
1. Amazon Kinesis.
Kinesis là một dịch vụ của AWS được sử dụng để thu thập, xử lý và phân tích dữ liệu theo thời gian thực. Dịch vụ này cho phép chúng ta nhận dữ liệu đến từ nhiều nguồn như logs của ứng dụng, số liệu thống kê, dữ liệu IoT hay các luồng dữ liệu trên website và chuyển chúng đến các hệ thống lưu trữ, xử lý dữ liệu của AWS để phân tích và giải quyết các vấn đề liên quan đến dữ liệu theo thời gian thực.

Kinesis bao gồm các dịch vụ như Kinesis Data Streams, Kinesis Data Firehose, Kinesis Data Analytics và Kinesis Video Streams.
- Kinesis Data Streams là dịch vụ cho phép chúng ta lấy và lưu trữ các luồng dữ liệu, sau đó xử lý chúng bằng các ứng dụng xử lý dữ liệu thời gian thực.
- Kinesis Data Firehose cho phép chúng ta chuyển dữ liệu từ các nguồn khác nhau và lưu trữ chúng vào các hệ thống lưu trữ của AWS, chẳng hạn như Amazon S3, Amazon Redshift hoặc Amazon Elasticsearch.
- Kinesis Data Analytics là dịch vụ cho phép chúng ta phân tích các luồng dữ liệu bằng cách sử dụng truy vấn SQL hoặc Apache Flink.
- Kinesis Video Streams là dịch vụ giúp chúng ta thu thập, xử lý và lưu trữ luồng dữ liệu video trực tuyến, được sử dụng chủ yếu cho các ứng dụng như giám sát an ninh hoặc video trực tuyến.
2. Kinesis Data Streams.
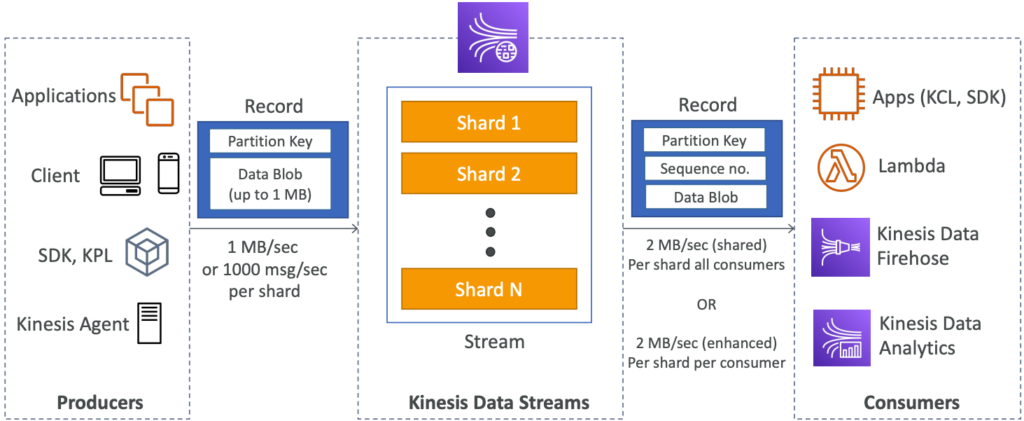
Kinesis Data Streams là một dịch vụ của AWS cho phép thu thập, xử lý và lưu trữ các luồng dữ liệu (streaming data) một cách hiệu quả và có khả năng mở rộng. Kinesis Data Streams cung cấp khả năng lưu trữ dữ liệu từ 1 đến 365 ngày và cho phép tái xử lý (replay) dữ liệu, cho phép các ứng dụng xử lý lại các sự kiện đã xảy ra trong quá khứ. Khi một dữ liệu được gửi vào Kinesis, nó sẽ không bao giờ bị xóa (immutability).
Kinesis Data Streams sử dụng các partition để phân tách và phân phối dữ liệu tới các shard. Dữ liệu chia sẻ cùng một partition sẽ được gửi tới cùng một shard, đảm bảo tính toàn vẹn và thứ tự của dữ liệu. Kinesis Data Streams cho phép các nhà sản xuất (producers) sử dụng AWS SDK, Kinesis Producer Library (KPL) hoặc Kinesis Agent để gửi dữ liệu. Trong khi đó, các nhà tiêu thụ (consumers) có thể viết mã của riêng họ sử dụng Kinesis Client Library (KCL) hoặc AWS SDK, hoặc sử dụng các dịch vụ quản lý được như Kinesis Data Firehose, Kinesis Data Analytics hay AWS Lambda.
3. Kinesis Data Streams – Capacity Modes.
Kinesis Data Streams là một dịch vụ của AWS được thiết kế để thu thập, xử lý và phân tích dữ liệu theo thời gian thực. Kinesis Data Streams có hai chế độ khả năng, bao gồm:
Provisioned mode:
- Trong chế độ này, người dùng có thể tự chọn số lượng shard cần thiết để xử lý dữ liệu, và có thể điều chỉnh số lượng shard này bằng cách thủ công hoặc sử dụng API.
- Mỗi shard trong chế độ này nhận được tối đa 1MB/s vào (hoặc 1000 bản ghi mỗi giây) và 2MB/s ra (người tiêu thụ cổ điển hoặc fan-out tăng cường).
- Người dùng sẽ thanh toán cho mỗi shard cấp phát mỗi giờ sử dụng dịch vụ.
On-demand mode:
- Trong chế độ này, người dùng không cần phải cấp phát hoặc quản lý khả năng.
- Mặc định, Kinesis Data Streams cung cấp khả năng là 4 MB/s vào (hoặc 4000 bản ghi mỗi giây).
- Dịch vụ sẽ tự động mở rộng khả năng theo nhu cầu của người dùng và tính toán dựa trên lưu lượng đỉnh trong 30 ngày qua.
- Người dùng sẽ thanh toán cho mỗi luồng dữ liệu mỗi giờ và dữ liệu vào/ra mỗi GB sử dụng dịch vụ.
