_expiry.
# timing_expiry = 300
#
# Normally, you should only be moving one replica's worth of data at a time
# when rebalancing. If you're rebalancing more aggressively, increase this
# to avoid erroneously returning a 404 when the primary assignments that
# *didn't* change get overloaded.
# rebalance_missing_suppression_count = 1
#
# By default on a GET/HEAD swift will connect to a minimum number storage nodes
# in a minimum number of threads - for replicated data just a single request to
# a single node one at a time. When enabled concurrent_gets allows the proxy
# to use up to replica count threads when waiting on a response. In
# conjunction with the concurrency_timeout option this will allow swift to send
# out GET/HEAD requests to the storage nodes concurrently and answer as soon as
# the minimum number of backend responses are available - in replicated
# contexts this will be the first backend replica to respond.
# concurrent_gets = off
#
# This parameter controls how long to wait before firing off the next
# concurrent_get thread. A value of 0 would be fully concurrent, any other
# number will stagger the firing of the threads. This number should be
# between 0 and node_timeout. The default is what ever you set for the
# conn_timeout parameter.
# concurrency_timeout = 0.5
#
# By default on a EC GET request swift will connect to a minimum number of
# storage nodes in a minimum number of threads - for erasure coded data, ndata
# requests to primary nodes are started at the same time. When greater than
# zero this option provides additional robustness and may reduce first byte
# latency by starting additional requests - up to as many as nparity.
# concurrent_ec_extra_requests = 0
#
# Set to the number of nodes to contact for a normal request. You can use
# '* replicas' at the end to have it use the number given times the number of
# replicas for the ring being used for the request.
# request_node_count = 2 * replicas
#
# Specifies which backend servers to prefer on reads. Format is a comma
# separated list of affinity descriptors of the form <selection>=<priority>.
# The <selection> may be r<N> for selecting nodes in region N or r<N>z<M> for
# selecting nodes in region N, zone M. The <priority> value should be a whole
# number that represents the priority to be given to the selection; lower
# numbers are higher priority.
#
# Example: first read from region 1 zone 1, then region 1 zone 2, then
# anything in region 2, then everything else:
# read_affinity = r1z1=100, r1z2=200, r2=300
# Default is empty, meaning no preference.
# This option may be overridden in a per-policy configuration section.
# read_affinity =
#
# Specifies which backend servers to prefer on object writes. Format is a comma
# separated list of affinity descriptors of the form r<N> for region N or
# r<N>z<M> for region N, zone M. If this is set, then when handling an object
# PUT request, some number (see setting write_affinity_node_count) of local
# backend servers will be tried before any nonlocal ones.
#
# Example: try to write to regions 1 and 2 before writing to any other
# nodes:
# write_affinity = r1, r2
# Default is empty, meaning no preference.
# This option may be overridden in a per-policy configuration section.
# write_affinity =
#
# The number of local (as governed by the write_affinity setting) nodes to
# attempt to contact first on writes, before any non-local ones. The value
# should be an integer number, or use '* replicas' at the end to have it use
# the number given times the number of replicas for the ring being used for the
# request.
# This option may be overridden in a per-policy configuration section.
# write_affinity_node_count = 2 * replicas
#
# The number of local (as governed by the write_affinity setting) handoff nodes
# to attempt to contact on deletion, in addition to primary nodes.
#
# Example: in geographically distributed deployment of 2 regions, If
# replicas=3, sometimes there may be 1 primary node and 2 local handoff nodes
# in one region holding the object after uploading but before object replicated
# to the appropriate locations in other regions. In this case, include these
# handoff nodes to send request when deleting object could help make correct
# decision for the response. The default value 'auto' means Swift will
# calculate the number automatically, the default value is
# (replicas - len(local_primary_nodes)). This option may be overridden in a
# per-policy configuration section.
# write_affinity_handoff_delete_count = auto
#
# These are the headers whose values will only be shown to swift_owners. The
# exact definition of a swift_owner is up to the auth system in use, but
# usually indicates administrative responsibilities.
# swift_owner_headers = x-container-read, x-container-write, x-container-sync-key, x-container-sync-to, x-account-meta-temp-url-key, x-account-meta-temp-url-key-2, x-container-meta-temp-url-key, x-container-meta-temp-url-key-2, x-account-access-control
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are IOPRIO_CLASS_RT (realtime), IOPRIO_CLASS_BE (best-effort) and
# IOPRIO_CLASS_IDLE (idle). I/O niceness priority is a number which goes from
# 0 to 7. The higher the value, the lower the I/O priority of the process.
# Work only with ionice_class.
# ionice_class =
# ionice_priority =
#
# When upgrading from liberasurecode<=1.5.0, you may want to continue writing
# legacy CRCs until all nodes are upgraded and capabale of reading fragments
# with zlib CRCs. liberasurecode>=1.6.2 checks for the environment variable
# LIBERASURECODE_WRITE_LEGACY_CRC; if set (value doesn't matter), it will use
# its legacy CRC. Set this option to true or false to ensure the environment
# variable is or is not set. Leave the option blank or absent to not touch
# the environment (default). For more information, see
# https://bugs.launchpad.net/liberasurecode/+bug/1886088
# write_legacy_ec_crc =
# Some proxy-server configuration options may be overridden on a per-policy
# basis by including per-policy config section(s). The value of any option
# specified a per-policy section will override any value given in the
# proxy-server section for that policy only. Otherwise the value of these
# options will be that specified in the proxy-server section.
# The section name should refer to the policy index, not the policy name.
# [proxy-server:policy:<policy index>]
# sorting_method =
# read_affinity =
# write_affinity =
# write_affinity_node_count =
# write_affinity_handoff_delete_count =
# rebalance_missing_suppression_count = 1
# concurrent_gets = off
# concurrency_timeout = 0.5
# concurrent_ec_extra_requests = 0
[filter:tempauth]
use = egg:swift#tempauth
# You can override the default log routing for this filter here:
# set log_name = tempauth
# set log_facility = LOG_LOCAL0
# set log_level = INFO
# set log_headers = false
# set log_address = /dev/log
#
# The reseller prefix will verify a token begins with this prefix before even
# attempting to validate it. Also, with authorization, only Swift storage
# accounts with this prefix will be authorized by this middleware. Useful if
# multiple auth systems are in use for one Swift cluster.
# The reseller_prefix may contain a comma separated list of items. The first
# item is used for the token as mentioned above. If second and subsequent
# items exist, the middleware will handle authorization for an account with
# that prefix. For example, for prefixes "AUTH, SERVICE", a path of
# /v1/SERVICE_account is handled the same as /v1/AUTH_account. If an empty
# (blank) reseller prefix is required, it must be first in the list. Two
# single quote characters indicates an empty (blank) reseller prefix.
# reseller_prefix = AUTH
#
# The require_group parameter names a group that must be presented by
# either X-Auth-Token or X-Service-Token. Usually this parameter is
# used only with multiple reseller prefixes (e.g., SERVICE_require_group=blah).
# By default, no group is needed. Do not use .admin.
# require_group =
# The auth prefix will cause requests beginning with this prefix to be routed
# to the auth subsystem, for granting tokens, etc.
# auth_prefix = /auth/
# token_life = 86400
#
# This allows middleware higher in the WSGI pipeline to override auth
# processing, useful for middleware such as tempurl and formpost. If you know
# you're not going to use such middleware and you want a bit of extra security,
# you can set this to false.
# allow_overrides = true
#
# This specifies what scheme to return with storage URLs:
# http, https, or default (chooses based on what the server is running as)
# This can be useful with an SSL load balancer in front of a non-SSL server.
# storage_url_scheme = default
#
# Lastly, you need to list all the accounts/users you want here. The format is:
# user_<account>_<user> = <key> [group] [group] [...] [storage_url]
# or if you want underscores in <account> or <user>, you can base64 encode them
# (with no equal signs) and use this format:
# user64_<account_b64>_<user_b64> = <key> [group] [group] [...] [storage_url]
# There are special groups of:
# .reseller_admin = can do anything to any account for this auth
# .reseller_reader = can GET/HEAD anything in any account for this auth
# .admin = can do anything within the account
# If none of these groups are specified, the user can only access containers
# that have been explicitly allowed for them by a .admin or .reseller_admin.
# The trailing optional storage_url allows you to specify an alternate url to
# hand back to the user upon authentication. If not specified, this defaults to
# $HOST/v1/<reseller_prefix>_<account> where $HOST will do its best to resolve
# to what the requester would need to use to reach this host.
# Here are example entries, required for running the tests:
user_admin_admin = admin .admin .reseller_admin
user_admin_auditor = admin_ro .reseller_reader
user_test_tester = testing .admin
user_test_tester2 = testing2 .admin
user_test_tester3 = testing3
user_test2_tester2 = testing2 .admin
user_test5_tester5 = testing5 service
# To enable Keystone authentication you need to have the auth token
# middleware first to be configured. Here is an example below, please
# refer to the keystone's documentation for details about the
# different settings.
#
# You'll also need to have the keystoneauth middleware enabled and have it in
# your main pipeline, as show in the sample pipeline at the top of this file.
#
# Following parameters are known to work with keystonemiddleware v2.3.0
# (above v2.0.0), but checking the latest information in the wiki page[1]
# is recommended.
# 1. https://docs.openstack.org/keystonemiddleware/latest/middlewarearchitecture.html#configuration
#
[filter:authtoken]
paste.filter_factory = keystonemiddleware.auth_token:filter_factory
www_authenticate_uri = http://controller:5000/v3
auth_url = http://controller:5000/v3
memcached_servers = controller:11211
auth_type = password
# auth_plugin = password
# The following credentials must match the Keystone credentials for the Swift
# service and may need to be changed to match your Keystone configuration. The
# example values shown here assume a user named 'swift' with admin role on a
# project named 'service', both being in the Keystone domain with id 'default'.
# Refer to the keystonemiddleware documentation link above [1] for other
# examples.
project_domain_id = default
user_domain_id = default
project_name = service
username = swift
password = SWIFT_PASS
#
# delay_auth_decision defaults to False, but leaving it as false will
# prevent other auth systems, staticweb, tempurl, formpost, and ACLs from
# working. This value must be explicitly set to True.
delay_auth_decision = True
#
# cache = swift.cache
# include_service_catalog = False
#
[filter:keystoneauth]
use = egg:swift#keystoneauth
# The reseller_prefix option lists account namespaces that this middleware is
# responsible for. The prefix is placed before the Keystone project id.
# For example, for project 12345678, and prefix AUTH, the account is
# named AUTH_12345678 (i.e., path is /v1/AUTH_12345678/...).
# Several prefixes are allowed by specifying a comma-separated list
# as in: "reseller_prefix = AUTH, SERVICE". The empty string indicates a
# single blank/empty prefix. If an empty prefix is required in a list of
# prefixes, a value of '' (two single quote characters) indicates a
# blank/empty prefix. Except for the blank/empty prefix, an underscore ('_')
# character is appended to the value unless already present.
# reseller_prefix = AUTH
#
# The user must have at least one role named by operator_roles on a
# project in order to create, delete and modify containers and objects
# and to set and read privileged headers such as ACLs.
# If there are several reseller prefix items, you can prefix the
# parameter so it applies only to those accounts (for example
# the parameter SERVICE_operator_roles applies to the /v1/SERVICE_<project>
# path). If you omit the prefix, the option applies to all reseller
# prefix items. For the blank/empty prefix, prefix with '' (do not put
# underscore after the two single quote characters).
operator_roles = admin, user
#
# The reseller admin role has the ability to create and delete accounts
# reseller_admin_role = ResellerAdmin
#
# This allows middleware higher in the WSGI pipeline to override auth
# processing, useful for middleware such as tempurl and formpost. If you know
# you're not going to use such middleware and you want a bit of extra security,
# you can set this to false.
# allow_overrides = true
#
# If the service_roles parameter is present, an X-Service-Token must be
# present in the request that when validated, grants at least one role listed
# in the parameter. The X-Service-Token may be scoped to any project.
# If there are several reseller prefix items, you can prefix the
# parameter so it applies only to those accounts (for example
# the parameter SERVICE_service_roles applies to the /v1/SERVICE_<project>
# path). If you omit the prefix, the option applies to all reseller
# prefix items. For the blank/empty prefix, prefix with '' (do not put
# underscore after the two single quote characters).
# By default, no service_roles are required.
# service_roles =
#
# For backwards compatibility, keystoneauth will match names in cross-tenant
# access control lists (ACLs) when both the requesting user and the tenant
# are in the default domain i.e the domain to which existing tenants are
# migrated. The default_domain_id value configured here should be the same as
# the value used during migration of tenants to keystone domains.
# default_domain_id = default
#
# For a new installation, or an installation in which keystone projects may
# move between domains, you should disable backwards compatible name matching
# in ACLs by setting allow_names_in_acls to false:
# allow_names_in_acls = true
#
# In OpenStack terms, these reader roles are scoped for system: they
# can read anything across projects and domains.
# They are used for auditing and compliance fuctions.
# In Swift terms, these roles are as powerful as the reseller_admin_role,
# only do not modify the cluster.
# By default the list of reader roles is empty.
# system_reader_roles =
#
# This is a reader role scoped for a Keystone project.
# An identity that has this role can read anything in a project, so it is
# basically a swiftoperator, but read-only.
# project_reader_roles =
[filter:s3api]