Khi sử dụng Kinesis Data Streams, người dùng có thể sử dụng các nhà sản xuất (producers) để ghi dữ liệu vào stream, bao gồm AWS SDK, Kinesis Producer Library (KPL) và Kinesis Agent. Người dùng có thể sử dụng các nhận (consumers) để đọc dữ liệu từ stream, bao gồm Kinesis Client Library (KCL) và các dịch vụ quản lý được cung cấp bởi AWS như AWS Lambda, Kinesis Data Firehose và Kinesis Data Analytics.
4. Kinesis Data Streams Security.
Dịch vụ Kinesis cung cấp các tính năng bảo mật để đảm bảo an toàn và bảo mật cho dữ liệu của bạn. Các tính năng này bao gồm:
- Kiểm soát truy cập/ủy quyền bằng cách sử dụng các chính sách IAM: Kinesis sử dụng IAM (Identity and Access Management) để quản lý quyền truy cập vào tài nguyên của dịch vụ. Bạn có thể sử dụng IAM để thiết lập các chính sách truy cập để kiểm soát quyền truy cập của người dùng đến dịch vụ Kinesis.
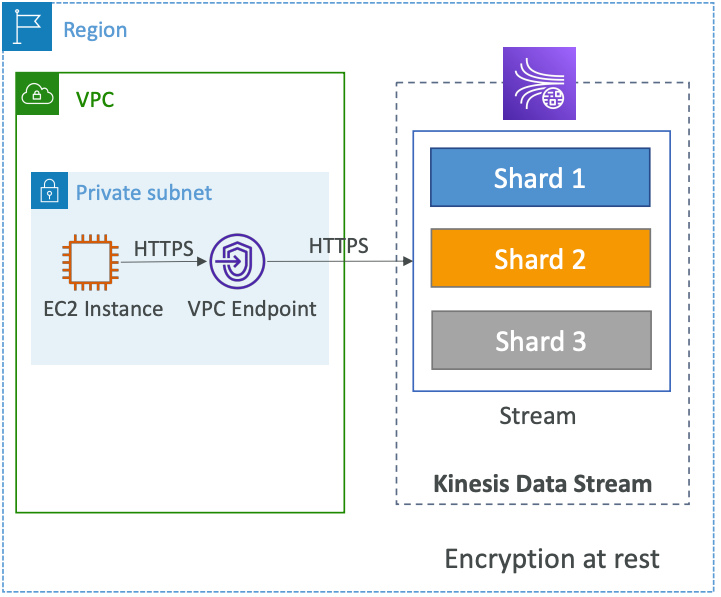
- Mã hóa trong quá trình truyền dữ liệu sử dụng các đầu cuối HTTPS: Kinesis hỗ trợ giao thức HTTPS để mã hóa dữ liệu trong quá trình truyền. Bằng cách sử dụng các đầu cuối HTTPS, dữ liệu sẽ được mã hóa và giải mã tự động khi đi qua mạng.
- Mã hóa dữ liệu nằm yên tại Kinesis sử dụng KMS: Kinesis cung cấp tính năng mã hóa dữ liệu nằm yên tại sử dụng KMS (Key Management Service) của AWS. Khi bật tính năng này, Kinesis sẽ mã hóa dữ liệu trước khi lưu trữ vào đĩa và giải mã khi truy cập.
- Người dùng có thể triển khai mã hóa/giải mã dữ liệu phía khách hàng: Nếu bạn muốn triển khai mã hóa và giải mã dữ liệu của riêng mình, bạn có thể làm điều này bằng cách sử dụng các thư viện mã hóa/giải mã của riêng mình.
- Kinesis cung cấp các VPC Endpoint để truy cập trong VPC: Kinesis hỗ trợ tính năng VPC Endpoint để truy cập dịch vụ trong một mạng riêng ảo (VPC). Bằng cách sử dụng VPC Endpoint, bạn có thể truy cập Kinesis từ trong VPC mà không cần đi qua Internet.
- Theo dõi các cuộc gọi API sử dụng CloudTrail để kiểm soát việc sử dụng dịch vụ Kinesis: Kinesis tích hợp với CloudTrail để ghi lại các sự kiện API cho việc theo dõi, kiểm soát và phân tích. Các sự kiện này có thể được sử dụng để tạo các báo cáo về việc sử dụng dịch vụ Kinesis.
5. Kinesis Data Streams Hands On.
Đầu tiên hãy vào Kinesis.
Lựa chọn Kinesis Data Streams.

Kéo xuống dưới bạn sẽ thấy 2 thông tin Shards (số tiền phải trả mỗi giờ) và PUT payload units (giá cước cho 1 triệu PUT).
Trong đó, PUT payload units là đơn vị để đo lường số lượng dữ liệu được gửi đến Kinesis, và giá cước $0.014 được tính cho mỗi 1 triệu đơn vị này. Vì vậy, nếu bạn gửi 1 triệu PUT payload units vào Kinesis, giá cước sẽ là $0.014. Tuy nhiên, nếu bạn gửi nhiều hơn, ví dụ như 2 triệu PUT payload units, thì giá cước sẽ là $0.028.
Lưu ý rằng giá cước có thể thay đổi tùy thuộc vào vùng địa lý và loại dịch vụ Kinesis mà bạn sử dụng. Bạn nên xem xét cẩn thận các chi phí khi sử dụng Kinesis để đảm bảo rằng chúng phù hợp với ngân sách của bạn.
Hãy kéo lên lại và bấm vào Create data stream để tiếp tục.

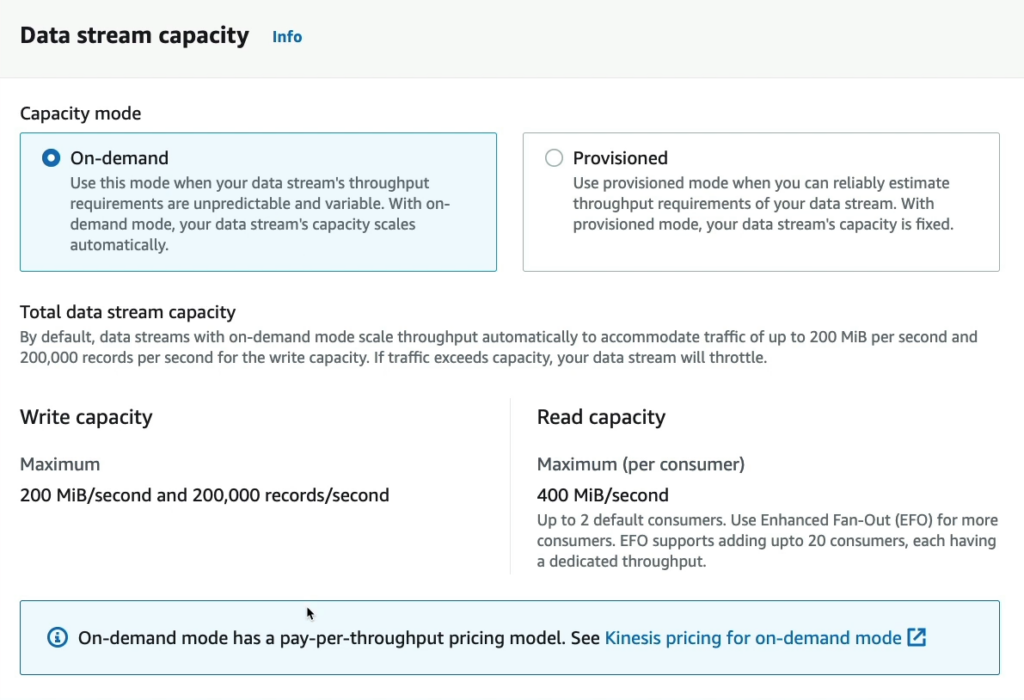
Nếu chọn mode On-demand bạn sẽ thấy các thông tin về khả năng xử lý dữ liệu của Amazon Kinesis, một dịch vụ của Amazon Web Services (AWS) cho phép lưu trữ, xử lý và phân tích dữ liệu thời gian thực.
Đối với Write capacity, Kinesis hỗ trợ việc ghi dữ liệu với tốc độ tối đa là 200 Mi/second và 200,000 records/second. Điều này có nghĩa là bạn có thể ghi dữ liệu vào Kinesis với tốc độ tối đa là 200 Mi/second hoặc 200,000 bản ghi mỗi giây. Tuy nhiên, đây là tốc độ tối đa và phụ thuộc vào nhiều yếu tố như dung lượng và tốc độ mạng của bạn.
Đối với Read capacity, Kinesis hỗ trợ đọc dữ liệu với tốc độ tối đa là 400 MiB/second cho mỗi consumer và mặc định hỗ trợ tối đa 2 consumers. Tuy nhiên, nếu bạn muốn sử dụng nhiều hơn 2 consumers, bạn cần sử dụng tính năng Enhanced Fan-Out (EFO) của Kinesis. EFO cho phép thêm tối đa 20 consumers và mỗi consumer có một thời gian xử lý riêng biệt.
Nếu chọn mode Provisioned bạn sẽ thấy thông tin về khả năng xử lý dữ liệu của Amazon Kinesis Data Streams, một dịch vụ của Amazon Web Services (AWS) cho phép lưu trữ và xử lý dữ liệu thời gian thực.
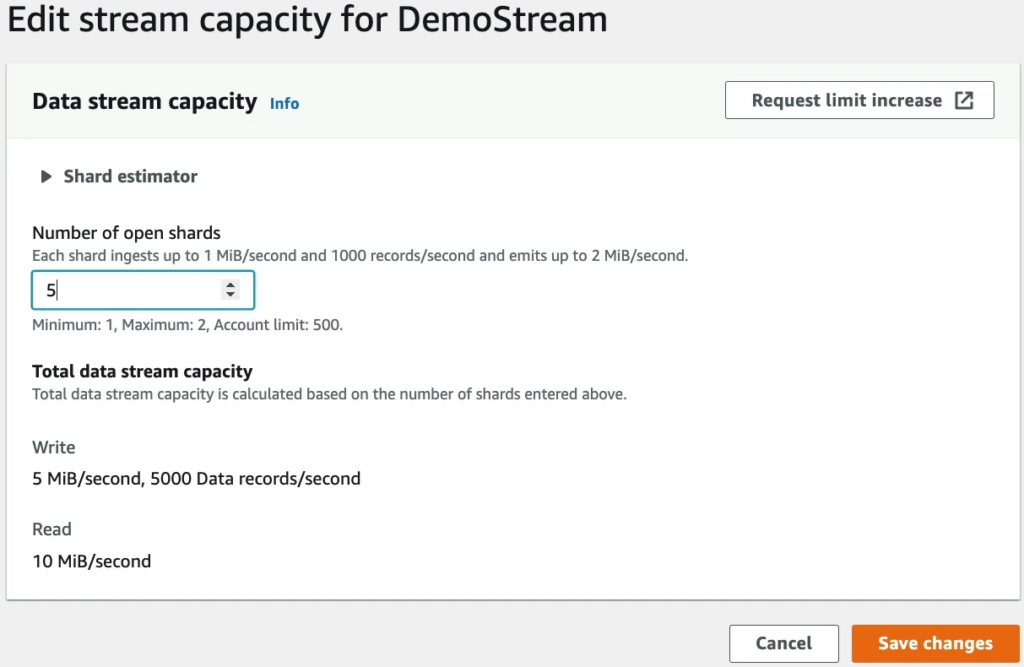
Đối với Total data stream capacity, khả năng xử lý dữ liệu của Kinesis Data Streams được xác định bởi số lượng shards được cung cấp. Mỗi shard có khả năng nhận dữ liệu với tốc độ tối đa 1 MiB/second và 1,000 bản ghi mỗi giây và phát ra dữ liệu với tốc độ tối đa 2 MiB/second. Nếu số lượng dữ liệu ghi và đọc vượt quá khả năng xử lý của shard, ứng dụng sẽ bị giới hạn tốc độ xử lý (throttles).