use = egg:swift#s3api
# s3api setup:
#
# With either tempauth or your custom auth:
# - Put s3api just before your auth filter(s) in the pipeline
# With keystone:
# - Put s3api and s3token before keystoneauth in the pipeline, but after
# auth_token
# If you have ratelimit enabled for Swift requests, you may want to place a
# second copy after auth to also ratelimit S3 requests.
#
# Swift has no concept of the S3's resource owner; the resources
# (i.e. containers and objects) created via the Swift API have no owner
# information. This option specifies how the s3api middleware handles them
# with the S3 API. If this option is 'false', such kinds of resources will be
# invisible and no users can access them with the S3 API. If set to 'true',
# a resource without an owner belongs to everyone and everyone can access it
# with the S3 API. If you care about S3 compatibility, set 'false' here. This
# option makes sense only when the s3_acl option is set to 'true' and your
# Swift cluster has the resources created via the Swift API.
# allow_no_owner = false
#
# Set a region name of your Swift cluster. Note that the s3api doesn't choose
# a region of the newly created bucket. This value is used for the
# GET Bucket location API and v4 signatures calculation.
# location = us-east-1
#
# Set whether to enforce DNS-compliant bucket names. Note that S3 enforces
# these conventions in all regions except the US Standard region.
# dns_compliant_bucket_names = True
#
# Set the default maximum number of objects returned in the GET Bucket
# response.
# max_bucket_listing = 1000
#
# Set the maximum number of parts returned in the List Parts operation.
# (default: 1000 as well as S3 specification)
# If setting it larger than 10000 (swift container_listing_limit default)
# make sure you also increase the container_listing_limit in swift.conf.
# max_parts_listing = 1000
#
# Set the maximum number of objects we can delete with the Multi-Object Delete
# operation.
# max_multi_delete_objects = 1000
#
# Set the number of objects to delete at a time with the Multi-Object Delete
# operation.
# multi_delete_concurrency = 2
#
# If set to 'true', s3api uses its own metadata for ACLs
# (e.g. X-Container-Sysmeta-S3Api-Acl) to achieve the best S3 compatibility.
# If set to 'false', s3api tries to use Swift ACLs (e.g. X-Container-Read)
# instead of S3 ACLs as far as possible.
# There are some caveats that one should know about this setting. Firstly,
# if set to 'false' after being previously set to 'true' any new objects or
# containers stored while 'true' setting will be accessible to all users
# because the s3 ACLs will be ignored under s3_acl=False setting. Secondly,
# s3_acl True mode don't keep ACL consistency between both the S3 and Swift
# API. Meaning with s3_acl enabled S3 ACLs only effect objects and buckets
# via the S3 API. As this ACL information wont be available via the Swift API
# and so the ACL wont be applied.
# Note that s3_acl currently supports only keystone and tempauth.
# DON'T USE THIS for production before enough testing for your use cases.
# This stuff is still under development and it might cause something
# you don't expect.
# s3_acl = false
#
# Specify a (comma-separated) list of host names for your Swift cluster.
# This enables virtual-hosted style requests.
# storage_domain =
#
# Enable pipeline order check for SLO, s3token, authtoken, keystoneauth
# according to standard s3api/Swift construction using either tempauth or
# keystoneauth. If the order is incorrect, it raises an exception to stop
# proxy. Turn auth_pipeline_check off only when you want to bypass these
# authenticate middlewares in order to use other 3rd party (or your
# proprietary) authenticate middleware.
# auth_pipeline_check = True
#
# Enable multi-part uploads. (default: true)
# This is required to store files larger than Swift's max_file_size (by
# default, 5GiB). Note that has performance implications when deleting objects,
# as we now have to check for whether there are also segments to delete. The
# SLO middleware must be in the pipeline after s3api for this option to have
# effect.
# allow_multipart_uploads = True
#
# Set the maximum number of parts for Upload Part operation.(default: 1000)
# When setting it to be larger than the default value in order to match the
# specification of S3, set to be larger max_manifest_segments for slo
# middleware.(specification of S3: 10000)
# max_upload_part_num = 1000
#
# Enable returning only buckets which owner are the user who requested
# GET Service operation. (default: false)
# If you want to enable the above feature, set this and s3_acl to true.
# That might cause significant performance degradation. So, only if your
# service absolutely need this feature, set this setting to true.
# If you set this to false, s3api returns all buckets.
# check_bucket_owner = false
#
# By default, Swift reports only S3 style access log.
# (e.g. PUT /bucket/object) If set force_swift_request_proxy_log
# to be 'true', Swift will become to output Swift style log
# (e.g. PUT /v1/account/container/object) in addition to S3 style log.
# Note that they will be reported twice (i.e. s3api doesn't care about
# the duplication) and Swift style log will includes also various subrequests
# to achieve S3 compatibilities when force_swift_request_proxy_log is set to
# 'true'
# force_swift_request_proxy_log = false
#
# AWS S3 document says that each part must be at least 5 MB in a multipart
# upload, except the last part.
# min_segment_size = 5242880
#
# AWS allows clock skew up to 15 mins; note that older versions of swift/swift3
# allowed at most 5 mins.
# allowable_clock_skew = 900
#
# CORS preflight requests don't contain enough information for us to
# identify the account that should be used for the real request, so
# the allowed origins must be set cluster-wide. (default: blank; all
# preflight requests will be denied)
# cors_preflight_allow_origin =
#
# AWS will return a 503 Slow Down when clients are making too many requests,
# but that can make client logs confusing if they only log/give metrics on
# status ints. Turn this on to return 429 instead.
# ratelimit_as_client_error = false
# You can override the default log routing for this filter here:
# log_name = s3api
[filter:s3token]
# s3token middleware authenticates with keystone using the s3 credentials
# provided in the request header. Please put s3token between s3api
# and keystoneauth if you're using keystoneauth.
use = egg:swift#s3token
# Prefix that will be prepended to the tenant to form the account
reseller_prefix = AUTH_
# By default, s3token will reject all invalid S3-style requests. Set this to
# True to delegate that decision to downstream WSGI components. This may be
# useful if there are multiple auth systems in the proxy pipeline.
delay_auth_decision = False
# Keystone server details. Note that this differs from how swift3 was
# configured: in particular, the Keystone API version must be included.
auth_uri = http://keystonehost:5000/v3
# Connect/read timeout to use when communicating with Keystone
http_timeout = 10.0
# Number of seconds to cache the S3 secret. By setting this to a positive
# number, the S3 authorization validation checks can happen locally.
# secret_cache_duration = 0
# If S3 secret caching is enabled, Keystone auth credentials to be used to
# validate S3 authorization must be provided here. The appropriate options
# are the same as used in the authtoken middleware above. The values are
# likely the same as used in the authtoken middleware.
# Note that the Keystone auth credentials used by s3token will need to be
# able to view all project credentials too.
# SSL-related options
# insecure = False
# certfile =
# keyfile =
# You can override the default log routing for this filter here:
# log_name = s3token
# Secrets may be cached to reduce latency for the client and load on Keystone.
# Set this to some number of seconds greater than zero to enable caching.
# secret_cache_duration = 0
# Secret caching requires Keystone credentials similar to the authtoken middleware;
# these credentials require access to view all project credentials.
# auth_url = http://keystonehost:5000
# auth_type = password
# project_domain_id = default
# project_name = service
# user_domain_id = default
# username = swift
# password = password
[filter:healthcheck]
use = egg:swift#healthcheck
# An optional filesystem path, which if present, will cause the healthcheck
# URL to return "503 Service Unavailable" with a body of "DISABLED BY FILE".
# This facility may be used to temporarily remove a Swift node from a load
# balancer pool during maintenance or upgrade (remove the file to allow the
# node back into the load balancer pool).
# disable_path =
[filter:cache]
use = egg:swift#memcache
# You can override the default log routing for this filter here:
# set log_name = cache
# set log_facility = LOG_LOCAL0
# set log_level = INFO
# set log_headers = false
# set log_address = /dev/log
#
# If not set here, the value for memcache_servers will be read from
# memcache.conf (see memcache.conf-sample) or lacking that file, it will
# default to the value below. You can specify multiple servers separated with
# commas, as in: 10.1.2.3:11211,10.1.2.4:11211 (IPv6 addresses must
# follow rfc3986 section-3.2.2, i.e. [::1]:11211)
memcache_servers = controller:11211
#
# Sets the maximum number of connections to each memcached server per worker
# memcache_max_connections = 2
#
# How long without an error before a server's error count is reset. This will
# also be how long before a server is reenabled after suppression is triggered.
# Set to 0 to disable error-limiting.
# error_suppression_interval = 60.0
#
# How many errors can accumulate before a server is temporarily ignored.
# error_suppression_limit = 10
#
# (Optional) Global toggle for TLS usage when comunicating with
# the caching servers.
# tls_enabled =
#
# More options documented in memcache.conf-sample
[filter:ratelimit]
use = egg:swift#ratelimit
# You can override the default log routing for this filter here:
# set log_name = ratelimit
# set log_facility = LOG_LOCAL0
# set log_level = INFO
# set log_headers = false
# set log_address = /dev/log
#
# clock_accuracy should represent how accurate the proxy servers' system clocks
# are with each other. 1000 means that all the proxies' clock are accurate to
# each other within 1 millisecond. No ratelimit should be higher than the
# clock accuracy.
# clock_accuracy = 1000
#
# max_sleep_time_seconds = 60
#
# log_sleep_time_seconds of 0 means disabled
# log_sleep_time_seconds = 0
#
# allows for slow rates (e.g. running up to 5 sec's behind) to catch up.
# rate_buffer_seconds = 5
#
# account_ratelimit of 0 means disabled
# account_ratelimit = 0
# DEPRECATED- these will continue to work but will be replaced
# by the X-Account-Sysmeta-Global-Write-Ratelimit flag.
# Please see ratelimiting docs for details.
# these are comma separated lists of account names
# account_whitelist = a,b
# account_blacklist = c,d
# with container_limit_x = r
# for containers of size x limit write requests per second to r. The container
# rate will be linearly interpolated from the values given. With the values
# below, a container of size 5 will get a rate of 75.
# container_ratelimit_0 = 100
# container_ratelimit_10 = 50
# container_ratelimit_50 = 20
# Similarly to the above container-level write limits, the following will limit
# container GET (listing) requests.
# container_listing_ratelimit_0 = 100
# container_listing_ratelimit_10 = 50
# container_listing_ratelimit_50 = 20
[filter:read_only]
use = egg:swift#read_only
# read_only set to true means turn global read only on
# read_only = false
# allow_deletes set to true means to allow deletes
# allow_deletes = false
# Note: Put after ratelimit in the pipeline.
# Note: needs to be placed before listing_formats;
# otherwise remapped listings will always be JSON
[filter:domain_remap]
use = egg:swift#domain_remap
# You can override the default log routing for this filter here:
# set log_name = domain_remap
# set log_facility = LOG_LOCAL0
# set log_level = INFO
# set log_headers = false
# set log_address = /dev/log
#
# Specify the storage_domain that match your cloud, multiple domains
# can be specified separated by a comma
# storage_domain = example.com
# Specify a root path part that will be added to the start of paths if not
# already present.
# path_root = v1
# Browsers can convert a host header to lowercase, so check that reseller
# prefix on the account is the correct case. This is done by comparing the
# items in the reseller_prefixes config option to the found prefix. If they
# match except for case, the item from reseller_prefixes will be used
# instead of the found reseller prefix. When none match, the default reseller
# prefix is used. When no default reseller prefix is configured, any request
# with an account prefix not in that list will be ignored by this middleware.
# reseller_prefixes = AUTH
# default_reseller_prefix =
# Enable legacy remapping behavior for versioned path requests:
# c.a.example.com/v1/o -> /v1/AUTH_a/c/o
# instead of
# c.a.example.com/v1/o -> /v1/AUTH_a/c/v1/o
# ... by default all path parts after a remapped domain are considered part of
# the object name with no special case for the path "v1"
# mangle_client_paths = False
[filter:catch_errors]
use = egg:swift#catch_errors
# You can override the default log routing for this filter here:
# set log_name = catch_errors
# set log_facility = LOG_LOCAL0
# set log_level = INFO
# set log_headers = false
# set log_address = /dev/log
[filter:cname_lookup]
# Note: this middleware requires python-dnspython
use = egg:swift#cname_lookup
# You can override the default log routing for this filter here:
# set log_name = cname_lookup
# set log_facility = LOG_LOCAL0
# set log_level = INFO
# set log_headers = false
# set log_address = /dev/log
#
# Specify the storage_domain that match your cloud, multiple domains
# can be specified separated by a comma
# storage_domain = example.com
#
# lookup_depth = 1
#
# Specify the nameservers to use to do the CNAME resolution. If unset, the
# system configuration is used. Multiple nameservers can be specified
# separated by a comma. Default port 53 can be overridden. IPv6 is accepted.
# Example: 127.0.0.1, 127.0.0.2, 127.0.0.3:5353, [::1], [::1]:5353
# nameservers =
# Note: Put staticweb just after your auth filter(s) in the pipeline
[filter:staticweb]
use = egg:swift#staticweb
# You can override the default log routing for this filter here:
# set log_name = staticweb
# set log_facility = LOG_LOCAL0
# set log_level = INFO
# set log_headers = false
# set log_address = /dev/log
#
# At times when it's impossible for staticweb to guess the outside
# endpoint correctly, the url_base may be used to supply the URL
# scheme and/or the host name (and port number) in order to generate
# redirects.
# Example values:
# http://www.example.com - redirect to www.example.com
# https: - changes the schema only
# https:// - same, changes the schema only
# //www.example.com:8080 - redirect www.example.com on port 8080
# (schema unchanged)
# url_base =
# Note: Put tempurl before dlo, slo and your auth filter(s) in the pipeline
[filter:tempurl]
use = egg:swift#tempurl
# The methods allowed with Temp URLs.
# methods = GET HEAD PUT POST DELETE
#
# The headers to remove from incoming requests. Simply a whitespace delimited
# list of header names and names can optionally end with '*' to indicate a
# prefix match. incoming_allow_headers is a list of exceptions to these
# removals.
# incoming_remove_headers = x-timestamp
#
# The headers allowed as exceptions to incoming_remove_headers. Simply a
# whitespace delimited list of header names and names can optionally end with
# '*' to indicate a prefix match.
# incoming_allow_headers =
#
# The headers to remove from outgoing responses. Simply a whitespace delimited
# list of header names and names can optionally end with '*' to indicate a
# prefix match. outgoing_allow_headers is a list of exceptions to these
# removals.
# outgoing_remove_headers = x-object-meta-*
#
# The headers allowed as exceptions to outgoing_remove_headers. Simply a
# whitespace delimited list of header names and names can optionally end with
# '*' to indicate a prefix match.
# outgoing_allow_headers = x-object-meta-public-*
#
# The digest algorithm(s) supported for generating signatures;
# whitespace-delimited.
# allowed_digests = sha1 sha256 sha512
# Note: Put formpost just before your auth filter(s) in the pipeline
[filter:formpost]
use = egg:swift#formpost
# The digest algorithm(s) supported for generating signatures;
# whitespace-delimited.
# allowed_digests = sha1 sha256 sha512
# Note: Just needs to be placed before the proxy-server in the pipeline.
[filter:name_check]
use = egg:swift#name_check
# forbidden_chars = '"`<>
# maximum_length = 255
# forbidden_regexp = /\./|/\.\./|/\.$|/\.\.$
# Note: Etag quoter should be placed just after cache in the pipeline.
[filter:etag-quoter]
use = egg:swift#etag_quoter
# Historically, Swift has emitted bare MD5 hex digests as ETags, which is not
# RFC compliant. With this middleware in the pipeline, users can opt-in to
# RFC-compliant ETags on a per-account or per-container basis.
#
# Set to true to enable RFC-compliant ETags cluster-wide by default. Users
# can still opt-out by setting appropriate account or container metadata.
# enable_by_default = false
[filter:list-endpoints]
use = egg:swift#list_endpoints
# list_endpoints_path = /endpoints/
[filter:proxy-logging]
use = egg:swift#proxy_logging
# If not set, logging directives from [DEFAULT] without "access_" will be used
# access_log_name = swift
# access_log_facility = LOG_LOCAL0
# access_log_level = INFO
# access_log_address = /dev/log
#
# Log route for this filter. Useful if you want to have different configs for
# the two proxy-logging filters.
# access_log_route = proxy-server
#
# If set, access_log_udp_host will override access_log_address
# access_log_udp_host =
# access_log_udp_port = 514
#
# You can use log_statsd_* from [DEFAULT] or override them here:
# access_log_statsd_host =
# access_log_statsd_port = 8125
# access_log_statsd_default_sample_rate = 1.0
# access_log_statsd_sample_rate_factor = 1.0
# access_log_statsd_metric_prefix =
# access_log_headers = false
#
# If access_log_headers is True and access_log_headers_only is set only
# these headers are logged. Multiple headers can be defined as comma separated
# list like this: access_log_headers_only = Host, X-Object-Meta-Mtime
# access_log_headers_only =
#
# The default log format includes several sensitive values in logs:
# * X-Auth-Token header
# * temp_url_sig query parameter
# * Authorization header
# * X-Amz-Signature query parameter
# To prevent an unauthorized access of the log file leading to an unauthorized
# access of cluster data, only a portion of these values are written, with the
# remainder replaced by '...' in the log. Set reveal_sensitive_prefix to the
# number of characters to log. Set to 0 to suppress the values entirely; set
# to something large (1000, say) to write full values. Note that some values
# may start appearing in full at values as low as 33.
# reveal_sensitive_prefix = 16
#
# What HTTP methods are allowed for StatsD logging (comma-sep); request methods
# not in this list will have "BAD_METHOD" for the <verb> portion of the metric.
# log_statsd_valid_http_methods = GET,HEAD,POST,PUT,DELETE,COPY,OPTIONS
#
# Note: The double proxy-logging in the pipeline is not a mistake. The
# left-most proxy-logging is there to log requests that were handled in
# middleware and never made it through to the right-most middleware (and
# proxy server). Double logging is prevented for normal requests. See
# proxy-logging docs.
#
# Hashing algorithm for log anonymization. Must be one of algorithms supported
# by Python's hashlib.
# log_anonymization_method = MD5
#
# Salt added during log anonymization
# log_anonymization_salt =
#
# Template used to format access logs. All words surrounded by curly brackets
# will be substituted with the appropriate values. For more information, see
# https://docs.openstack.org/swift/latest/logs.html
# log_msg_template = {client_ip} {remote_addr} {end_time.datetime} {method} {path} {protocol} {status_int} {referer} {user_agent} {auth_token} {bytes_recvd} {bytes_sent} {client_etag} {transaction_id} {headers} {request_time} {source} {log_info} {start_time} {end_time} {policy_index}
# Note: Put before both ratelimit and auth in the pipeline.
[filter:bulk]
use = egg:swift#bulk
# max_containers_per_extraction = 10000
# max_failed_extractions = 1000
# max_deletes_per_request = 10000
# max_failed_deletes = 1000
#
# In order to keep a connection active during a potentially long bulk request,
# Swift may return whitespace prepended to the actual response body. This
# whitespace will be yielded no more than every yield_frequency seconds.
# yield_frequency = 10
#
# Note: The following parameter is used during a bulk delete of objects and
# their container. This would frequently fail because it is very likely
# that all replicated objects have not been deleted by the time the middleware got a
# successful response. It can be configured the number of retries. And the
# number of seconds to wait between each retry will be 1.5**retry
# delete_container_retry_count = 0
#
# To speed up the bulk delete process, multiple deletes may be executed in
# parallel. Avoid setting this too high, as it gives clients a force multiplier
# which may be used in DoS attacks. The suggested range is between 2 and 10.
# delete_concurrency = 2
# Note: Put after auth and staticweb in the pipeline.
[filter:slo]