Ví dụ, nếu bạn cung cấp 10 shards cho một stream dữ liệu, tổng khả năng xử lý của stream đó là 10 MiB/second và 10,000 bản ghi mỗi giây. Tuy nhiên, để đạt được tốc độ xử lý này, bạn cần đảm bảo rằng dữ liệu của bạn được phân bổ đồng đều trên các shard và kết nối mạng của bạn đủ mạnh để hỗ trợ việc truyền dữ liệu.
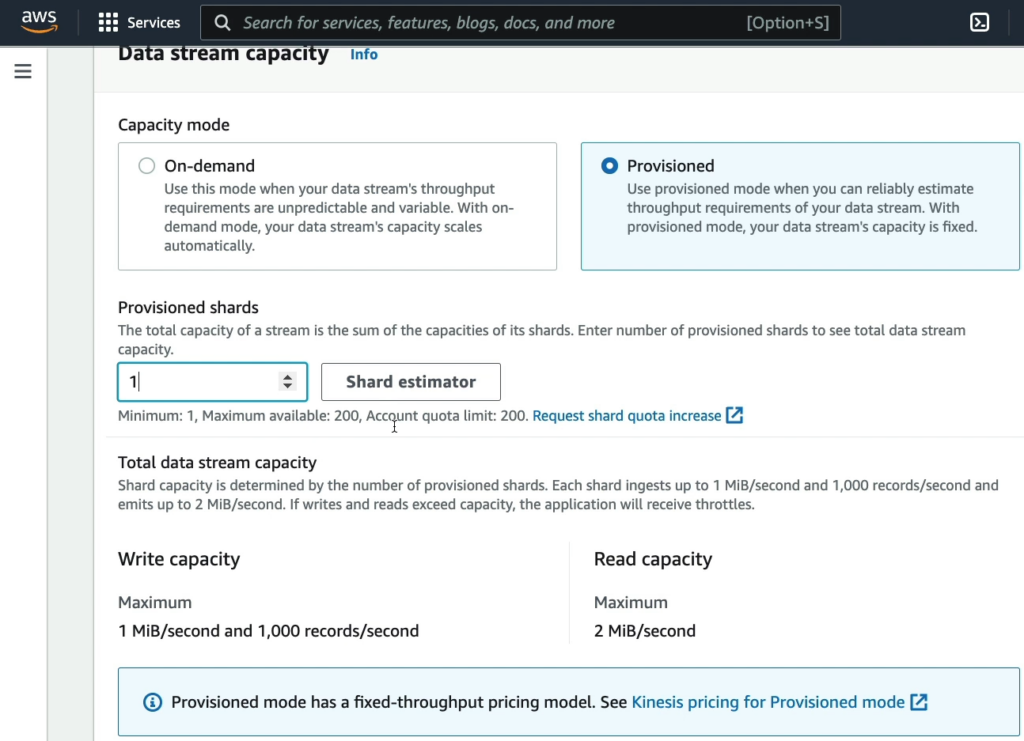
Phần “Data stream specifications” đề cập đến thông số kỹ thuật của Amazon Kinesis Data Streams, một dịch vụ của Amazon Web Services (AWS) cho phép lưu trữ và xử lý dữ liệu thời gian thực.
Trong phần “Maximum number of records written per second” và “Average record size (in KiB)”, bạn có thể chọn các giá trị để định nghĩa mức độ xử lý dữ liệu của stream.
Nếu bạn chọn “Maximum number of records written per second” là 1024 và “Average record size (in KiB)” là 1024, điều đó có nghĩa là mỗi shard của stream có khả năng xử lý tối đa 1 MiB/second và 1024 bản ghi mỗi giây. Đồng thời, giả sử mỗi bản ghi có kích thước trung bình là 1 KiB, tức là 1024 bytes, thì mỗi shard có thể xử lý được 1 MiB/second ÷ 1 KiB/bản ghi = 1024 bản ghi mỗi giây.
Tuy nhiên, đây chỉ là giới hạn tối đa và khả năng xử lý dữ liệu thực tế phụ thuộc vào nhiều yếu tố như tốc độ mạng và độ phân tán dữ liệu trên các shard. Nếu tổng khối lượng dữ liệu ghi vào stream vượt quá giới hạn này, bạn cần cung cấp thêm shard hoặc tối ưu hóa cách phân tán dữ liệu để đạt được khả năng xử lý tối đa.
Tóm lại, các thông số trong phần “Data stream specifications” cho phép bạn cấu hình các thông số để đạt được khả năng xử lý dữ liệu tối đa của stream, nhưng khả năng xử lý thực tế phụ thuộc vào nhiều yếu tố khác nhau.