use = egg:swift#slo
# max_manifest_segments = 1000
# max_manifest_size = 8388608
#
# Rate limiting applies only to segments smaller than this size (bytes).
# rate_limit_under_size = 1048576
#
# Start rate-limiting SLO segment serving after the Nth small segment of a
# segmented object.
# rate_limit_after_segment = 10
#
# Once segment rate-limiting kicks in for an object, limit segments served
# to N per second. 0 means no rate-limiting.
# rate_limit_segments_per_sec = 1
#
# Time limit on GET requests (seconds)
# max_get_time = 86400
#
# When creating an SLO, multiple segment validations may be executed in
# parallel. Further, multiple deletes may be executed in parallel when deleting
# with ?multipart-manifest=delete. Use this setting to limit how many
# subrequests may be executed concurrently. Avoid setting it too high, as it
# gives clients a force multiplier which may be used in DoS attacks. The
# suggested range is between 2 and 10.
# concurrency = 2
#
# This may be used to separately tune validation and delete concurrency values.
# Default is to use the concurrency value from above; all of the same caveats
# apply regarding recommended ranges.
# delete_concurrency = 2
#
# In order to keep a connection active during a potentially long PUT request,
# clients may request that Swift send whitespace ahead of the final response
# body. This whitespace will be yielded at most every yield_frequency seconds.
# yield_frequency = 10
#
# Since SLOs may have thousands of segments, clients may request that the
# object-expirer handle the deletion of segments using query params like
# `?multipart-manifest=delete&async=on`. You may want to keep this off if it
# negatively impacts your expirers; in that case, the deletes will still
# be done as part of the client request.
# allow_async_delete = true
# Note: Put after auth and staticweb in the pipeline.
# If you don't put it in the pipeline, it will be inserted for you.
[filter:dlo]
use = egg:swift#dlo
# Start rate-limiting DLO segment serving after the Nth segment of a
# segmented object.
# rate_limit_after_segment = 10
#
# Once segment rate-limiting kicks in for an object, limit segments served
# to N per second. 0 means no rate-limiting.
# rate_limit_segments_per_sec = 1
#
# Time limit on GET requests (seconds)
# max_get_time = 86400
# Note: Put after auth and server-side copy in the pipeline.
[filter:container-quotas]
use = egg:swift#container_quotas
# Note: Put after auth and server-side copy in the pipeline.
[filter:account-quotas]
use = egg:swift#account_quotas
[filter:gatekeeper]
use = egg:swift#gatekeeper
# Set this to false if you want to allow clients to set arbitrary X-Timestamps
# on uploaded objects. This may be used to preserve timestamps when migrating
# from a previous storage system, but risks allowing users to upload
# difficult-to-delete data.
# shunt_inbound_x_timestamp = true
#
# Set this to true if you want to allow clients to access and manipulate the
# (normally internal-to-swift) null namespace by including a header like
# X-Allow-Reserved-Names: true
# allow_reserved_names_header = false
#
# You can override the default log routing for this filter here:
# set log_name = gatekeeper
# set log_facility = LOG_LOCAL0
# set log_level = INFO
# set log_headers = false
# set log_address = /dev/log
[filter:container_sync]
use = egg:swift#container_sync
# Set this to false if you want to disallow any full URL values to be set for
# any new X-Container-Sync-To headers. This will keep any new full URLs from
# coming in, but won't change any existing values already in the cluster.
# Updating those will have to be done manually, as knowing what the true realm
# endpoint should be cannot always be guessed.
# allow_full_urls = true
# Set this to specify this clusters //realm/cluster as "current" in /info
# current = //REALM/CLUSTER
# Note: Put it at the beginning of the pipeline to profile all middleware. But
# it is safer to put this after catch_errors, gatekeeper and healthcheck.
[filter:xprofile]
use = egg:swift#xprofile
# This option enable you to switch profilers which should inherit from python
# standard profiler. Currently the supported value can be 'cProfile',
# 'eventlet.green.profile' etc.
# profile_module = eventlet.green.profile
#
# This prefix will be used to combine process ID and timestamp to name the
# profile data file. Make sure the executing user has permission to write
# into this path (missing path segments will be created, if necessary).
# If you enable profiling in more than one type of daemon, you must override
# it with an unique value like: /var/log/swift/profile/proxy.profile
# log_filename_prefix = /tmp/log/swift/profile/default.profile
#
# the profile data will be dumped to local disk based on above naming rule
# in this interval.
# dump_interval = 5.0
#
# Be careful, this option will enable profiler to dump data into the file with
# time stamp which means there will be lots of files piled up in the directory.
# dump_timestamp = false
#
# This is the path of the URL to access the mini web UI.
# path = /__profile__
#
# Clear the data when the wsgi server shutdown.
# flush_at_shutdown = false
#
# unwind the iterator of applications
# unwind = false
# Note: Put after slo, dlo in the pipeline.
# If you don't put it in the pipeline, it will be inserted automatically.
[filter:versioned_writes]
use = egg:swift#versioned_writes
# Enables using versioned writes middleware and exposing configuration
# settings via HTTP GET /info.
# WARNING: Setting this option bypasses the "allow_versions" option
# in the container configuration file, which will be eventually
# deprecated. See documentation for more details.
# allow_versioned_writes = false
# Enables Swift object-versioning API
# allow_object_versioning = false
# Note: Put after auth and before dlo and slo middlewares.
# If you don't put it in the pipeline, it will be inserted for you.
[filter:copy]
use = egg:swift#copy
# Note: To enable encryption, add the following 2 dependent pieces of crypto
# middleware to the proxy-server pipeline. They should be to the right of all
# other middleware apart from the final proxy-logging middleware, and in the
# order shown in this example:
# <other middleware> keymaster encryption proxy-logging proxy-server
[filter:keymaster]
use = egg:swift#keymaster
# Over time, the format of crypto metadata on disk may change slightly to resolve
# ambiguities. In general, you want to be writing the newest version, but to
# ensure that all writes can still be read during rolling upgrades, there's the
# option to write older formats as well.
# Before upgrading from Swift 2.20.0 or Swift 2.19.1 or earlier, ensure this is set to 1
# Before upgrading from Swift 2.25.0 or earlier, ensure this is set to at most 2
# After upgrading all proxy servers, set this to 3 (currently the highest version)
#
# The default is currently 2 to support upgrades with no configuration changes,
# but may change to 3 in the future.
meta_version_to_write = 2
# Sets the root secret from which encryption keys are derived. This must be set
# before first use to a value that is a base64 encoding of at least 32 bytes.
# The security of all encrypted data critically depends on this key, therefore
# it should be set to a high-entropy value. For example, a suitable value may
# be obtained by base-64 encoding a 32 byte (or longer) value generated by a
# cryptographically secure random number generator. Changing the root secret is
# likely to result in data loss.
encryption_root_secret = Q8C5Ioo+wYDl+MACY0WHRQsGNwalIQ0lW4rGHt/41i4=
# Multiple root secrets may be configured using options named
# 'encryption_root_secret_<secret_id>' where 'secret_id' is a unique
# identifier. This enables the root secret to be changed from time to time.
# Only one root secret is used for object PUTs or POSTs at any moment in time.
# This is specified by the 'active_root_secret_id' option. If
# 'active_root_secret_id' is not specified then the root secret specified by
# 'encryption_root_secret' is considered to be the default. Once a root secret
# has been used as the default root secret it must remain in the config file in
# order that any objects that were encrypted with it may be subsequently
# decrypted. The secret_id used to identify the key cannot change.
# encryption_root_secret_myid = changeme
# active_root_secret_id = myid
# Sets the path from which the keymaster config options should be read. This
# allows multiple processes which need to be encryption-aware (for example,
# proxy-server and container-sync) to share the same config file, ensuring
# that the encryption keys used are the same. The format expected is similar
# to other config files, with a single [keymaster] section and a single
# encryption_root_secret option. If this option is set, the root secret
# MUST NOT be set in proxy-server.conf.
# keymaster_config_path =
# To store the encryption root secret in a remote key management system (KMS)
# such as Barbican, replace the keymaster middleware with the kms_keymaster
# middleware in the proxy-server pipeline. They should be to the right of all
# other middleware apart from the final proxy-logging middleware, and in the
# order shown in this example:
# <other middleware> kms_keymaster encryption proxy-logging proxy-server
[filter:kms_keymaster]
use = egg:swift#kms_keymaster
# Sets the path from which the keymaster config options should be read. This
# allows multiple processes which need to be encryption-aware (for example,
# proxy-server and container-sync) to share the same config file, ensuring
# that the encryption keys used are the same. The format expected is similar
# to other config files, with a single [kms_keymaster] section. See the
# keymaster.conf-sample file for details on the kms_keymaster configuration
# options.
# keymaster_config_path =
# kmip_keymaster middleware may be used to fetch an encryption root secret from
# a KMIP service. It should replace, in the same position, any other keymaster
# middleware in the proxy-server pipeline, so that the middleware order is as
# shown in this example:
# <other middleware> kmip_keymaster encryption proxy-logging proxy-server
[filter:kmip_keymaster]
use = egg:swift#kmip_keymaster
# Sets the path from which the keymaster config options should be read. This
# allows multiple processes which need to be encryption-aware (for example,
# proxy-server and container-sync) to share the same config file, ensuring
# that the encryption keys used are the same. As an added benefit the
# keymaster configuration file can have different permissions than the
# `proxy-server.conf` file. The format expected is similar
# to other config files, with a single [kmip_keymaster] section. See the
# keymaster.conf-sample file for details on the kmip_keymaster configuration
# options.
# keymaster_config_path =
[filter:encryption]
use = egg:swift#encryption
# By default all PUT or POST'ed object data and/or metadata will be encrypted.
# Encryption of new data and/or metadata may be disabled by setting
# disable_encryption to True. However, all encryption middleware should remain
# in the pipeline in order for existing encrypted data to be read.
# disable_encryption = False
# listing_formats should be just right of the first proxy-logging middleware,
# and left of most other middlewares. If it is not already present, it will
# be automatically inserted for you.
[filter:listing_formats]
use = egg:swift#listing_formats
# Note: Put after slo, dlo, versioned_writes, but before encryption in the
# pipeline.
[filter:symlink]
use = egg:swift#symlink
# Symlinks can point to other symlinks provided the number of symlinks in a
# chain does not exceed the symloop_max value. If the number of chained
# symlinks exceeds the limit symloop_max a 409 (HTTPConflict) error
# response will be produced.
# symloop_max = 2
OEF6. Tạo account ring trên Controller Node.
Di chuyển vào /etc/swift.
cd /etc/swiftTạo file account.builder cơ bản bằng cách sử dụng lệnh dưới.
swift-ring-builder account.builder create 10 3 1Thêm mỗi storage node vào ring bằng cách sử dụng lệnh swift-ring-builder account.builder add.
swift-ring-builder account.builder \
add --region 1 --zone 1 --ip 10.237.7.82 --port 6202 \
--device sdb --weight 100
swift-ring-builder account.builder \
add --region 1 --zone 1 --ip 10.237.7.82 --port 6202 \
--device sdc --weight 100
swift-ring-builder account.builder \
add --region 1 --zone 1 --ip 10.237.7.82 --port 6202 \
--device sdd --weight 100
swift-ring-builder account.builder \
add --region 1 --zone 2 --ip 10.237.7.83 --port 6202 \
--device sdb --weight 100
swift-ring-builder account.builder \
add --region 1 --zone 2 --ip 10.237.7.83 --port 6202 \
--device sdc --weight 100
swift-ring-builder account.builder \
add --region 1 --zone 2 --ip 10.237.7.83 --port 6202 \
--device sdd --weight 100Xác minh nội dung của account ring.
swift-ring-builder account.builderRebalance account ring.
swift-ring-builder account.builder rebalance7. Tạo container ring trên Controller Node.
Di chuyển vào /etc/swift.
cd /etc/swiftTạo file container.builder cơ bản bằng cách sử dụng lệnh dưới.
swift-ring-builder container.builder create 10 3 1Thêm mỗi storage node vào ring bằng cách sử dụng lệnh swift-ring-builder account.builder add.
swift-ring-builder container.builder \
add --region 1 --zone 1 --ip 10.237.7.82 --port 6201 \
--device sdb --weight 100
swift-ring-builder container.builder \
add --region 1 --zone 1 --ip 10.237.7.82 --port 6201 \
--device sdc --weight 100
swift-ring-builder container.builder \
add --region 1 --zone 1 --ip 10.237.7.82 --port 6201 \
--device sdd --weight 100
swift-ring-builder container.builder \
add --region 1 --zone 2 --ip 10.237.7.83 --port 6201 \
--device sdb --weight 100
swift-ring-builder container.builder \
add --region 1 --zone 2 --ip 10.237.7.83 --port 6201 \
--device sdc --weight 100
swift-ring-builder container.builder \
add --region 1 --zone 2 --ip 10.237.7.83 --port 6201 \
--device sdd --weight 100Xác minh nội dung của container ring.
swift-ring-builder container.builderRebalance container ring.
swift-ring-builder container.builder rebalance8. Tạo object ring trên Controller Node.
Di chuyển vào /etc/swift.
cd /etc/swiftTạo file object.builder cơ bản bằng cách sử dụng lệnh dưới.
swift-ring-builder object.builder create 10 3 1Thêm mỗi storage node vào ring bằng cách sử dụng lệnh swift-ring-builder account.builder add.
swift-ring-builder object.builder add \
--region 1 --zone 1 --ip 10.237.7.82 --port 6200 --device sdb --weight 100
swift-ring-builder object.builder add \
--region 1 --zone 1 --ip 10.237.7.82 --port 6200 --device sdc --weight 100
swift-ring-builder object.builder add \
--region 1 --zone 1 --ip 10.237.7.82 --port 6200 --device sdd --weight 100
swift-ring-builder object.builder add \
--region 1 --zone 2 --ip 10.237.7.83 --port 6200 --device sdb --weight 100
swift-ring-builder object.builder add \
--region 1 --zone 2 --ip 10.237.7.83 --port 6200 --device sdc --weight 100
swift-ring-builder object.builder add \
--region 1 --zone 2 --ip 10.237.7.83 --port 6200 --device sdd --weight 100Xác minh nội dung của object ring.
swift-ring-builder object.builderRebalance object ring.
swift-ring-builder object.builder rebalance9. Cấu hình cho Storage Node.
9.1. Đồng bộ thời gian với Controller Node.
Cập nhật danh sách gói.
apt updateĐồng bộ thời gian cho Storage Node sử dụng NTP Server là Controller Node, hãy cài đặt Chrony.
apt install chrony -yBackup file cấu hình /etc/chrony/chrony.conf.
cp /etc/chrony/chrony.conf /etc/chrony/chrony.conf.bakĐể đồng bộ thời gian cho Storage Node sử dụng NTP Server là Controller Node, hãy xóa hết nội dung trong file /etc/chrony/chrony.conf và thêm vào nội dung server controller iburst.
echo 'server controller iburst' > /etc/chrony/chrony.confKhởi động lại dịch vụ và bật chế độ tự khởi động theo hệ thống.
systemctl restart chrony
systemctl enable chrony
systemctl status chrony | grep active9.2. Cài đặt các gói phần mềm hỗ trợ.
Cài đặt các gói phần mềm hỗ trợ xfsprogs (cung cấp các công cụ để làm việc với hệ thống file system XFS) và rsync (một công cụ để sao chép và đồng bộ hóa dữ liệu).
apt-get install xfsprogs rsync -y9.3. Cấu hình phân vùng ổ đĩa và mount nó vào thư mục lưu trữ.
Format ba disk /dev/sdb, /dev/sdc và /dev/sdd với file system XFS. XFS là một file system hiệu suất cao được thiết kế cho việc xử lý dữ liệu lớn.
mkfs.xfs /dev/sdb
mkfs.xfs /dev/sdc
mkfs.xfs /dev/sddTạo thư mục để mount các thiết bị lưu trữ.
mkdir -p /srv/node/sdb
mkdir -p /srv/node/sdc
mkdir -p /srv/node/sddThêm vào file /etc/fstab nội dung UUID="<UUID của phân vùng ổ đĩa>" <thư mục mount> xfs noatime 0 2 .
Chạy script dưới để thêm thanh nội dung này vào cuối file /etc/fstab.
cat >> /etc/fstab << OEF
UUID="$(blkid -s UUID -o value /dev/sdb)" /srv/node/sdb xfs noatime 0 2
UUID="$(blkid -s UUID -o value /dev/sdc)" /srv/node/sdc xfs noatime 0 2
UUID="$(blkid -s UUID -o value /dev/sdd)" /srv/node/sdd xfs noatime 0 2
OEFNội dung sau khi chỉnh sửa sẽ gần giống như thế này.
shell> cat /etc/fstab
# /etc/fstab: static file system information.
#
# Use 'blkid' to print the universally unique identifier for a
# device; this may be used with UUID= as a more robust way to name devices
# that works even if disks are added and removed. See fstab(5).
#
# <file system> <mount point> <type> <options> <dump> <pass>
# / was on /dev/ubuntu-vg/ubuntu-lv during curtin installation
/dev/disk/by-id/dm-uuid-LVM-fcHHvSBuv7hw2U2ofsisGXs4h0nmUr2aHsdHCvvPj9rjRVtiqA7OT8ts2pfvhWlr / ext4 defaults 0 1
# /boot was on /dev/sda2 during curtin installation
/dev/disk/by-uuid/11416ec0-4512-4649-b042-47e2a63e5d57 /boot ext4 defaults 0 1
/swap.img none swap sw 0 0
UUID="5396125a-f652-42c1-b536-96cfc166ef5b" /srv/node/sdb xfs noatime 0 2
UUID="22a8af4f-5e35-4fae-9e45-76793584df23" /srv/node/sdc xfs noatime 0 2
UUID="1b29b531-7dd9-4da0-ba19-2be54db8528e" /srv/node/sdd xfs noatime 0 2Mount các thiết bị lưu trữ đã chỉ định trong file /etc/fstab.
mount -aKết quả sau khi mount thành công.
shell> df -h | grep /srv/node
/dev/sdb 30G 247M 30G 1% /srv/node/sdb
/dev/sdc 30G 247M 30G 1% /srv/node/sdc
/dev/sdd 30G 247M 30G 1% /srv/node/sdd9.4. Cấu hình Rsync.
Tạo hoặc chỉnh sửa file /etc/rsyncd.conf để cấu hình dịch vụ rsync, một dịch vụ cho phép sao chép và đồng bộ hóa dữ liệu giữa các máy chủ.
Đối với Storage 1 – 10.237.7.82.
cat > /etc/rsyncd.conf << 'OEF'
uid = swift
gid = swift
log file = /var/log/rsyncd.log
pid file = /var/run/rsyncd.pid
address = 10.237.7.82
[account]
max connections = 2
path = /srv/node/
read only = False
lock file = /var/lock/account.lock
[container]
max connections = 2
path = /srv/node/
read only = False
lock file = /var/lock/container.lock
[object]
max connections = 2
path = /srv/node/
read only = False
lock file = /var/lock/object.lock
OEFĐối với Storage 2 – 10.237.7.83.
cat > /etc/rsyncd.conf << 'OEF'
uid = swift
gid = swift
log file = /var/log/rsyncd.log
pid file = /var/run/rsyncd.pid
address = 10.237.7.83
[account]
max connections = 2
path = /srv/node/
read only = False
lock file = /var/lock/account.lock
[container]
max connections = 2
path = /srv/node/
read only = False
lock file = /var/lock/container.lock
[object]
max connections = 2
path = /srv/node/
read only = False
lock file = /var/lock/object.lock
OEFChỉnh sửa file /etc/default/rsync để kích hoạt dịch vụ rsync.
sed -i 's/RSYNC_ENABLE=false/RSYNC_ENABLE=true/g' /etc/default/rsyncKhởi động dịch vụ rsync.
systemctl restart rsync
systemctl enable rsync
systemctl status rsync | grep activeLưu ý: Dịch vụ rsync không yêu cầu xác thực vì vậy hãy cân nhắc việc chạy dịch vụ này trên private network.
9.5. Cài đặt và cấu hình accounting, container và object service.
apt-get install swift swift-account swift-container swift-object -yBạn có thể file mẫu account-server.conf-sample, container-server.conf-sample và object-server.conf-sample lưu về thư mục /etc/swift/ để tự chỉnh sửa hoặc nếu không muốn tự chỉnh sửa thì bỏ qua bước này và làm tiếp bước tiếp theo để sử dụng file mẫu của mình.
curl -o /etc/swift/account-server.conf https://opendev.org/openstack/swift/raw/branch/master/etc/account-server.conf-sample
curl -o /etc/swift/container-server.conf https://opendev.org/openstack/swift/raw/branch/master/etc/container-server.conf-sample
curl -o /etc/swift/object-server.conf https://opendev.org/openstack/swift/raw/branch/master/etc/object-server.conf-sampleNội dung chỉnh sửa các file account-server.conf-sample, container-server.conf-sample và object-server.conf-sampleaccount-server.conf, container-server.confvà object-server.confvà mình không giải thích gì thêm.
Đối với file /etc/swift/account-server.conf.
cat > /etc/swift/account-server.conf << 'OEF'
[DEFAULT]
bind_ip = 10.237.7.83
bind_port = 6202
# keep_idle = 600
# bind_timeout = 30
# backlog = 4096
user = swift
swift_dir = /etc/swift
devices = /srv/node
mount_check = true
# disable_fallocate = false
#
# Use an integer to override the number of pre-forked processes that will
# accept connections.
# workers = auto
#
# Maximum concurrent requests per worker
# max_clients = 1024
#
# You can specify default log routing here if you want:
# log_name = swift
# log_facility = LOG_LOCAL0
# log_level = INFO
# log_address = /dev/log
# The following caps the length of log lines to the value given; no limit if
# set to 0, the default.
# log_max_line_length = 0
#
# Hashing algorithm for log anonymization. Must be one of algorithms supported
# by Python's hashlib.
# log_anonymization_method = MD5
#
# Salt added during log anonymization
# log_anonymization_salt =
#
# Template used to format logs. All words surrounded by curly brackets
# will be substituted with the appropriate values
# log_format = {remote_addr} - - [{time.d}/{time.b}/{time.Y}:{time.H}:{time.M}:{time.S} +0000] "{method} {path}" {status} {content_length} "{referer}" "{txn_id}" "{user_agent}" {trans_time:.4f} "{additional_info}" {pid} {policy_index}
#
# comma separated list of functions to call to setup custom log handlers.
# functions get passed: conf, name, log_to_console, log_route, fmt, logger,
# adapted_logger
# log_custom_handlers =
#
# If set, log_udp_host will override log_address
# log_udp_host =
# log_udp_port = 514
#
# You can enable StatsD logging here:
# log_statsd_host =
# log_statsd_port = 8125
# log_statsd_default_sample_rate = 1.0
# log_statsd_sample_rate_factor = 1.0
# log_statsd_metric_prefix =
#
# If you don't mind the extra disk space usage in overhead, you can turn this
# on to preallocate disk space with SQLite databases to decrease fragmentation.
# db_preallocation = off
#
# Enable this option to log all sqlite3 queries (requires python >=3.3)
# db_query_logging = off
#
# eventlet_debug = false
#
# You can set fallocate_reserve to the number of bytes or percentage of disk
# space you'd like fallocate to reserve, whether there is space for the given
# file size or not. Percentage will be used if the value ends with a '%'.
# fallocate_reserve = 1%
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are IOPRIO_CLASS_RT (realtime), IOPRIO_CLASS_BE (best-effort) and
# IOPRIO_CLASS_IDLE (idle). I/O niceness priority is a number which goes from
# 0 to 7. The higher the value, the lower the I/O priority of the process.
# Work only with ionice_class.
# ionice_class =
# ionice_priority =
[pipeline:main]
pipeline = healthcheck recon account-server
[app:account-server]
use = egg:swift#account
# You can override the default log routing for this app here:
# set log_name = account-server
# set log_facility = LOG_LOCAL0
# set log_level = INFO
# set log_requests = true
# set log_address = /dev/log
#
# You can disable REPLICATE handling (default is to allow it). When deploying
# a cluster with a separate replication network, you'll want multiple
# account-server processes running: one for client-driven traffic and another
# for replication traffic. The server handling client-driven traffic may set
# this to false. If there is only one account-server process, leave this as
# true.
# replication_server = true
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are IOPRIO_CLASS_RT (realtime), IOPRIO_CLASS_BE (best-effort) and
# IOPRIO_CLASS_IDLE (idle). I/O niceness priority is a number which goes from
# 0 to 7. The higher the value, the lower the I/O priority of the process.
# Work only with ionice_class.
# ionice_class =
# ionice_priority =
#
# You can set fallocate_reserve to the number of bytes or percentage
# of disk space you'd like kept free at all times. If the disk's free
# space falls below this value, then PUT, POST, and REPLICATE requests
# will be denied until the disk ha s more space available. Percentage
# will be used if the value ends with a '%'.
# fallocate_reserve = 1%
[filter:healthcheck]
use = egg:swift#healthcheck
# An optional filesystem path, which if present, will cause the healthcheck
# URL to return "503 Service Unavailable" with a body of "DISABLED BY FILE"
# disable_path =
[filter:recon]
use = egg:swift#recon
recon_cache_path = /var/cache/swift
[filter:backend_ratelimit]
use = egg:swift#backend_ratelimit
# Set the maximum rate of requests per second per device per worker. Beyond
# this rate the server will return 529 responses and emit a 'backend.ratelimit'
# statsd metric without logging. The default value of zero causes no
# rate-limiting to be applied.
# requests_per_device_per_second = 0.0
#
# Set the number of seconds of unused rate-limiting allowance that can
# accumulate and be used to allow a subsequent burst of requests.
# requests_per_device_rate_buffer = 1.0
[account-replicator]
# You can override the default log routing for this app here (don't use set!):
# log_name = account-replicator
# log_facility = LOG_LOCAL0
# log_level = INFO
# log_address = /dev/log
#
# Maximum number of database rows that will be sync'd in a single HTTP
# replication request. Databases with less than or equal to this number of
# differing rows will always be sync'd using an HTTP replication request rather
# than using rsync.
# per_diff = 1000
#
# Maximum number of HTTP replication requests attempted on each replication
# pass for any one container. This caps how long the replicator will spend
# trying to sync a given database per pass so the other databases don't get
# starved.
# max_diffs = 100
#
# Number of replication workers to spawn.
# concurrency = 8
#
# Time in seconds to wait between replication passes
# interval = 30.0
# run_pause is deprecated, use interval instead
# run_pause = 30.0
#
# Process at most this many databases per second
# databases_per_second = 50
#
# node_timeout = 10
# conn_timeout = 0.5
#
# The replicator also performs reclamation
# reclaim_age = 604800
#
# Allow rsync to compress data which is transmitted to destination node
# during sync. However, this is applicable only when destination node is in
# a different region than the local one.
# rsync_compress = no
#
# Format of the rsync module where the replicator will send data. See
# etc/rsyncd.conf-sample for some usage examples.
# rsync_module = {replication_ip}::account
#
# recon_cache_path = /var/cache/swift
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are IOPRIO_CLASS_RT (realtime), IOPRIO_CLASS_BE (best-effort) and
# IOPRIO_CLASS_IDLE (idle). I/O niceness priority is a number which goes from
# 0 to 7. The higher the value, the lower the I/O priority of the process.
# Work only with ionice_class.
# ionice_class =
# ionice_priority =
#
# The handoffs_only and handoff_delete options are for special-case emergency
# situations such as full disks in the cluster. These options SHOULD NOT
# BE ENABLED except in emergencies. When handoffs_only mode is enabled
# the replicator will *only* replicate from handoff nodes to primary
# nodes and will not sync primary nodes with other primary nodes.
#
# This has two main effects: first, the replicator becomes much more
# effective at removing misplaced databases, thereby freeing up disk
# space at a much faster pace than normal. Second, the replicator does
# not sync data between primary nodes, so out-of-sync account and
# container listings will not resolve while handoffs_only is enabled.
#
# This mode is intended to allow operators to temporarily sacrifice
# consistency in order to gain faster rebalancing, such as during a
# capacity addition with nearly-full disks. It is not intended for
# long-term use.
#
# handoffs_only = no
#
# handoff_delete is the number of replicas which are ensured in swift.
# If the number less than the number of replicas is set, account-replicator
# could delete local handoffs even if all replicas are not ensured in the
# cluster. The replicator would remove local handoff account database after
# syncing when the number of successful responses is greater than or equal to
# this number. By default(auto), handoff partitions will be
# removed when it has successfully replicated to all the canonical nodes.
# handoff_delete = auto
[account-auditor]
# You can override the default log routing for this app here (don't use set!):
# log_name = account-auditor
# log_facility = LOG_LOCAL0
# log_level = INFO
# log_address = /dev/log
#
# Will audit each account at most once per interval
# interval = 1800.0
#
# accounts_per_second = 200
# recon_cache_path = /var/cache/swift
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are IOPRIO_CLASS_RT (realtime), IOPRIO_CLASS_BE (best-effort) and
# IOPRIO_CLASS_IDLE (idle). I/O niceness priority is a number which goes from
# 0 to 7. The higher the value, the lower the I/O priority of the process.
# Work only with ionice_class.
# ionice_class =
# ionice_priority =
[account-reaper]
# You can override the default log routing for this app here (don't use set!):
# log_name = account-reaper
# log_facility = LOG_LOCAL0
# log_level = INFO
# log_address = /dev/log
#
# concurrency = 25
# interval = 3600.0
# node_timeout = 10
# conn_timeout = 0.5
#
# Normally, the reaper begins deleting account information for deleted accounts
# immediately; you can set this to delay its work however. The value is in
# seconds; 2592000 = 30 days for example. The sum of this value and the
# container-updater interval should be less than the account-replicator
# reclaim_age. This ensures that once the account-reaper has deleted a
# container there is sufficient time for the container-updater to report to the
# account before the account DB is removed.
# delay_reaping = 0
#
# If the account fails to be reaped due to a persistent error, the
# account reaper will log a message such as:
# Account <name> has not been reaped since <date>
# You can search logs for this message if space is not being reclaimed
# after you delete account(s).
# Default is 2592000 seconds (30 days). This is in addition to any time
# requested by delay_reaping.
# reap_warn_after = 2592000
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are IOPRIO_CLASS_RT (realtime), IOPRIO_CLASS_BE (best-effort) and
# IOPRIO_CLASS_IDLE (idle). I/O niceness priority is a number which goes from
# 0 to 7. The higher the value, the lower the I/O priority of the process.
# Work only with ionice_class.
# ionice_class =
# ionice_priority =
# Note: Put it at the beginning of the pipeline to profile all middleware. But
# it is safer to put this after healthcheck.
[filter:xprofile]
use = egg:swift#xprofile
# This option enable you to switch profilers which should inherit from python
# standard profiler. Currently the supported value can be 'cProfile',
# 'eventlet.green.profile' etc.
# profile_module = eventlet.green.profile
#
# This prefix will be used to combine process ID and timestamp to name the
# profile data file. Make sure the executing user has permission to write
# into this path (missing path segments will be created, if necessary).
# If you enable profiling in more than one type of daemon, you must override
# it with an unique value like: /var/log/swift/profile/account.profile
# log_filename_prefix = /tmp/log/swift/profile/default.profile
#
# the profile data will be dumped to local disk based on above naming rule
# in this interval.
# dump_interval = 5.0
#
# Be careful, this option will enable profiler to dump data into the file with
# time stamp which means there will be lots of files piled up in the directory.
# dump_timestamp = false
#
# This is the path of the URL to access the mini web UI.
# path = /__profile__
#
# Clear the data when the wsgi server shutdown.
# flush_at_shutdown = false
#
# unwind the iterator of applications
# unwind = false
OEFĐối với file /etc/swift/container-server.conf.