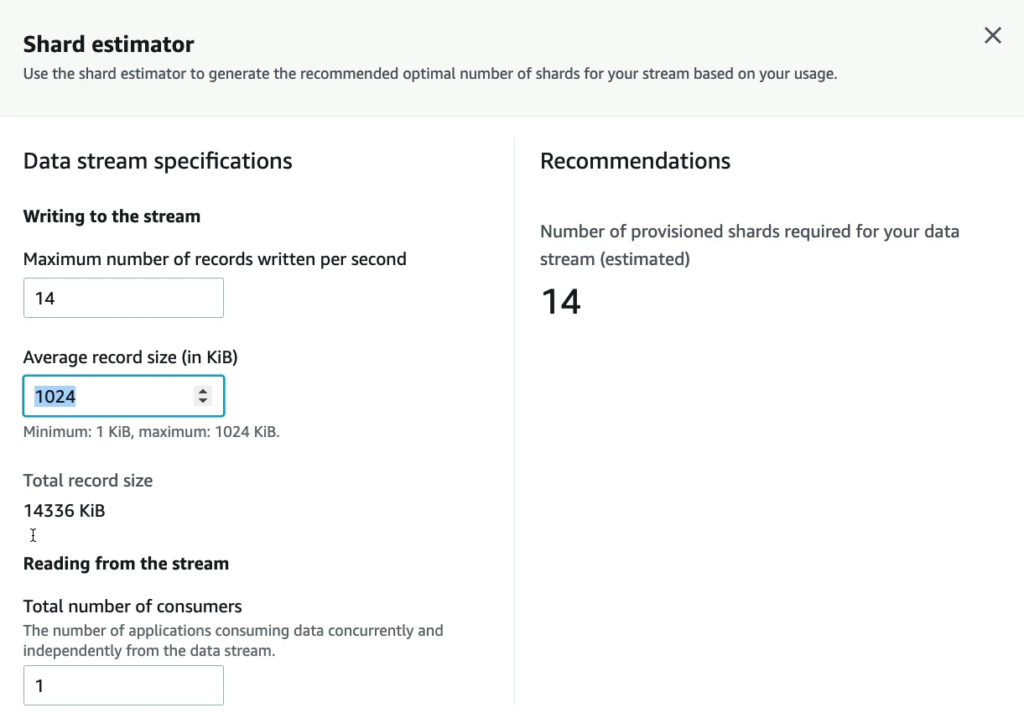
Và dưới đây là bảng cho phép bạn review lại toàn bộ thiết lập.
Khi bạn bấm Create data stream, tiến trình tạo stream bắt đầu.
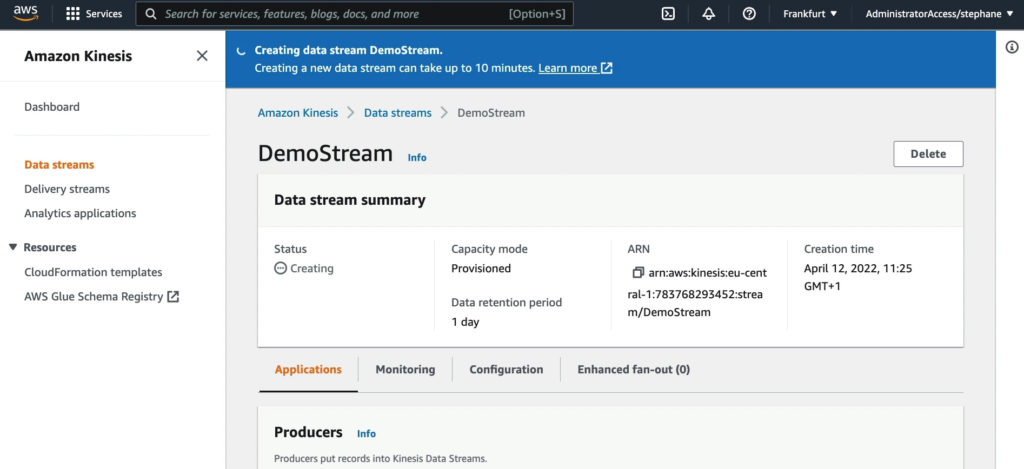
Tại phần Producers sẽ có 3 lựa chọn như đã nói ở phần lý thuyết (Amazon Kinesis Agent, AWS SDK và Amazon Kinesis Producer Library (KPL)) và phần Consumers (Amazon Kinesis Data Analytics, Amazon Kinesis Data Firehose và Amazon Kinesis Client Library (KCL)).
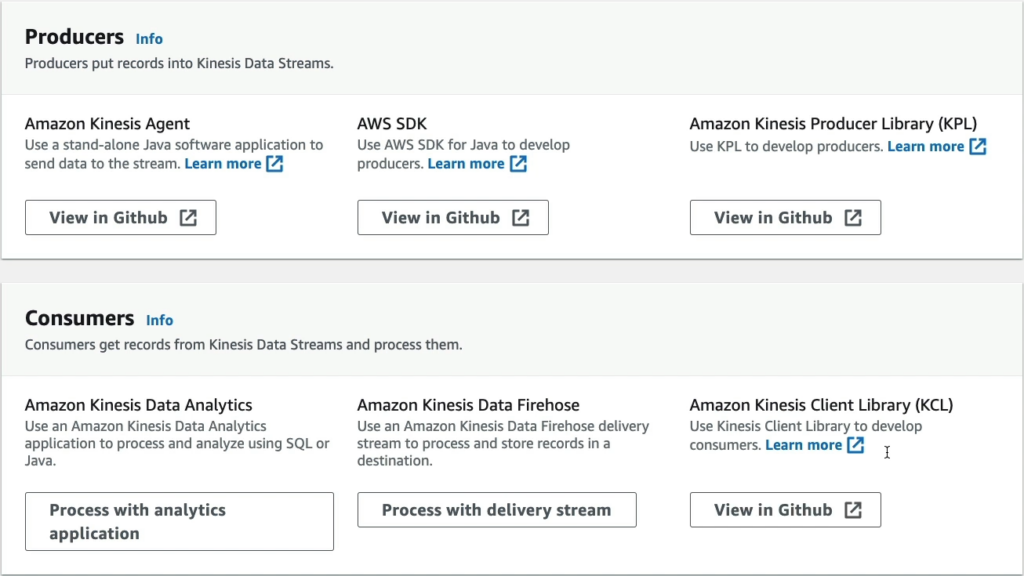
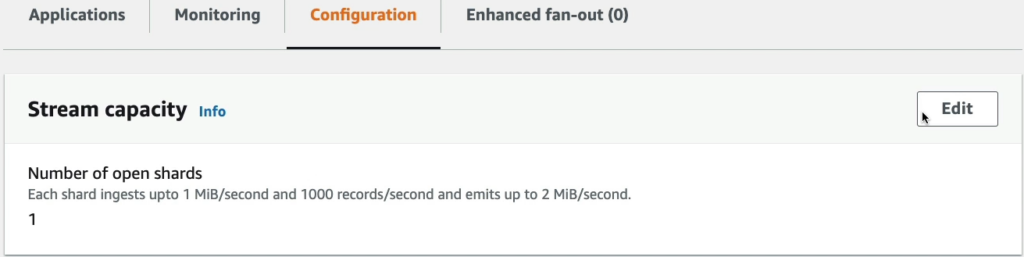
Qua thẻ Configuration nếu bạn muốn mở rộng khả năng xử lý của stream, hãy vào Edit.