cat > /etc/swift/container-server.conf << 'OEF'
[DEFAULT]
bind_ip = 10.237.7.83
bind_port = 6201
# keep_idle = 600
# bind_timeout = 30
# backlog = 4096
user = swift
swift_dir = /etc/swift
devices = /srv/node
mount_check = true
# disable_fallocate = false
#
# Use an integer to override the number of pre-forked processes that will
# accept connections.
# workers = auto
#
# Maximum concurrent requests per worker
# max_clients = 1024
#
# This is a comma separated list of hosts allowed in the X-Container-Sync-To
# field for containers. This is the old-style of using container sync. It is
# strongly recommended to use the new style of a separate
# container-sync-realms.conf -- see container-sync-realms.conf-sample
# allowed_sync_hosts = 127.0.0.1
#
# You can specify default log routing here if you want:
# log_name = swift
# log_facility = LOG_LOCAL0
# log_level = INFO
# log_address = /dev/log
# The following caps the length of log lines to the value given; no limit if
# set to 0, the default.
# log_max_line_length = 0
#
# Hashing algorithm for log anonymization. Must be one of algorithms supported
# by Python's hashlib.
# log_anonymization_method = MD5
#
# Salt added during log anonymization
# log_anonymization_salt =
#
# Template used to format logs. All words surrounded by curly brackets
# will be substituted with the appropriate values
# log_format = {remote_addr} - - [{time.d}/{time.b}/{time.Y}:{time.H}:{time.M}:{time.S} +0000] "{method} {path}" {status} {content_length} "{referer}" "{txn_id}" "{user_agent}" {trans_time:.4f} "{additional_info}" {pid} {policy_index}
#
# comma separated list of functions to call to setup custom log handlers.
# functions get passed: conf, name, log_to_console, log_route, fmt, logger,
# adapted_logger
# log_custom_handlers =
#
# If set, log_udp_host will override log_address
# log_udp_host =
# log_udp_port = 514
#
# You can enable StatsD logging here:
# log_statsd_host =
# log_statsd_port = 8125
# log_statsd_default_sample_rate = 1.0
# log_statsd_sample_rate_factor = 1.0
# log_statsd_metric_prefix =
#
# If you don't mind the extra disk space usage in overhead, you can turn this
# on to preallocate disk space with SQLite databases to decrease fragmentation.
# db_preallocation = off
#
# Enable this option to log all sqlite3 queries (requires python >=3.3)
# db_query_logging = off
#
# eventlet_debug = false
#
# You can set fallocate_reserve to the number of bytes or percentage of disk
# space you'd like fallocate to reserve, whether there is space for the given
# file size or not. Percentage will be used if the value ends with a '%'.
# fallocate_reserve = 1%
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are IOPRIO_CLASS_RT (realtime), IOPRIO_CLASS_BE (best-effort) and
# IOPRIO_CLASS_IDLE (idle). I/O niceness priority is a number which goes from
# 0 to 7. The higher the value, the lower the I/O priority of the process.
# Work only with ionice_class.
# ionice_class =
# ionice_priority =
[pipeline:main]
pipeline = healthcheck recon container-server
[app:container-server]
use = egg:swift#container
# You can override the default log routing for this app here:
# set log_name = container-server
# set log_facility = LOG_LOCAL0
# set log_level = INFO
# set log_requests = true
# set log_address = /dev/log
#
# node_timeout = 3
# conn_timeout = 0.5
# allow_versions = false
#
# You can disable REPLICATE handling (default is to allow it). When deploying
# a cluster with a separate replication network, you'll want multiple
# container-server processes running: one for client-driven traffic and another
# for replication traffic. The server handling client-driven traffic may set
# this to false. If there is only one container-server process, leave this as
# true.
# replication_server = true
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are IOPRIO_CLASS_RT (realtime), IOPRIO_CLASS_BE (best-effort) and
# IOPRIO_CLASS_IDLE (idle). I/O niceness priority is a number which goes from
# 0 to 7. The higher the value, the lower the I/O priority of the process.
# Work only with ionice_class.
# ionice_class =
# ionice_priority =
#
# You can set fallocate_reserve to the number of bytes or percentage
# of disk space you'd like kept free at all times. If the disk's free
# space falls below this value, then PUT, POST, and REPLICATE requests
# will be denied until the disk ha s more space available. Percentage
# will be used if the value ends with a '%'.
# fallocate_reserve = 1%
[filter:healthcheck]
use = egg:swift#healthcheck
# An optional filesystem path, which if present, will cause the healthcheck
# URL to return "503 Service Unavailable" with a body of "DISABLED BY FILE"
# disable_path =
[filter:recon]
use = egg:swift#recon
recon_cache_path = /var/cache/swift
[filter:backend_ratelimit]
use = egg:swift#backend_ratelimit
# Set the maximum rate of requests per second per device per worker. Beyond
# this rate the server will return 529 responses and emit a 'backend.ratelimit'
# statsd metric without logging. The default value of zero causes no
# rate-limiting to be applied.
# requests_per_device_per_second = 0.0
#
# Set the number of seconds of unused rate-limiting allowance that can
# accumulate and be used to allow a subsequent burst of requests.
# requests_per_device_rate_buffer = 1.0
[container-replicator]
# You can override the default log routing for this app here (don't use set!):
# log_name = container-replicator
# log_facility = LOG_LOCAL0
# log_level = INFO
# log_address = /dev/log
#
# Maximum number of database rows that will be sync'd in a single HTTP
# replication request. Databases with less than or equal to this number of
# differing rows will always be sync'd using an HTTP replication request rather
# than using rsync.
# per_diff = 1000
#
# Maximum number of HTTP replication requests attempted on each replication
# pass for any one container. This caps how long the replicator will spend
# trying to sync a given database per pass so the other databases don't get
# starved.
# max_diffs = 100
#
# Number of replication workers to spawn.
# concurrency = 8
#
# Time in seconds to wait between replication passes
# interval = 30.0
# run_pause is deprecated, use interval instead
# run_pause = 30.0
#
# Process at most this many databases per second
# databases_per_second = 50
#
# node_timeout = 10
# conn_timeout = 0.5
#
# The replicator also performs reclamation
# reclaim_age = 604800
#
# Allow rsync to compress data which is transmitted to destination node
# during sync. However, this is applicable only when destination node is in
# a different region than the local one.
# rsync_compress = no
#
# Format of the rsync module where the replicator will send data. See
# etc/rsyncd.conf-sample for some usage examples.
# rsync_module = {replication_ip}::container
#
# recon_cache_path = /var/cache/swift
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are IOPRIO_CLASS_RT (realtime), IOPRIO_CLASS_BE (best-effort) and
# IOPRIO_CLASS_IDLE (idle). I/O niceness priority is a number which goes from
# 0 to 7. The higher the value, the lower the I/O priority of the process.
# Work only with ionice_class.
# ionice_class =
# ionice_priority =
#
# The handoffs_only and handoff_delete options are for special-case emergency
# situations such as full disks in the cluster. These options SHOULD NOT
# BE ENABLED except in emergencies. When handoffs_only mode is enabled
# the replicator will *only* replicate from handoff nodes to primary
# nodes and will not sync primary nodes with other primary nodes.
#
# This has two main effects: first, the replicator becomes much more
# effective at removing misplaced databases, thereby freeing up disk
# space at a much faster pace than normal. Second, the replicator does
# not sync data between primary nodes, so out-of-sync account and
# container listings will not resolve while handoffs_only is enabled.
#
# This mode is intended to allow operators to temporarily sacrifice
# consistency in order to gain faster rebalancing, such as during a
# capacity addition with nearly-full disks. It is not intended for
# long-term use.
#
# handoffs_only = no
#
# handoff_delete is the number of replicas which are ensured in swift.
# If the number less than the number of replicas is set, container-replicator
# could delete local handoffs even if all replicas are not ensured in the
# cluster. The replicator would remove local handoff container database after
# syncing when the number of successful responses is greater than or equal to
# this number. By default(auto), handoff partitions will be
# removed when it has successfully replicated to all the canonical nodes.
# handoff_delete = auto
[container-updater]
# You can override the default log routing for this app here (don't use set!):
# log_name = container-updater
# log_facility = LOG_LOCAL0
# log_level = INFO
# log_address = /dev/log
#
# interval = 300.0
# concurrency = 4
# node_timeout = 3
# conn_timeout = 0.5
#
# Send at most this many container updates per second
# containers_per_second = 50
#
# slowdown will sleep that amount between containers. Deprecated; use
# containers_per_second instead.
# slowdown = 0.01
#
# Seconds to suppress updating an account that has generated an error
# account_suppression_time = 60
#
# recon_cache_path = /var/cache/swift
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are IOPRIO_CLASS_RT (realtime), IOPRIO_CLASS_BE (best-effort) and
# IOPRIO_CLASS_IDLE (idle). I/O niceness priority is a number which goes from
# 0 to 7. The higher the value, the lower the I/O priority of the process.
# Work only with ionice_class.
# ionice_class =
# ionice_priority =
[container-auditor]
# You can override the default log routing for this app here (don't use set!):
# log_name = container-auditor
# log_facility = LOG_LOCAL0
# log_level = INFO
# log_address = /dev/log
#
# Will audit each container at most once per interval
# interval = 1800.0
#
# containers_per_second = 200
# recon_cache_path = /var/cache/swift
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are IOPRIO_CLASS_RT (realtime), IOPRIO_CLASS_BE (best-effort) and
# IOPRIO_CLASS_IDLE (idle). I/O niceness priority is a number which goes from
# 0 to 7. The higher the value, the lower the I/O priority of the process.
# Work only with ionice_class.
# ionice_class =
# ionice_priority =
[container-sync]
# You can override the default log routing for this app here (don't use set!):
# log_name = container-sync
# log_facility = LOG_LOCAL0
# log_level = INFO
# log_address = /dev/log
#
# If you need to use an HTTP Proxy, set it here; defaults to no proxy.
# You can also set this to a comma separated list of HTTP Proxies and they will
# be randomly used (simple load balancing).
# sync_proxy = http://10.1.1.1:8888,http://10.1.1.2:8888
#
# Will sync each container at most once per interval
# interval = 300.0
#
# Maximum amount of time to spend syncing each container per pass
# container_time = 60
#
# Maximum amount of time in seconds for the connection attempt
# conn_timeout = 5
# Server errors from requests will be retried by default
# request_tries = 3
#
# Internal client config file path
# internal_client_conf_path = /etc/swift/internal-client.conf
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are IOPRIO_CLASS_RT (realtime), IOPRIO_CLASS_BE (best-effort) and
# IOPRIO_CLASS_IDLE (idle). I/O niceness priority is a number which goes from
# 0 to 7. The higher the value, the lower the I/O priority of the process.
# Work only with ionice_class.
# ionice_class =
# ionice_priority =
# Note: Put it at the beginning of the pipeline to profile all middleware. But
# it is safer to put this after healthcheck.
[filter:xprofile]
use = egg:swift#xprofile
# This option enable you to switch profilers which should inherit from python
# standard profiler. Currently the supported value can be 'cProfile',
# 'eventlet.green.profile' etc.
# profile_module = eventlet.green.profile
#
# This prefix will be used to combine process ID and timestamp to name the
# profile data file. Make sure the executing user has permission to write
# into this path (missing path segments will be created, if necessary).
# If you enable profiling in more than one type of daemon, you must override
# it with an unique value like: /var/log/swift/profile/container.profile
# log_filename_prefix = /tmp/log/swift/profile/default.profile
#
# the profile data will be dumped to local disk based on above naming rule
# in this interval.
# dump_interval = 5.0
#
# Be careful, this option will enable profiler to dump data into the file with
# time stamp which means there will be lots of files piled up in the directory.
# dump_timestamp = false
#
# This is the path of the URL to access the mini web UI.
# path = /__profile__
#
# Clear the data when the wsgi server shutdown.
# flush_at_shutdown = false
#
# unwind the iterator of applications
# unwind = false
[container-sharder]
# You can override the default log routing for this app here (don't use set!):
# log_name = container-sharder
# log_facility = LOG_LOCAL0
# log_level = INFO
# log_address = /dev/log
#
# Container sharder specific settings
#
# If the auto_shard option is true then the sharder will automatically select
# containers to shard, scan for shard ranges, and select shards to shrink.
# The default is false.
# Warning: auto-sharding is still under development and should not be used in
# production; do not set this option to true in a production cluster.
# auto_shard = false
#
# When auto-sharding is enabled shard_container_threshold defines the object
# count at which a container with container-sharding enabled will start to
# shard. shard_container_threshold also indirectly determines the defaults for
# rows_per_shard, shrink_threshold and expansion_limit.
# shard_container_threshold = 1000000
#
# rows_per_shard determines the initial nominal size of shard containers. The
# default is shard_container_threshold // 2
# rows_per_shard = 500000
#
# Minimum size of the final shard range. If this is greater than one then the
# final shard range may be extended to more than rows_per_shard in order to
# avoid a further shard range with less than minimum_shard_size rows. The
# default value is rows_per_shard // 5.
# minimum_shard_size = 100000
#
# When auto-sharding is enabled shrink_threshold defines the object count
# below which a 'donor' shard container will be considered for shrinking into
# another 'acceptor' shard container. The default is determined by
# shard_shrink_point. If set, shrink_threshold will take precedence over
# shard_shrink_point.
# shrink_threshold =
#
# When auto-sharding is enabled shard_shrink_point defines the object count
# below which a 'donor' shard container will be considered for shrinking into
# another 'acceptor' shard container. shard_shrink_point is a percentage of
# shard_container_threshold e.g. the default value of 10 means 10% of the
# shard_container_threshold.
# Deprecated: shrink_threshold is recommended and if set will take precedence
# over shard_shrink_point.
# shard_shrink_point = 10
#
# When auto-sharding is enabled expansion_limit defines the maximum
# allowed size of an acceptor shard container after having a donor merged into
# it. The default is determined by shard_shrink_merge_point.
# If set, expansion_limit will take precedence over shard_shrink_merge_point.
# expansion_limit =
#
# When auto-sharding is enabled shard_shrink_merge_point defines the maximum
# allowed size of an acceptor shard container after having a donor merged into
# it. Shard_shrink_merge_point is a percentage of shard_container_threshold.
# e.g. the default value of 75 means that the projected sum of a donor object
# count and acceptor count must be less than 75% of shard_container_threshold
# for the donor to be allowed to merge into the acceptor.
#
# For example, if the shard_container_threshold is 1 million,
# shard_shrink_point is 10, and shard_shrink_merge_point is 75 then a shard will
# be considered for shrinking if it has less than or equal to 100 thousand
# objects but will only merge into an acceptor if the combined object count
# would be less than or equal to 750 thousand objects.
# Deprecated: expansion_limit is recommended and if set will take precedence
# over shard_shrink_merge_point.
# shard_shrink_merge_point = 75
#
# When auto-sharding is enabled shard_scanner_batch_size defines the maximum
# number of shard ranges that will be found each time the sharder daemon visits
# a sharding container. If necessary the sharder daemon will continue to search
# for more shard ranges each time it visits the container.
# shard_scanner_batch_size = 10
#
# cleave_batch_size defines the number of shard ranges that will be cleaved
# each time the sharder daemon visits a sharding container.
# cleave_batch_size = 2
#
# cleave_row_batch_size defines the size of batches of object rows read from a
# sharding container and merged to a shard container during cleaving.
# cleave_row_batch_size = 10000
#
# max_expanding defines the maximum number of shards that could be expanded in a
# single cycle of the sharder. Defaults to unlimited (-1).
# max_expanding = -1
#
# max_shrinking defines the maximum number of shards that should be shrunk into
# each expanding shard. Defaults to 1.
# NOTE: Using values greater than 1 may result in temporary gaps in object listings
# until all selected shards have shrunk.
# max_shrinking = 1
#
# Defines the number of successfully replicated shard dbs required when
# cleaving a previously uncleaved shard range before the sharder will progress
# to the next shard range. The value should be less than or equal to the
# container ring replica count. The default of 'auto' causes the container ring
# quorum value to be used. This option only applies to the container-sharder
# replication and does not affect the number of shard container replicas that
# will eventually be replicated by the container-replicator.
# shard_replication_quorum = auto
#
# Defines the number of successfully replicated shard dbs required when
# cleaving a shard range that has been previously cleaved on another node
# before the sharder will progress to the next shard range. The value should be
# less than or equal to the container ring replica count. The default of 'auto'
# causes the shard_replication_quorum value to be used. This option only
# applies to the container-sharder replication and does not affect the number
# of shard container replicas that will eventually be replicated by the
# container-replicator.
# existing_shard_replication_quorum = auto
#
# The sharder uses an internal client to create and make requests to
# containers. The absolute path to the client config file can be configured.
# internal_client_conf_path = /etc/swift/internal-client.conf
#
# The number of time the internal client will retry requests.
# request_tries = 3
#
# Each time the sharder dumps stats to the recon cache file it includes a list
# of containers that appear to need sharding but are not yet sharding. By
# default this list is limited to the top 5 containers, ordered by object
# count. The limit may be changed by setting recon_candidates_limit to an
# integer value. A negative value implies no limit.
# recon_candidates_limit = 5
#
# As the sharder visits each container that's currently sharding it dumps to
# recon their current progress. To be able to mark their progress as completed
# this in-progress check will need to monitor containers that have just
# completed sharding. The recon_sharded_timeout parameter says for how long a
# container whose just finished sharding should be checked by the in-progress
# check. This is to allow anything monitoring the sharding recon dump to have
# enough time to collate and see things complete. The time is capped at
# reclaim_age, so this parameter should be less than or equal to reclaim_age.
# The default is 12 hours (12 x 60 x 60)
# recon_sharded_timeout = 43200
#
# Maximum amount of time in seconds after sharding has been started on a shard
# container and before it's considered as timeout. After this amount of time,
# sharder will warn that a container DB has not completed sharding.
# The default is 48 hours (48 x 60 x 60)
# container_sharding_timeout = 172800
#
# Some sharder states lead to repeated messages of 'Reclaimable db stuck
# waiting for shrinking' on every sharder cycle. To reduce noise in logs,
# this message will be suppressed for some time after its last emission.
# Default is 24 hours.
# periodic_warnings_interval = 86400
#
# Large databases tend to take a while to work with, but we want to make sure
# we write down our progress. Use a larger-than-normal broker timeout to make
# us less likely to bomb out on a LockTimeout.
# broker_timeout = 60
#
# Time in seconds to wait between emitting stats to logs
# stats_interval = 3600.0
#
# Time in seconds to wait between sharder cycles
# interval = 30.0
#
# Process at most this many databases per second
# databases_per_second = 50
#
# The container-sharder accepts the following configuration options as defined
# in the container-replicator section:
#
# per_diff = 1000
# max_diffs = 100
# concurrency = 8
# node_timeout = 10
# conn_timeout = 0.5
# reclaim_age = 604800
# rsync_compress = no
# rsync_module = {replication_ip}::container
# recon_cache_path = /var/cache/swift
#
OEFĐối với file /etc/swift/object-server.conf.
cat > /etc/swift/object-server.conf << 'OEF'
[DEFAULT]
bind_ip = 10.237.7.83
bind_port = 6200
# keep_idle = 600
# bind_timeout = 30
# backlog = 4096
user = swift
swift_dir = /etc/swift
devices = /srv/node
mount_check = true
# disable_fallocate = false
# expiring_objects_container_divisor = 86400
# expiring_objects_account_name = expiring_objects
#
# Use an integer to override the number of pre-forked processes that will
# accept connections. NOTE: if servers_per_port is set, this setting is
# ignored.
# workers = auto
#
# Make object-server run this many worker processes per unique port of "local"
# ring devices across all storage policies. The default value of 0 disables this
# feature.
# servers_per_port = 0
#
# If running in a container, servers_per_port may not be able to use the
# bind_ip to lookup the ports in the ring. You may instead override the port
# lookup in the ring using the ring_ip. Any devices/ports associted with the
# ring_ip will be used when listening on the configured bind_ip address.
# ring_ip = <bind_ip>
#
# Maximum concurrent requests per worker
# max_clients = 1024
#
# You can specify default log routing here if you want:
# log_name = swift
# log_facility = LOG_LOCAL0
# log_level = INFO
# log_address = /dev/log
# The following caps the length of log lines to the value given; no limit if
# set to 0, the default.
# log_max_line_length = 0
#
# Hashing algorithm for log anonymization. Must be one of algorithms supported
# by Python's hashlib.
# log_anonymization_method = MD5
#
# Salt added during log anonymization
# log_anonymization_salt =
#
# Template used to format logs. All words surrounded by curly brackets
# will be substituted with the appropriate values
# log_format = {remote_addr} - - [{time.d}/{time.b}/{time.Y}:{time.H}:{time.M}:{time.S} +0000] "{method} {path}" {status} {content_length} "{referer}" "{txn_id}" "{user_agent}" {trans_time:.4f} "{additional_info}" {pid} {policy_index}
#
# comma separated list of functions to call to setup custom log handlers.
# functions get passed: conf, name, log_to_console, log_route, fmt, logger,
# adapted_logger
# log_custom_handlers =
#
# If set, log_udp_host will override log_address
# log_udp_host =
# log_udp_port = 514
#
# You can enable StatsD logging here:
# log_statsd_host =
# log_statsd_port = 8125
# log_statsd_default_sample_rate = 1.0
# log_statsd_sample_rate_factor = 1.0
# log_statsd_metric_prefix =
#
# eventlet_debug = false
#
# You can set fallocate_reserve to the number of bytes or percentage of disk
# space you'd like fallocate to reserve, whether there is space for the given
# file size or not. Percentage will be used if the value ends with a '%'.
# fallocate_reserve = 1%
#
# Time to wait while attempting to connect to another backend node.
# conn_timeout = 0.5
# Time to wait while sending each chunk of data to another backend node.
# node_timeout = 3
# Time to wait while sending a container update on object update.
# container_update_timeout = 1.0
# Time to wait while receiving each chunk of data from a client or another
# backend node.
# client_timeout = 60.0
#
# network_chunk_size = 65536
# disk_chunk_size = 65536
#
# Reclamation of tombstone files is performed primarily by the replicator and
# the reconstructor but the object-server and object-auditor also reference
# this value - it should be the same for all object services in the cluster,
# and not greater than the container services reclaim_age
# reclaim_age = 604800
#
# Non-durable data files may also get reclaimed if they are older than
# reclaim_age, but not if the time they were written to disk (i.e. mtime) is
# less than commit_window seconds ago. The commit_window also prevents the
# reconstructor removing recently written non-durable data files from a handoff
# node after reverting them to a primary. This gives the object-server a window
# in which to finish a concurrent PUT on a handoff and mark the data durable. A
# commit_window greater than zero is strongly recommended to avoid unintended
# removal of data files that were about to become durable; commit_window should
# be much less than reclaim_age.
# commit_window = 60.0
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are IOPRIO_CLASS_RT (realtime), IOPRIO_CLASS_BE (best-effort) and
# IOPRIO_CLASS_IDLE (idle). I/O niceness priority is a number which goes from
# 0 to 7. The higher the value, the lower the I/O priority of the process.
# Work only with ionice_class.
# ionice_class =
# ionice_priority =
[pipeline:main]
pipeline = healthcheck recon object-server
[app:object-server]
use = egg:swift#object
# You can override the default log routing for this app here:
# set log_name = object-server
# set log_facility = LOG_LOCAL0
# set log_level = INFO
# set log_requests = true
# set log_address = /dev/log
#
# max_upload_time = 86400
#
# slow is the total amount of seconds an object PUT/DELETE request takes at
# least. If it is faster, the object server will sleep this amount of time minus
# the already passed transaction time. This is only useful for simulating slow
# devices on storage nodes during testing and development.
# slow = 0
#
# Objects smaller than this are not evicted from the buffercache once read
# keep_cache_size = 5242880
#
# If true, objects for authenticated GET requests may be kept in buffer cache
# if small enough
# keep_cache_private = false
#
# If true, SLO object's manifest file for GET requests may be kept in buffer cache
# if smaller than 'keep_cache_size'. And this config will only matter when
# 'keep_cache_private' is false.
# keep_cache_slo_manifest = false
#
# cooperative_period defines how frequent object server GET request will
# perform the cooperative yielding during iterating the disk chunks. For
# example, value of '5' will insert one sleep() after every 5 disk_chunk_size
# chunk reads. A value of '0' (the default) will turn off cooperative yielding.
# cooperative_period = 0
#
# on PUTs, sync data every n MB
# mb_per_sync = 512
#
# Comma separated list of headers that can be set in metadata on an object.
# This list is in addition to X-Object-Meta-* headers and cannot include
# Content-Type, etag, Content-Length, or deleted
# allowed_headers = Content-Disposition, Content-Encoding, X-Delete-At, X-Object-Manifest, X-Static-Large-Object, Cache-Control, Content-Language, Expires, X-Robots-Tag
# The number of threads in eventlet's thread pool. Most IO will occur
# in the object server's main thread, but certain "heavy" IO
# operations will occur in separate IO threads, managed by eventlet.
#
# The default value is auto, whose actual value is dependent on the
# servers_per_port value:
#
# - When servers_per_port is zero, the default value of
# eventlet_tpool_num_threads is empty, which uses eventlet's default
# (currently 20 threads).
#
# - When servers_per_port is nonzero, the default value of
# eventlet_tpool_num_threads is 1.
#
# But you may override this value to any integer value.
#
# Note that this value is threads per object-server process, so to
# compute the total number of IO threads on a node, you must multiply
# this by the number of object-server processes on the node.
#
# eventlet_tpool_num_threads = auto
# You can disable REPLICATE and SSYNC handling (default is to allow it). When
# deploying a cluster with a separate replication network, you'll want multiple
# object-server processes running: one for client-driven traffic and another
# for replication traffic. The server handling client-driven traffic may set
# this to false. If there is only one object-server process, leave this as
# true.
# replication_server = true
#
# Set to restrict the number of concurrent incoming SSYNC requests
# Set to 0 for unlimited
# Note that SSYNC requests are only used by the object reconstructor or the
# object replicator when configured to use ssync.
# replication_concurrency = 4
#
# Set to restrict the number of concurrent incoming SSYNC requests per
# device; set to 0 for unlimited requests per device. This can help control
# I/O to each device. This does not override replication_concurrency described
# above, so you may need to adjust both parameters depending on your hardware
# or network capacity.
# replication_concurrency_per_device = 1
#
# Number of seconds to wait for an existing replication device lock before
# giving up.
# replication_lock_timeout = 15
#
# These next two settings control when the SSYNC subrequest handler will
# abort an incoming SSYNC attempt. An abort will occur if there are at
# least threshold number of failures and the value of failures / successes
# exceeds the ratio. The defaults of 100 and 1.0 means that at least 100
# failures have to occur and there have to be more failures than successes for
# an abort to occur.
# replication_failure_threshold = 100
# replication_failure_ratio = 1.0
#
# Use splice() for zero-copy object GETs. This requires Linux kernel
# version 3.0 or greater. If you set "splice = yes" but the kernel
# does not support it, error messages will appear in the object server
# logs at startup, but your object servers should continue to function.
#
# splice = no
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are IOPRIO_CLASS_RT (realtime), IOPRIO_CLASS_BE (best-effort) and
# IOPRIO_CLASS_IDLE (idle). I/O niceness priority is a number which goes from
# 0 to 7. The higher the value, the lower the I/O priority of the process.
# Work only with ionice_class.
# ionice_class =
# ionice_priority =
[filter:healthcheck]
use = egg:swift#healthcheck
# An optional filesystem path, which if present, will cause the healthcheck
# URL to return "503 Service Unavailable" with a body of "DISABLED BY FILE"
# disable_path =
[filter:recon]
use = egg:swift#recon
recon_cache_path = /var/cache/swift
recon_lock_path = /var/lock
[filter:backend_ratelimit]
use = egg:swift#backend_ratelimit
# Set the maximum rate of requests per second per device per worker. Beyond
# this rate the server will return 529 responses and emit a 'backend.ratelimit'
# statsd metric without logging. The default value of zero causes no
# rate-limiting to be applied.
# requests_per_device_per_second = 0.0
#
# Set the number of seconds of unused rate-limiting allowance that can
# accumulate and be used to allow a subsequent burst of requests.
# requests_per_device_rate_buffer = 1.0
[object-replicator]
# You can override the default log routing for this app here (don't use set!):
# log_name = object-replicator
# log_facility = LOG_LOCAL0
# log_level = INFO
# log_address = /dev/log
#
# daemonize = on
#
# Time in seconds to wait between replication passes
# interval = 30.0
# run_pause is deprecated, use interval instead
# run_pause = 30.0
#
# Number of concurrent replication jobs to run. This is per-process,
# so replicator_workers=W and concurrency=C will result in W*C
# replication jobs running at once.
# concurrency = 1
#
# Number of worker processes to use. No matter how big this number is,
# at most one worker per disk will be used. 0 means no forking; all work
# is done in the main process.
# replicator_workers = 0
#
# stats_interval = 300.0
#
# default is rsync, alternative is ssync
# sync_method = rsync
#
# max duration of a partition rsync
# rsync_timeout = 900
#
# bandwidth limit for rsync in kB/s. 0 means unlimited. rsync 3.2.2 and later
# accept suffixed values like 10M or 1.5G; see the --bwlimit option for rsync(1)
# rsync_bwlimit = 0
#
# passed to rsync for both io op timeout and connection timeout
# rsync_io_timeout = 30
#
# Allow rsync to compress data which is transmitted to destination node
# during sync. However, this is applicable only when destination node is in
# a different region than the local one.
# NOTE: Objects that are already compressed (for example: .tar.gz, .mp3) might
# slow down the syncing process.
# rsync_compress = no
#
# Format of the rsync module where the replicator will send data. See
# etc/rsyncd.conf-sample for some usage examples.
# rsync_module = {replication_ip}::object
#
# node_timeout = <whatever's in the DEFAULT section or 10>
# max duration of an http request; this is for REPLICATE finalization calls and
# so should be longer than node_timeout
# http_timeout = 60
#
# attempts to kill all workers if nothing replicates for lockup_timeout seconds
# lockup_timeout = 1800
#
# ring_check_interval = 15.0
# recon_cache_path = /var/cache/swift
#
# By default, per-file rsync transfers are logged at debug if successful and
# error on failure. During large rebalances (which both increase the number
# of diskfiles transferred and increases the likelihood of failures), this
# can overwhelm log aggregation while providing little useful insights.
# Change this to false to disable per-file logging.
# log_rsync_transfers = true
#
# limits how long rsync error log lines are
# 0 means to log the entire line
# rsync_error_log_line_length = 0
#
# handoffs_first and handoff_delete are options for a special case
# such as disk full in the cluster. These two options SHOULD NOT BE
# CHANGED, except for such an extreme situations. (e.g. disks filled up
# or are about to fill up. Anyway, DO NOT let your drives fill up)
# handoffs_first is the flag to replicate handoffs prior to canonical
# partitions. It allows to force syncing and deleting handoffs quickly.
# If set to a True value(e.g. "True" or "1"), partitions
# that are not supposed to be on the node will be replicated first.
# handoffs_first = False
#
# handoff_delete is the number of replicas which are ensured in swift.
# If the number less than the number of replicas is set, object-replicator
# could delete local handoffs even if all replicas are not ensured in the
# cluster. Object-replicator would remove local handoff partition directories
# after syncing partition when the number of successful responses is greater
# than or equal to this number. By default(auto), handoff partitions will be
# removed when it has successfully replicated to all the canonical nodes.
# handoff_delete = auto
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are IOPRIO_CLASS_RT (realtime), IOPRIO_CLASS_BE (best-effort) and
# IOPRIO_CLASS_IDLE (idle). I/O niceness priority is a number which goes from
# 0 to 7. The higher the value, the lower the I/O priority of the process.
# Work only with ionice_class.
# ionice_class =
# ionice_priority =
[object-reconstructor]
# You can override the default log routing for this app here (don't use set!):
# Unless otherwise noted, each setting below has the same meaning as described
# in the [object-replicator] section, however these settings apply to the EC
# reconstructor
#
# log_name = object-reconstructor
# log_facility = LOG_LOCAL0
# log_level = INFO
# log_address = /dev/log
#
# daemonize = on
#
# Time in seconds to wait between reconstruction passes
# interval = 30.0
# run_pause is deprecated, use interval instead
# run_pause = 30.0
#
# Maximum number of worker processes to spawn. Each worker will handle a
# subset of devices. Devices will be assigned evenly among the workers so that
# workers cycle at similar intervals (which can lead to fewer workers than
# requested). You can not have more workers than devices. If you have no
# devices only a single worker is spawned.
# reconstructor_workers = 0
#
# concurrency = 1
# stats_interval = 300.0
# node_timeout = 10
# http_timeout = 60
# lockup_timeout = 1800
# ring_check_interval = 15.0
# recon_cache_path = /var/cache/swift
#
# The handoffs_only mode option is for special case emergency situations during
# rebalance such as disk full in the cluster. This option SHOULD NOT BE
# CHANGED, except for extreme situations. When handoffs_only mode is enabled
# the reconstructor will *only* revert fragments from handoff nodes to primary
# nodes and will not sync primary nodes with neighboring primary nodes. This
# will force the reconstructor to sync and delete handoffs' fragments more
# quickly and minimize the time of the rebalance by limiting the number of
# rebuilds. The handoffs_only option is only for temporary use and should be
# disabled as soon as the emergency situation has been resolved. When
# handoffs_only is not set, the deprecated handoffs_first option will be
# honored as a synonym, but may be ignored in a future release.
# handoffs_only = False
#
# The default strategy for unmounted drives will stage rebuilt data on a
# handoff node until updated rings are deployed. Because fragments are rebuilt
# on offset handoffs based on fragment index and the proxy limits how deep it
# will search for EC frags we restrict how many nodes we'll try. Setting to 0
# will disable rebuilds to handoffs and only rebuild fragments for unmounted
# devices to mounted primaries after a ring change.
# Setting to -1 means "no limit".
# rebuild_handoff_node_count = 2
#
# By default the reconstructor attempts to revert all objects from handoff
# partitions in a single batch using a single SSYNC request. In exceptional
# circumstances max_objects_per_revert can be used to temporarily limit the
# number of objects reverted by each reconstructor revert type job. If more
# than max_objects_per_revert are available in a sender's handoff partition,
# the remaining objects will remain in the handoff partition and will not be
# reverted until the next time the reconstructor visits that handoff partition
# i.e. with this option set, a single cycle of the reconstructor may not
# completely revert all handoff partitions. The option has no effect on
# reconstructor sync type jobs between primary partitions. A value of 0 (the
# default) means there is no limit.
# max_objects_per_revert = 0
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are IOPRIO_CLASS_RT (realtime), IOPRIO_CLASS_BE (best-effort) and