Và lựa chọn số luồng tại Number of open shards.
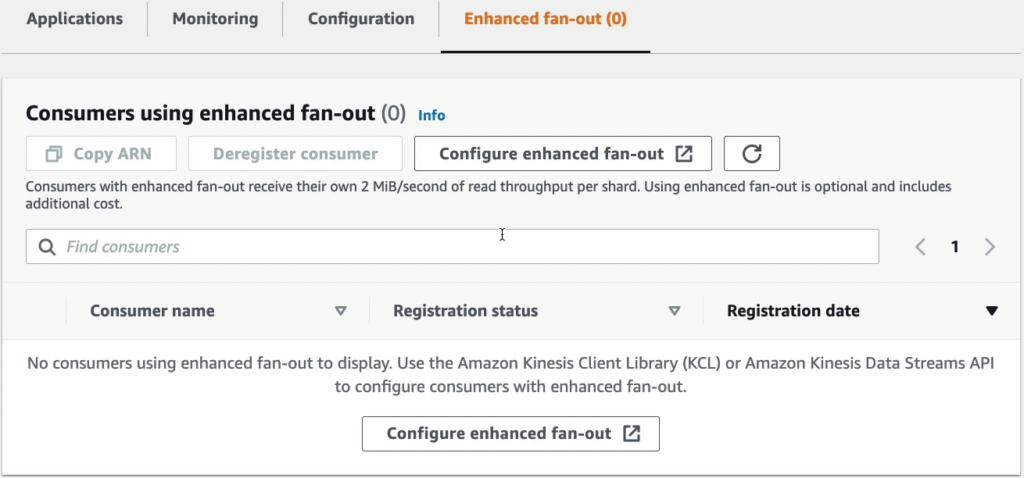
“Enhanced Fan-Out” (EFO) là một tính năng của Amazon Kinesis Data Streams, cho phép các consumer có thể đăng ký để đọc dữ liệu từ các shard của stream một cách nhanh chóng và hiệu quả hơn.
Khi sử dụng EFO, Kinesis sẽ sao chép dữ liệu vào một hoặc nhiều bộ đệm trong các consumer, giảm thiểu độ trễ và đảm bảo rằng mỗi consumer có thể đọc dữ liệu một cách hiệu quả mà không ảnh hưởng đến các consumer khác. Các consumer cũng có thể đăng ký để đọc từ các shard theo thời gian thực, ngay khi có dữ liệu mới được ghi vào shard, giúp tăng tính tin cậy và giảm độ trễ khi đọc dữ liệu.
Sử dụng EFO có thể giúp tối ưu hiệu suất đọc dữ liệu của các consumer và đảm bảo tính sẵn sàng của hệ thống. Nó cũng cho phép tăng số lượng consumer đọc dữ liệu từ các shard, giúp phân tán tải đọc và tăng khả năng mở rộng của hệ thống.
Tóm lại, Enhanced Fan-Out là một tính năng quan trọng của Amazon Kinesis Data Streams giúp cải thiện hiệu suất đọc dữ liệu và tính sẵn sàng của hệ thống.
Giờ mình sẽ lựa chọn Producers là AWS SDK để demo nhé. Đầu tiên hãy vào CloudShell và chúng ta có thể kiểm tra phiên bản của AWS CLI bằng lệnh aws --version.
[cloudshell-user@ip-10-0-39-58 ~]$ aws --version
aws-cli/2.1.16 Python/3.7.3 Linux/4.14.225-168.357.amzn2.×86_64 exec-env/CloudShell exe/x86_64. amzn.2 prompt/offHãy gửi lệnh user signup với cú pháp như sau:
aws kinesis put-record --stream-name DemoStream --partition-key user1 --data "user signup" --cli-binary-format raw-in-base64-outLệnh “aws kinesis put-record” là một lệnh trong AWS Command Line Interface (CLI) để gửi một bản ghi mới đến một stream Kinesis Data Stream trong tài khoản AWS của bạn.
- “–stream-name” là tên của stream Kinesis Data Stream mà bạn muốn gửi bản ghi tới.
- “–partition-key” là giá trị của khóa phân vùng cho bản ghi. Khi bạn gửi một bản ghi mới, Kinesis sẽ sử dụng giá trị này để xác định shard nào trong stream để gửi bản ghi tới.
- “–data” là nội dung của bản ghi. Đây có thể là bất kỳ định dạng nào, ví dụ như văn bản, JSON hoặc bất kỳ kiểu dữ liệu nào khác. Tuy nhiên, nếu bạn muốn gửi dữ liệu dưới dạng nhị phân, bạn cần sử dụng tùy chọn “–cli-binary-format raw-in-base64-out”.
- Sau khi chạy lệnh này, Kinesis sẽ ghi lại bản ghi mới vào stream Kinesis Data Stream của bạn. Nếu thành công, Kinesis sẽ trả về một số thông tin như “ShardId”, “SequenceNumber” và “EncryptionType” để xác định vị trí của bản ghi trong stream.
Bạn nhận được kết quả.
[cloudshell-user@ip-10-0-39-58 ~]$ aws kinesis put-record --stream-name DemoStream --partition-key user1 --data "user signup" --cli-binary-format raw-in-base64-out
{
"ShardId": "shardId-000000000000",
"SequenceNumber":"49617390934629201455926329624637508189499828916235272194"
}Nếu tôi tiếp tục chạy lệnh đó, tôi sẽ có kết quả thứ 2.
[cloudshell-user@ip-10-0-39-58 ~]$ aws kinesis put-record --stream-name DemoStream --partition-key user1 --data "user signup" --cli-binary-format raw-in-base64-out
{
"ShardId": "shardId-000000000000",
"SequenceNumber":"49617390934629201455926329624638717115319444438763175938"
}Bây giờ tôi sẽ gửi lệnh và đổi data thành user login.
[cloudshell-user@ip-10-0-39-58 ~]$ aws kinesis put-record --stream-name DemoStream --partition-key user1 --data "user login" --cli-binary-format raw-in-base64-out
{
"ShardId": "shardId-000000000000",
"SequenceNumber":"49617390934629201455926329624639926041139059686413172738"
}Cuối cùng tôi gửi lệnh và đổi data thành user logout.
[cloudshell-user@ip-10-0-39-58 ~]$ aws kinesis put-record --stream-name DemoStream --partition-key user1 --data "user logout" --cli-binary-format raw-in-base64-out
{
"ShardId" : "shardId-000000000000".
"SequenceNumber":"49617390934629201455926329624641134966958674590465785858"
}
Bây giờ chúng ta hãy xem mô tả về stream này bằng lệnh aws kinesis describe-stream --stream-name DemoStream với DemoStream là tên stream của bạn.
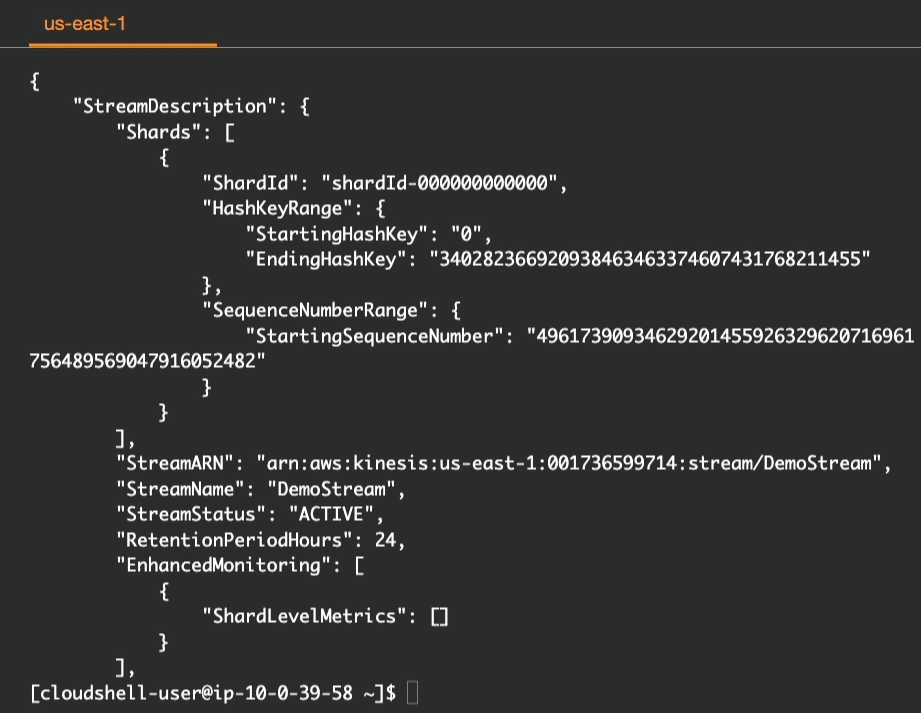
Hãy lấy dữ liệu từ một stream đã tạo trước đó và thực hiện các xử lý tiếp theo trên dữ liệu đó, chẳng hạn như lưu trữ vào cơ sở dữ liệu hoặc phân tích để đưa ra các quyết định hoặc hành động bằng lệnh dưới.
aws kinesis get-shard-iterator --stream-name DemoStream --shard-id shardId-000000000000 --shard-iterator-type TRIM_HORIZONLệnh aws kinesis get-shard-iterator được sử dụng để lấy shard iterator, tương ứng với một shard ID và một loại shard iterator nhất định.
Trong trường hợp này, lệnh aws kinesis get-shard-iterator --stream-name test --shard-id shardId-000000000000 --shard-iterator-type TRIM_HORIZON sẽ lấy shard iterator cho shard ID shardId-000000000000 trong stream test và sử dụng loại shard iterator là TRIM_HORIZON. Kết quả trả về là một chuỗi shard iterator có thể được sử dụng để bắt đầu đọc dữ liệu từ shard stream tương ứng. Shard iterator này sẽ trỏ đến vị trí bắt đầu của shard stream và đọc tất cả các bản ghi từ đó, và chúng ta có kết quả như dưới.