# IOPRIO_CLASS_IDLE (idle). I/O niceness priority is a number which goes from
# 0 to 7. The higher the value, the lower the I/O priority of the process.
# Work only with ionice_class.
# ionice_class =
# ionice_priority =
#
# When upgrading from liberasurecode<=1.5.0, you may want to continue writing
# legacy CRCs until all nodes are upgraded and capabale of reading fragments
# with zlib CRCs. liberasurecode>=1.6.2 checks for the environment variable
# LIBERASURECODE_WRITE_LEGACY_CRC; if set (value doesn't matter), it will use
# its legacy CRC. Set this option to true or false to ensure the environment
# variable is or is not set. Leave the option blank or absent to not touch
# the environment (default). For more information, see
# https://bugs.launchpad.net/liberasurecode/+bug/1886088
# write_legacy_ec_crc =
#
# When attempting to reconstruct a missing fragment on another node from a
# fragment on the local node, the reconstructor may fail to fetch sufficient
# fragments to reconstruct the missing fragment. This may be because most or
# all of the remote fragments have been deleted, and the local fragment is
# stale, in which case the reconstructor will never succeed in reconstructing
# the apparently missing fragment and will log errors. If the object's
# tombstones have been reclaimed then the stale fragment will never be deleted
# (see https://bugs.launchpad.net/swift/+bug/1655608). If an operator suspects
# that stale fragments have been re-introduced to the cluster and is seeing
# error logs similar to those in the bug report, then the quarantine_threshold
# option may be set to a value greater than zero. This enables the
# reconstructor to quarantine the stale fragments when it fails to fetch more
# than the quarantine_threshold number of fragments (including the stale
# fragment) during an attempt to reconstruct. For example, setting the
# quarantine_threshold to 1 would cause a fragment to be quarantined if no
# other fragments can be fetched. The value may be reset to zero after the
# reconstructor has run on all affected nodes and the error logs are no longer
# seen.
# Note: the quarantine_threshold applies equally to all policies, but for each
# policy it is effectively capped at (ec_ndata - 1) so that a fragment is never
# quarantined when sufficient fragments exist to reconstruct the object.
# quarantine_threshold = 0
#
# Fragments are not quarantined until they are older than
# quarantine_age, which defaults to the value of reclaim_age.
# quarantine_age =
#
# Sets the maximum number of nodes to which requests will be made before
# quarantining a fragment. You can use '* replicas' at the end to have it use
# the number given times the number of replicas for the ring being used for the
# requests. The minimum number of nodes to which requests are made is the
# number of replicas for the policy minus 1 (the node on which the fragment is
# to be rebuilt). The minimum is only exceeded if request_node_count is
# greater, and only for the purposes of quarantining.
# request_node_count = 2 * replicas
[object-updater]
# You can override the default log routing for this app here (don't use set!):
# log_name = object-updater
# log_facility = LOG_LOCAL0
# log_level = INFO
# log_address = /dev/log
#
# interval = 300.0
# node_timeout = <whatever's in the DEFAULT section or 10>
#
# updater_workers controls how many processes the object updater will
# spawn, while concurrency controls how many async_pending records
# each updater process will operate on at any one time. With
# concurrency=C and updater_workers=W, there will be up to W*C
# async_pending records being processed at once.
# concurrency = 8
# updater_workers = 1
#
# Send at most this many object updates per second
# objects_per_second = 50
#
# Send at most this many object updates per bucket per second. The value must
# be a float greater than or equal to 0. Set to 0 for unlimited.
# max_objects_per_container_per_second = 0
#
# The per_container ratelimit implementation uses a hashring to constrain
# memory requirements. Orders of magnitude more buckets will use (nominally)
# more memory, but will ratelimit smaller groups of containers. The value must
# be an integer greater than 0.
# per_container_ratelimit_buckets = 1000
#
# Updates that cannot be sent due to per-container rate-limiting may be
# deferred and re-tried at the end of the updater cycle. This option constrains
# the size of the in-memory data structure used to store deferred updates.
# Must be an integer value greater than or equal to 0.
# max_deferred_updates = 10000
#
# slowdown will sleep that amount between objects. Deprecated; use
# objects_per_second instead.
# slowdown = 0.01
#
# Log stats (at INFO level) every report_interval seconds. This
# logging is per-process, so with concurrency > 1, the logs will
# contain one stats log per worker process every report_interval
# seconds.
# report_interval = 300.0
#
# recon_cache_path = /var/cache/swift
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are IOPRIO_CLASS_RT (realtime), IOPRIO_CLASS_BE (best-effort) and
# IOPRIO_CLASS_IDLE (idle). I/O niceness priority is a number which goes from
# 0 to 7. The higher the value, the lower the I/O priority of the process.
# Work only with ionice_class.
# ionice_class =
# ionice_priority =
[object-auditor]
# You can override the default log routing for this app here (don't use set!):
# log_name = object-auditor
# log_facility = LOG_LOCAL0
# log_level = INFO
# log_address = /dev/log
#
# Time in seconds to wait between auditor passes
# interval = 30.0
#
# You can set the disk chunk size that the auditor uses making it larger if
# you like for more efficient local auditing of larger objects
# disk_chunk_size = 65536
# files_per_second = 20
# concurrency = 1
# bytes_per_second = 10000000
# log_time = 3600
# zero_byte_files_per_second = 50
# recon_cache_path = /var/cache/swift
# Takes a comma separated list of ints. If set, the object auditor will
# increment a counter for every object whose size is <= to the given break
# points and report the result after a full scan.
# object_size_stats =
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are IOPRIO_CLASS_RT (realtime), IOPRIO_CLASS_BE (best-effort) and
# IOPRIO_CLASS_IDLE (idle). I/O niceness priority is a number which goes from
# 0 to 7. The higher the value, the lower the I/O priority of the process.
# Work only with ionice_class.
# ionice_class =
# ionice_priority =
# The auditor will cleanup old rsync tempfiles after they are "old
# enough" to delete. You can configure the time elapsed in seconds
# before rsync tempfiles will be unlinked, or the default value of
# "auto" try to use object-replicator's rsync_timeout + 900 and fallback
# to 86400 (1 day).
# rsync_tempfile_timeout = auto
# A comma-separated list of watcher entry points. This lets operators
# programmatically see audited objects.
#
# The entry point group name is "swift.object_audit_watcher". If your
# setup.py has something like this:
#
# entry_points={'swift.object_audit_watcher': [
# 'some_watcher = some_module:Watcher']}
#
# then you would enable it with "watchers = some_package#some_watcher".
# For example, the built-in reference implementation is enabled as
# "watchers = swift#dark_data".
#
# watchers =
# Watcher-specific parameters can be added in a section with a name
# [object-auditor:watcher:some_package#some_watcher]. The following
# example uses the built-in reference watcher.
#
# [object-auditor:watcher:swift#dark_data]
#
# Action type can be 'log' (default), 'delete', or 'quarantine'.
# action=log
#
# The watcher ignores the objects younger than certain minimum age.
# This prevents spurious actions upon fresh objects while container
# listings eventually settle.
# grace_age=604800
[object-expirer]
# If this true, this expirer will execute tasks from legacy expirer task queue,
# at least one object server should run with dequeue_from_legacy = true
# dequeue_from_legacy = false
#
# Note: Be careful not to enable ``dequeue_from_legacy`` on too many expirers
# as all legacy tasks are stored in a single hidden account and the same hidden
# containers. On a large cluster one may inadvertently make the
# acccount/container server for the hidden too busy.
#
# Note: the processes and process options can only be used in conjunction with
# notes using `dequeue_from_legacy = true`. These options are ignored on nodes
# with `dequeue_from_legacy = false`.
#
# processes is how many parts to divide the legacy work into, one part per
# process that will be doing the work
# processes set 0 means that a single legacy process will be doing all the work
# processes can also be specified on the command line and will override the
# config value
# processes = 0
#
# process is which of the parts a particular legacy process will work on
# process can also be specified on the command line and will override the config
# value
# process is "zero based", if you want to use 3 processes, you should run
# processes with process set to 0, 1, and 2
# process = 0
#
# internal_client_conf_path = /etc/swift/internal-client.conf
#
# You can override the default log routing for this app here (don't use set!):
# log_name = object-expirer
# log_facility = LOG_LOCAL0
# log_level = INFO
# log_address = /dev/log
#
# interval = 300.0
#
# report_interval = 300.0
#
# request_tries is the number of times the expirer's internal client will
# attempt any given request in the event of failure. The default is 3.
# request_tries = 3
#
# concurrency is the level of concurrency to use to do the work, this value
# must be set to at least 1
# concurrency = 1
#
# deletes can be ratelimited to prevent the expirer from overwhelming the cluster
# tasks_per_second = 50.0
#
# The expirer will re-attempt expiring if the source object is not available
# up to reclaim_age seconds before it gives up and deletes the entry in the
# queue.
# reclaim_age = 604800
#
# recon_cache_path = /var/cache/swift
#
# You can set scheduling priority of processes. Niceness values range from -20
# (most favorable to the process) to 19 (least favorable to the process).
# nice_priority =
#
# You can set I/O scheduling class and priority of processes. I/O niceness
# class values are realtime, best-effort and idle. I/O niceness
# priority is a number which goes from 0 to 7. The higher the value, the lower
# the I/O priority of the process. Work only with ionice_class.
# ionice_class =
# ionice_priority =
#
# Note: Put it at the beginning of the pipleline to profile all middleware. But
# it is safer to put this after healthcheck.
[filter:xprofile]
use = egg:swift#xprofile
# This option enable you to switch profilers which should inherit from python
# standard profiler. Currently the supported value can be 'cProfile',
# 'eventlet.green.profile' etc.
# profile_module = eventlet.green.profile
#
# This prefix will be used to combine process ID and timestamp to name the
# profile data file. Make sure the executing user has permission to write
# into this path (missing path segments will be created, if necessary).
# If you enable profiling in more than one type of daemon, you must override
# it with an unique value like: /var/log/swift/profile/object.profile
# log_filename_prefix = /tmp/log/swift/profile/default.profile
#
# the profile data will be dumped to local disk based on above naming rule
# in this interval.
# dump_interval = 5.0
#
# Be careful, this option will enable profiler to dump data into the file with
# time stamp which means there will be lots of files piled up in the directory.
# dump_timestamp = false
#
# This is the path of the URL to access the mini web UI.
# path = /__profile__
#
# Clear the data when the wsgi server shutdown.
# flush_at_shutdown = false
#
# unwind the iterator of applications
# unwind = false
[object-relinker]
# You can override the default log routing for this app here (don't use set!):
# log_name = object-relinker
# log_facility = LOG_LOCAL0
# log_level = INFO
# log_address = /dev/log
#
# Start up to this many sub-processes to process disks in parallel. Each disk
# will be handled by at most one child process. By default, one process is
# spawned per disk.
# workers = auto
#
# Target this many relinks/cleanups per second for each worker, to reduce the
# likelihood that the added I/O from a partition-power increase impacts
# client traffic. Use zero for unlimited.
# files_per_second = 0.0
#
# stats_interval = 300.0
# recon_cache_path = /var/cache/swift
OEFChỉnh sửa thông tin bind_ip cho Storage 1 - 10.237.7.82 và Storage 2 - 10.237.7.83.
Đối với Storage 1 - 10.237.7.82.
sed -i 's/bind_ip = .*/bind_ip = 10.237.7.82/' /etc/swift/account-server.conf
sed -i 's/bind_ip = .*/bind_ip = 10.237.7.82/' /etc/swift/container-server.conf
sed -i 's/bind_ip = .*/bind_ip = 10.237.7.82/' /etc/swift/object-server.confĐối với Storage 2 - 10.237.7.83.
sed -i 's/bind_ip = .*/bind_ip = 10.237.7.83/' /etc/swift/account-server.conf
sed -i 's/bind_ip = .*/bind_ip = 10.237.7.83/' /etc/swift/container-server.conf
sed -i 's/bind_ip = .*/bind_ip = 10.237.7.83/' /etc/swift/object-server.confCuối cùng, bạn đảm có quyền sở hữu thư mục mount point (/srv/node) và thư mục cache recon (/var/cache/swift).
chown -R swift:swift /srv/node
mkdir -p /var/cache/swift
chown -R root:swift /var/cache/swift
chmod -R 775 /var/cache/swift10. Hoàn tất cài đặt OpenStack Swift trên Controller Node.
Sao chép các file /etc/swift/object.ring.gz, /etc/swift/account.ring.gz, /etc/swift/container.ring.gz đã được tạo tự động trong quá trình tạo Account, Container và Object ở bước trên sang các Storage Node và các node chạy Swift Proxy.
scp /etc/swift/object.ring.gz /etc/swift/account.ring.gz /etc/swift/container.ring.gz root@storage1:/etc/swift
scp /etc/swift/object.ring.gz /etc/swift/account.ring.gz /etc/swift/container.ring.gz root@storage2:/etc/swiftBạn có thể file mẫu swift.conf-sample lưu về thư mục /etc/swift/để tự chỉnh sửa hoặc nếu không muốn tự chỉnh sửa thì bỏ qua bước này và làm tiếp bước tiếp theo để sử dụng file mẫu của mình.
curl -o /etc/swift/swift.conf \
https://opendev.org/openstack/swift/raw/branch/master/etc/swift.conf-sampleNội dung chỉnh sửa file /etc/swift/swift.conf bạn xem lại bài https://wiki.hoanghd.com/swift-phan-6-hoan-tat-cai-dat-openstack-swift-tren-controller-node/. Giờ mình chạy script dưới để tạo ra file /etc/swift/swift.conf
cat > /etc/swift/swift.conf << 'OEF'
[swift-hash]
# swift_hash_path_suffix and swift_hash_path_prefix are used as part of the
# hashing algorithm when determining data placement in the cluster.
# These values should remain secret and MUST NOT change
# once a cluster has been deployed.
# Use only printable chars (python -c "import string; print(string.printable)")
swift_hash_path_suffix = TsX5DvhCbE4wrBv63pnoAdrxqpWoVq4U
swift_hash_path_prefix = 8GGPsEgSXc8OqcPwzCgvUfSlLcvuGF82
# Storage policies are defined here and determine various characteristics
# about how objects are stored and treated. More documentation can be found at
# https://docs.openstack.org/swift/latest/overview_policies.html.
# Client requests specify a policy on a per container basis using the policy
# name. Internally the policy name is mapped to the policy index specified in
# the policy's section header in this config file. Policy names are
# case-insensitive and, to avoid confusion with indexes names, should not be
# numbers.
#
# The policy with index 0 is always used for legacy containers and can be given
# a name for use in metadata however the ring file name will always be
# 'object.ring.gz' for backwards compatibility. If no policies are defined a
# policy with index 0 will be automatically created for backwards compatibility
# and given the name Policy-0. A default policy is used when creating new
# containers when no policy is specified in the request. If no other policies
# are defined the policy with index 0 will be declared the default. If
# multiple policies are defined you must define a policy with index 0 and you
# must specify a default. It is recommended you always define a section for
# storage-policy:0.
#
# A 'policy_type' argument is also supported but is not mandatory. Default
# policy type 'replication' is used when 'policy_type' is unspecified.
#
# A 'diskfile_module' optional argument lets you specify an alternate backend
# object storage plug-in architecture. The default is
# "egg:swift#replication.fs", or "egg:swift#erasure_coding.fs", depending on
# the policy type.
#
# Aliases for the storage policy name may be defined, but are not required.
#
[storage-policy:0]
name = Policy-0
default = yes
#policy_type = replication
#diskfile_module = egg:swift#replication.fs
# aliases = yellow, orange
# The following section would declare a policy called 'silver', the number of
# replicas will be determined by how the ring is built. In this example the
# 'silver' policy could have a lower or higher # of replicas than the
# 'Policy-0' policy above. The ring filename will be 'object-1.ring.gz'. You
# may only specify one storage policy section as the default. If you changed
# this section to specify 'silver' as the default, when a client created a new
# container w/o a policy specified, it will get the 'silver' policy because
# this config has specified it as the default. However if a legacy container
# (one created with a pre-policy version of swift) is accessed, it is known
# implicitly to be assigned to the policy with index 0 as opposed to the
# current default. Note that even without specifying any aliases, a policy
# always has at least the default name stored in aliases because this field is
# used to contain all human readable names for a storage policy.
#
#[storage-policy:1]