{
"ShardIterator": "AAAAAAAAAAGtYgUq00wFKpIqqDHDoswgADDT3VzUW6qPzgR04TPuWEbCgUZPVjI2adlKwjAUsIIpjLY0aC82nhF+ML2nlT5WxK3WLltulh340ZrsVw900gT6QpaZlkqi6wSKfb2yrqxj6ShbHueiUuqQMH/5hW2NRaLhgdxm6thQtoZF+BS+Ljcye7BJV1iwNKz29KH96EqGnn9UcxLyZoSLWXD/KV1uck88QV+u02S/HQ1+v/xKmw=="
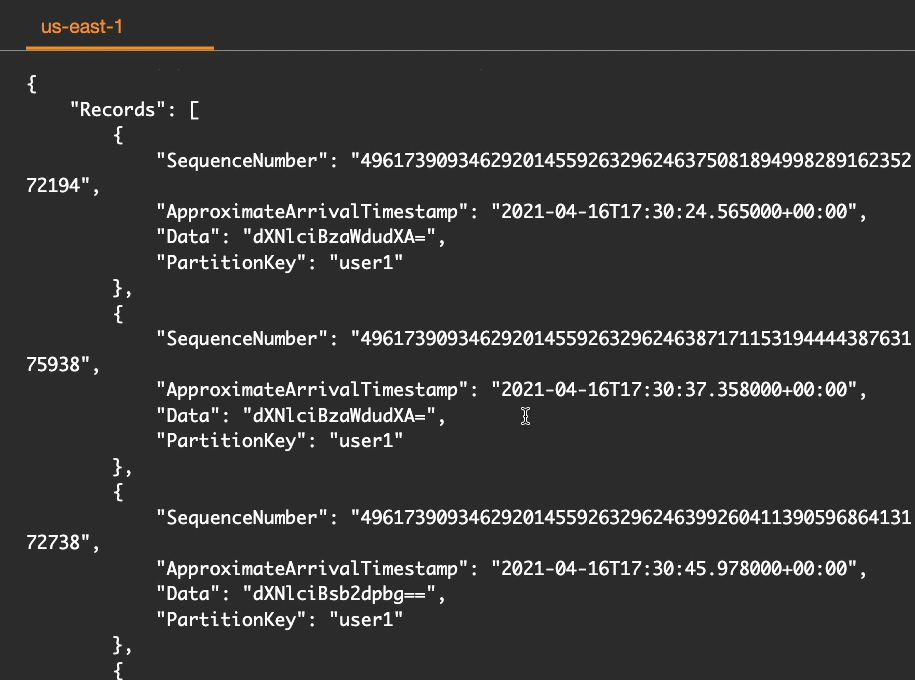
}Lệnh “aws kinesis get-records” được sử dụng để lấy các bản ghi (record) từ shard. Trong trường hợp này, shard iterator được truyền vào để chỉ định vị trí mà việc đọc bắt đầu. Shard iterator này được lấy từ lệnh “aws kinesis get-shard-iterator” với shard iterator type là “TRIM_HORIZON” để đọc các record từ đầu của shard. Với shard iterator này, lệnh sẽ lấy các bản ghi từ vị trí đầu tiên của shard cho đến khi đọc hết shard hoặc đến khi đạt được giới hạn dữ liệu lấy ra tối đa.
aws kinesis get-records --shard-iterator "AAAAAAAAAAGtYgUq00wFKpIqqDHDoswgADDT3VzUW6qPzgR04TPuWEbCgUZPVjI2adlKwjAUsIIpjLY0aC82nhF+ML2nlT5WxK3WLltulh340ZrsVw900gT6QpaZlkqi6wSKfb2yrqxj6ShbHueiUuqQMH/5hW2NRaLhgdxm6thQtoZF+BS+Ljcye7BJV1iwNKz29KH96EqGnn9UcxLyZoSLWXD/KV1uck88QV+u02S/HQ1+v/xKmw=="Đây là kết quả khi chạy lệnh trên, lưu ý đây là hình chụp kết quả không đầy đủ.
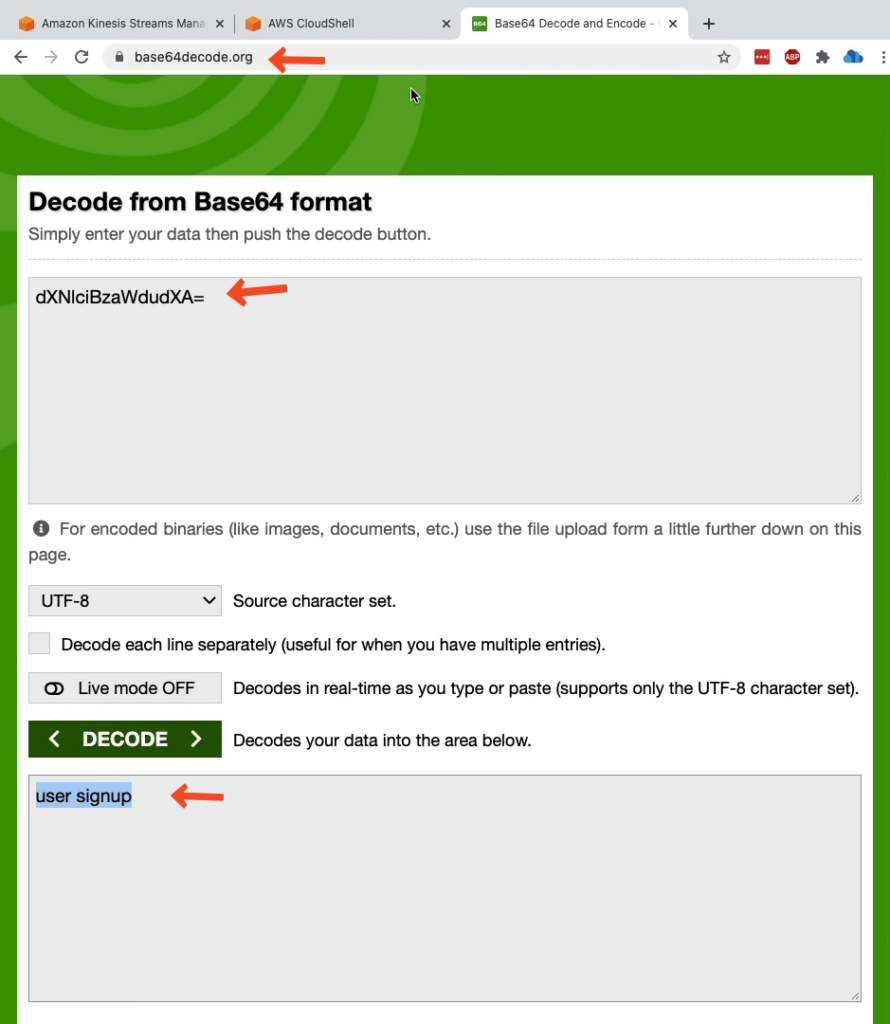
Bây giờ chúng hãy giải mã 1 trường Data xem kết quả như thế nào, ví dụ “dXN1ciBzaWdudXA=”. Mình sử dụng 1 công cụ online ví dụ base64decode.org để giải mã này và dưới đây là kết quả.


{kind=link}