#name = silver
#policy_type = replication
#diskfile_module = egg:swift#replication.fs
# The following declares a storage policy of type 'erasure_coding' which uses
# Erasure Coding for data reliability. Please refer to Swift documentation for
# details on how the 'erasure_coding' storage policy is implemented.
#
# Swift uses PyECLib, a Python Erasure coding API library, for encode/decode
# operations. Please refer to Swift documentation for details on how to
# install PyECLib.
#
# When defining an EC policy, 'policy_type' needs to be 'erasure_coding' and
# EC configuration parameters 'ec_type', 'ec_num_data_fragments' and
# 'ec_num_parity_fragments' must be specified. 'ec_type' is chosen from the
# list of EC backends supported by PyECLib. The ring configured for the
# storage policy must have its "replica" count configured to
# 'ec_num_data_fragments' + 'ec_num_parity_fragments' - this requirement is
# validated when services start. 'ec_object_segment_size' is the amount of
# data that will be buffered up before feeding a segment into the
# encoder/decoder. More information about these configuration options and
# supported 'ec_type' schemes is available in the Swift documentation. See
# https://docs.openstack.org/swift/latest/overview_erasure_code.html
# for more information on how to configure EC policies.
#
# The example 'deepfreeze10-4' policy defined below is a _sample_
# configuration with an alias of 'df10-4' as well as 10 'data' and 4 'parity'
# fragments. 'ec_type' defines the Erasure Coding scheme.
# 'liberasurecode_rs_vand' (Reed-Solomon Vandermonde) is used as an example
# below.
#
#[storage-policy:2]
#name = deepfreeze10-4
#aliases = df10-4
#policy_type = erasure_coding
#diskfile_module = egg:swift#erasure_coding.fs
#ec_type = liberasurecode_rs_vand
#ec_num_data_fragments = 10
#ec_num_parity_fragments = 4
#ec_object_segment_size = 1048576
#
# Duplicated EC fragments is proof-of-concept experimental support to enable
# Global Erasure Coding policies with multiple regions acting as independent
# failure domains. Do not change the default except in development/testing.
#ec_duplication_factor = 1
# The swift-constraints section sets the basic constraints on data
# saved in the swift cluster. These constraints are automatically
# published by the proxy server in responses to /info requests.
[swift-constraints]
# max_file_size is the largest "normal" object that can be saved in
# the cluster. This is also the limit on the size of each segment of
# a "large" object when using the large object manifest support.
# This value is set in bytes. Setting it to lower than 1MiB will cause
# some tests to fail. It is STRONGLY recommended to leave this value at
# the default (5 * 2**30 + 2).
#max_file_size = 5368709122
# max_meta_name_length is the max number of bytes in the utf8 encoding
# of the name portion of a metadata header.
#max_meta_name_length = 128
# max_meta_value_length is the max number of bytes in the utf8 encoding
# of a metadata value
#max_meta_value_length = 256
# max_meta_count is the max number of metadata keys that can be stored
# on a single account, container, or object
#max_meta_count = 90
# max_meta_overall_size is the max number of bytes in the utf8 encoding
# of the metadata (keys + values)
#max_meta_overall_size = 4096
# max_header_size is the max number of bytes in the utf8 encoding of each
# header. Using 8192 as default because eventlet use 8192 as max size of
# header line. This value may need to be increased when using identity
# v3 API tokens including more than 7 catalog entries.
# See also include_service_catalog in proxy-server.conf-sample
# (documented at https://docs.openstack.org/swift/latest/overview_auth.html)
#max_header_size = 8192
# By default the maximum number of allowed headers depends on the number of max
# allowed metadata settings plus a default value of 36 for swift internally
# generated headers and regular http headers. If for some reason this is not
# enough (custom middleware for example) it can be increased with the
# extra_header_count constraint.
#extra_header_count = 0
# max_object_name_length is the max number of bytes in the utf8 encoding
# of an object name
#max_object_name_length = 1024
# container_listing_limit is the default (and max) number of items
# returned for a container listing request
#container_listing_limit = 10000
# account_listing_limit is the default (and max) number of items returned
# for an account listing request
#account_listing_limit = 10000
# max_account_name_length is the max number of bytes in the utf8 encoding
# of an account name
#max_account_name_length = 256
# max_container_name_length is the max number of bytes in the utf8 encoding
# of a container name
#max_container_name_length = 256
# By default all REST API calls should use "v1" or "v1.0" as the version string,
# for example "/v1/account". This can be manually overridden to make this
# backward-compatible, in case a different version string has been used before.
# Use a comma-separated list in case of multiple allowed versions, for example
# valid_api_versions = v0,v1,v2
# This is only enforced for account, container and object requests. The allowed
# api versions are by default excluded from /info.
# valid_api_versions = v1,v1.0
# The prefix used for hidden auto-created accounts, for example accounts in
# which shard containers are created. It defaults to '.'; don't change it.
# auto_create_account_prefix = .
OEFSao chép file /etc/swift/swift.conf sang các Storage Node và Swift Proxy.
scp /etc/swift/swift.conf root@storage1:/etc/swift
scp /etc/swift/swift.conf root@storage2:/etc/swiftTrên tất cả các node, đảm bảo quyền sở hữu phù hợp của thư mục cấu hình: chown -R root:swift /etc/swift.
chown -R root:swift /etc/swift
ssh root@storage1 'chown -R root:swift /etc/swift'
ssh root@storage2 'chown -R root:swift /etc/swift'Trên node controller và bất kỳ node nào khác đang chạy dịch vụ proxy, khởi động lại dịch vụ proxy Object Storage cùng với các phụ thuộc của nó.
sudo systemctl enable swift-proxy.service memcached.service
sudo systemctl restart swift-proxy.service memcached.serviceKiểm tra lại trạng thái swift-proxy và memcached.
sudo systemctl status swift-proxy.service | grep active
sudo systemctl status memcached.service | grep active11. Trên các storage node, khởi động các dịch vụ Object Storage.
Trên mỗi storage node chạy các lệnh sau để kích hoạt và bắt đầu dịch vụ.
sudo systemctl enable swift-account.service swift-account-auditor.service \
swift-account-reaper.service swift-account-replicator.service
sudo systemctl restart swift-account.service swift-account-auditor.service \
swift-account-reaper.service swift-account-replicator.service
sudo systemctl enable swift-container.service \
swift-container-auditor.service swift-container-replicator.service \
swift-container-updater.service
sudo systemctl restart swift-container.service \
swift-container-auditor.service swift-container-replicator.service \
swift-container-updater.service
sudo systemctl enable swift-object.service swift-object-auditor.service \
swift-object-replicator.service swift-object-updater.service
sudo systemctl restart swift-object.service swift-object-auditor.service \
swift-object-replicator.service swift-object-updater.serviceXác minh lại trạng thái nhé.
sudo systemctl status swift-account.service swift-account-auditor.service \
swift-account-reaper.service swift-account-replicator.service
sudo systemctl status swift-container.service \
swift-container-auditor.service swift-container-replicator.service \
swift-container-updater.service
sudo systemctl status swift-object.service swift-object-auditor.service \
swift-object-replicator.service swift-object-updater.serviceTrên các storage node, khởi động các dịch vụ Object Storage.
swift-init all restart12. Kiểm tra hoạt động của OpenStack Swift trên Controller Node.
Sử dụng các thông tin xác thực admin.
. admin-openrcĐể xem dung lượng và trạng thái của Swift, bạn có thể sử dụng lệnh swift stat. Lệnh này sẽ hiển thị thông tin về số lượng containers, số lượng objects, và tổng dung lượng sử dụng.
swift statKết quả sẽ giống như sau:
shell> swift stat
Account: AUTH_ef46fa05202a47fbb80e6fd67dfbd887
Containers: 0
Objects: 0
Bytes: 0
Content-Type: text/plain; charset=utf-8
X-Timestamp: 1710440455.77477
X-Put-Timestamp: 1710440455.77477
Vary: Accept
X-Trans-Id: tx7783966440ce4f3ab26e2-0065f34007
X-Openstack-Request-Id: tx7783966440ce4f3ab26e2-0065f34007Hiện tại tài khoản admin có không Containers và Objects nào cả.
Tạo container container1.
shell> openstack container create container1
+---------------------------------------+------------+------------------------------------+
| account | container | x-trans-id |
+---------------------------------------+------------+------------------------------------+
| AUTH_ef46fa05202a47fbb80e6fd67dfbd887 | container1 | txcf4481799ede47e5a7651-0065f3403e |
+---------------------------------------+------------+------------------------------------+Tạo thêm container container2.
shell> openstack container create container2
+---------------------------------------+------------+------------------------------------+
| account | container | x-trans-id |
+---------------------------------------+------------+------------------------------------+
| AUTH_ef46fa05202a47fbb80e6fd67dfbd887 | container2 | tx10b4d5c330a443e88be2a-0065f34061 |
+---------------------------------------+------------+------------------------------------+Chúng ta có 2 container như dưới.
shell> openstack container list
+------------+
| Name |
+------------+
| container1 |
| container2 |
+------------+Hiện tại trong thư mục /home mình có một số file như thông tin ở dưới.
shell> cd /home/
shell> ls -al
total 12448
drwxr-xr-x 3 root root 4096 Mar 14 18:23 .
drwxr-xr-x 20 root root 4096 Mar 13 06:58 ..
-rw-r--r-- 1 root root 265 Mar 14 18:11 admin-openrc
-rw-r--r-- 1 root root 12716032 Dec 7 2021 cirros-0.4.0-x86_64-disk.img
-rw-r--r-- 1 root root 271 Mar 14 18:11 demo-openrc
-rw-r--r-- 1 root root 143 Mar 14 18:07 env
-rw-r--r-- 1 root root 235 Mar 14 18:11 environmentMình upload file cirros-0.4.0-x86_64-disk.img vào container container1
shell> openstack object create container1 cirros-0.4.0-x86_64-disk.img
+------------------------------+------------+----------------------------------+
| object | container | etag |
+------------------------------+------------+----------------------------------+
| cirros-0.4.0-x86_64-disk.img | container1 | 443b7623e27ecf03dc9e01ee93f67afe |
+------------------------------+------------+----------------------------------+Mình tiếp tục upload file admin-openrc và demo-openrc vào container containe2.
shell> openstack object create container2 admin-openrc
+--------------+------------+----------------------------------+
| object | container | etag |
+--------------+------------+----------------------------------+
| admin-openrc | container2 | a1e633950801dcada7830427ef551ac9 |
+--------------+------------+----------------------------------+
shell> openstack object create container2 demo-openrc
+-------------+------------+----------------------------------+
| object | container | etag |
+-------------+------------+----------------------------------+
| demo-openrc | container2 | ac9e352960e4a5d6542ed98235ac40fd |
+-------------+------------+----------------------------------+Kiểm tra file đã upload vào container1.
shell> openstack object list container1
+------------------------------+
| Name |
+------------------------------+
| cirros-0.4.0-x86_64-disk.img |
+------------------------------+Và container2.
shell> openstack object list container2
+--------------+
| Name |
+--------------+
| admin-openrc |
| demo-openrc |
+--------------+Thử tải file cirros-0.4.0-x86_64-disk.img từ container1 về thư mục /tmp.
cd /tmp
openstack object save container1 cirros-0.4.0-x86_64-disk.imgChúng ta có kết quả.
shell> ls -al | grep cirros-0.4.0-x86_64-disk.img
-rw-r--r-- 1 root root 12716032 Mar 14 18:29 cirros-0.4.0-x86_64-disk.imgChạy lệnh swift stat kiểm tra lại trạng thái dịch vụ và chúng ta có kết quả như dưới. Từ kết quả dưới thì hiện tại tài khoản admin đang có 2 container và 3 object sử dụng tổng dung lượng là 12716568 Bytes.
shell> swift stat
Account: AUTH_ef46fa05202a47fbb80e6fd67dfbd887
Containers: 2
Objects: 3
Bytes: 12716568
Containers in policy "policy-0": 2
Objects in policy "policy-0": 3
Bytes in policy "policy-0": 12716568
Content-Type: text/plain; charset=utf-8
X-Timestamp: 1710440509.64465
Accept-Ranges: bytes
Vary: Accept
X-Trans-Id: tx622dc1c0465b4a46bb334-0065f34288
X-Openstack-Request-Id: tx622dc1c0465b4a46bb334-0065f34288Để xem trạng thái của Swift, bạn có thể sử dụng lệnh swift-recon. Lệnh này cung cấp thông tin về trạng thái của các node trong cluster Swift (lưu ý rằng bạn cần quyền admin để chạy lệnh swift-recon).
shell> swift-recon --all
===============================================================================
--> Starting reconnaissance on 2 hosts (object)
===============================================================================
[2024-03-14 18:34:43] Checking async pendings
[async_pending] - No hosts returned valid data.
===============================================================================
[2024-03-14 18:34:43] Checking auditor stats
[ALL_audit_time_last_path] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 2
[ALL_bytes_processed_last_path] low: 265, high: 12716032, avg: 6358148.5, total: 12716297, Failed: 0.0%, no_result: 0, reported: 2
[ALL_passes_last_path] low: 1, high: 1, avg: 1.0, total: 2, Failed: 0.0%, no_result: 0, reported: 2
[ALL_errors_last_path] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 2
[ALL_quarantined_last_path] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 2
[ZBF_audit_time_last_path] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 2
[ZBF_bytes_processed_last_path] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 2
[ZBF_errors_last_path] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 2
[ZBF_quarantined_last_path] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 2
===============================================================================
[2024-03-14 18:34:43] Checking updater times
[updater_last_sweep] low: 0, high: 0, avg: 0.2, total: 0, Failed: 0.0%, no_result: 0, reported: 2
===============================================================================
[2024-03-14 18:34:43] Checking on expirers
[object_expiration_pass] - No hosts returned valid data.
[expired_last_pass] - No hosts returned valid data.
===============================================================================
[2024-03-14 18:34:43] Checking on reconstructors
-> http://10.237.7.82:6200/recon/reconstruction/object: HTTP Error 404: Not Found
-> http://10.237.7.83:6200/recon/reconstruction/object: HTTP Error 404: Not Found
[object_reconstruction_time] - No hosts returned valid data.
===============================================================================
[2024-03-14 18:34:43] Checking on replication
[replication_time] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 2
[replication_failure] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 2
[replication_success] low: 8, high: 10, avg: 9.0, total: 18, Failed: 0.0%, no_result: 0, reported: 2
[replication_attempted] low: 4, high: 5, avg: 4.5, total: 9, Failed: 0.0%, no_result: 0, reported: 2
Oldest completion was 2024-03-14 18:34:42 (1 seconds ago) by 10.237.7.82:6200.
Most recent completion was 2024-03-14 18:34:43 (0 seconds ago) by 10.237.7.83:6200.
===============================================================================
[2024-03-14 18:34:43] Getting unmounted drives from 2 hosts...
===============================================================================
[2024-03-14 18:34:43] Checking load averages
[1m_load_avg] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 2
[5m_load_avg] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 2
[15m_load_avg] low: 0, high: 0, avg: 0.1, total: 0, Failed: 0.0%, no_result: 0, reported: 2
===============================================================================
[2024-03-14 18:34:43] Checking disk usage now
Distribution Graph:
0% 6 *********************************************************************
Disk usage: space used: 1589194752 of 193179156480
Disk usage: space free: 191589961728 of 193179156480
Disk usage: lowest: 0.8%, highest: 0.84%, avg: 0.8226533239700374%
===============================================================================
[2024-03-14 18:34:43] Checking ring md5sums
2/2 hosts matched, 0 error[s] while checking hosts.
===============================================================================
[2024-03-14 18:34:43] Checking swift.conf md5sum
2/2 hosts matched, 0 error[s] while checking hosts.
===============================================================================
[2024-03-14 18:34:43] Checking quarantine
[quarantined_objects] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 2
[quarantined_containers] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 2
[quarantined_accounts] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 2
===============================================================================
[2024-03-14 18:34:43] Checking socket usage
[tcp_in_use] low: 30, high: 34, avg: 32.0, total: 64, Failed: 0.0%, no_result: 0, reported: 2
[tcp_mem_allocated_bytes] low: 45056, high: 45056, avg: 45056.0, total: 90112, Failed: 0.0%, no_result: 0, reported: 2
[tcp6_in_use] low: 1, high: 1, avg: 1.0, total: 2, Failed: 0.0%, no_result: 0, reported: 2
[time_wait] low: 40, high: 42, avg: 41.0, total: 82, Failed: 0.0%, no_result: 0, reported: 2
[orphan] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 2
===============================================================================
[2024-03-14 18:34:43] Validating server type 'object' on 2 hosts...
2/2 hosts ok, 0 error[s] while checking hosts.
===============================================================================
[2024-03-14 18:34:43] Checking drive-audit errors
[drive_audit_errors] - No hosts returned valid data.
===============================================================================
[2024-03-14 18:34:43] Checking time-sync
!! http://10.237.7.82:6200/recon/time current time is 2024-03-14 18:34:43, but remote is 2024-03-14 18:34:43, differs by 0.6795 sec
!! http://10.237.7.83:6200/recon/time current time is 2024-03-14 18:34:43, but remote is 2024-03-14 18:34:43, differs by 0.2849 sec
0/2 hosts matched, 0 error[s] while checking hosts.
===============================================================================
[2024-03-14 18:34:43] Checking versions
Versions matched (2.25.2), 0 error[s] while checking hosts.
===============================================================================Từ kết quả của lệnh swift-recon --all, bạn có thể xem thông tin về dung lượng lưu trữ của Swift trong phần “Checking disk usage now”:
Disk usage: space used: 1589194752 of 193179156480
Disk usage: space free: 191589961728 of 193179156480- Tổng dung lượng lưu trữ của Swift là 193179156480 bytes.
- Dung lượng đã sử dụng là 1589194752 bytes.
- Dung lượng còn lại là 191589961728 bytes.
Lưu ý: Các số liệu trên được thể hiện dưới dạng bytes. Bạn có thể chuyển đổi chúng thành GB hoặc TB để dễ đọc hơn.


{kind=link}