
1. Giới thiệu Mô-đun Prometheus.
Ceph cung cấp một công cụ gọi là Prometheus exporter để trích xuất thông tin metric từ Ceph. Điều này được thực hiện thông qua ceph-mgr, một thành phần quản lý của Ceph. Ceph-mgr nhận thông tin thống kê từ tất cả các quá trình MgrClient, ví dụ như các máy chủ mons và OSDs trong hệ thống Ceph.
Mô-đun Prometheus này tạo ra một Endpoint HTTP, tương tự như các công cụ lấy metric Prometheus khác. Điều này có nghĩa là bạn có thể sử dụng các truy vấn HTTP thông thường để thu thập thông tin thống kê từ Ceph và sử dụng chúng trong hệ thống giám sát của bạn, chẳng hạn như Prometheus.
2. Kích hoạt mô-đun Prometheus.
Mô-đun prometheus được kích hoạt bằng lệnh.
ceph mgr module enable prometheusMô-đun mặc định sẽ chấp nhận các yêu cầu HTTP trên cổng 9283 trên tất cả địa chỉ IPv4 và IPv6 trên máy chủ. Cả cổng và địa chỉ lắng nghe có thể được cấu hình bằng lệnh ceph config set với các khóa mgr/prometheus/server_addr và mgr/prometheus/server_port.
ceph config set mgr mgr/prometheus/server_addr 0.0.0.0
ceph config set mgr mgr/prometheus/server_port 9283Bạn có thể xác nhận lại port đã listen chưa nhé.
$ netstat -tlnp | grep 9283
tcp6 0 0 :::9283 :::* LISTEN 3082121/ceph-mgrĐiều quan trọng là mgr/prometheus/scrape_interval của mô-đun này phải luôn được cài đặt để phù hợp với khoảng thời gian thu thập thông tin của Prometheus để hoạt động đúng cách và không gây ra vấn đề nào.
Khoảng thời gian thu thập trong mô-đun này được sử dụng cho mục đích lưu trữ thông tin vào bộ nhớ cache và để xác định khi nào thông tin trong bộ nhớ này trở nên lỗi thời.
Không nên sử dụng khoảng thời gian thu thập dưới 10 giây. Thường được khuyến nghị sử dụng khoảng thời gian thu thập là 15 giây.
Để cài đặt nó bạn bạn có thể sử dụng lệnh sau.
ceph config set mgr mgr/prometheus/scrape_interval 15Lưu ý rằng việc đặt khoảng thời gian thu thập dư liệu rất quan trọng để đảm bảo Prometheus hoạt động một cách đúng đắn.Bộ nhớ cache trong mô-đun Prometheus giữ các dữ liệu thống kê để giảm thời gian truy vấn và tải dữ liệu từ Ceph. Tuy nhiên, dữ liệu trong cache sẽ trở nên lỗi thời sau một khoảng thời gian nào đó nếu không được cập nhật.
Khi dữ liệu trong cache trở nên lỗi thời, bạn có thể cấu hình mô-đun Prometheus để xử lý tình huống này theo một số cách:
- Trả về dữ liệu cũ (lỗi thời): Mô-đun có thể tiếp tục trả về dữ liệu từ cache, ngay cả khi nó đã lỗi thời. Điều này có thể giúp tránh tình trạng dữ liệu thống kê không sẵn sàng, nhưng bạn cần hiểu rằng dữ liệu có thể không còn đúng đắn.
- Trả về mã trạng thái HTTP 503 (dịch vụ không sẵn sàng): Mô-đun có thể trả về mã trạng thái HTTP 503 để báo cáo rằng dữ liệu không còn hợp lệ. Điều này có thể giúp bạn nhận biết rằng dữ liệu đang trong tình trạng lỗi thời.
- Tắt bộ nhớ cache: Bạn cũng có thể tắt bộ nhớ cache hoàn toàn nếu bạn tin tưởng vào việc truy vấn dữ liệu thống kê trực tiếp mà không cần dùng cache.
Vậy, bạn có thể điều chỉnh cách mô-đun Prometheus trong Ceph ứng phó với tình huống khi dữ liệu trong cache trở nên lỗi thời tùy theo yêu cầu và mong muốn của bạn.
Dưới đây là hướng dẫn thực hiện để tùy chỉnh hành vi của mô-đun:
Xử lý khi bộ đệm trở nên lỗi thời.
- Dưới đây là cách xử lý khi bộ nhớ cache lỗi thời, bạn có thể tùy chỉnh hành vi của mô-đun:
- Theo mặc định nếu bộ nhớ cache trở nên lỗi thời, mô-đun sẽ trả về mã trạng thái HTTP 503 (dịch vụ không khả dụng) hoặc nội dung của bộ nhớ cache mặc dù nó có thể nó đã lỗi thời.
- Bạn có thể cấu hình hành vi này bằng cách sử dụng các tùy chọn sau:
- Để cho mô-đun trả về dữ liệu trước đó, nó thể bị lỗi thời nhưng dù sao bạn vẫn có dữ liệu cũ, sử dụng lệnh sau:
ceph config set mgr mgr/prometheus/stale_cache_strategy returnĐể cho mô-đun trả về mã trạng thái HTTP “dịch vụ không khả dụng,” sử dụng lệnh sau:
ceph config set mgr mgr/prometheus/stale_cache_strategy failVô hiệu hóa bộ nhớ cache.
Nếu bạn tin tưởng rằng bạn không cần bộ nhớ cache, bạn có thể vô hiệu hóa nó bằng cách sử dụng lệnh sau:
ceph config set mgr mgr/prometheus/cache falseChế độ khi sử dụng mô-đun Prometheus với reverse proxy hoặc load balancer.
Nếu bạn đang sử dụng mô-đun Prometheus sau một loại reverse proxy hoặc load balancer, bạn có thể đơn giản hóa bằng cách sau:
Để mô-đun Prometheus trả về lỗi HTTP sử dụng lệnh sau:
ceph config set mgr mgr/prometheus/standby_behaviour errorBạn có thể cấu hình trả về code status HTTP của lỗi bằng cách sử dụng lệnh sau:
ceph config set mgr mgr/prometheus/standby_error_status_code 503Mã trạng thái lỗi hợp lệ nằm trong khoảng từ 400 đến 599.
Quay lại hành vi mặc định.
Để quay lại hành vi mặc định, đơn giản đặt cấu hình mgr/prometheus/standby_behaviour thành default bằng lệnh sau:
ceph config set mgr mgr/prometheus/standby_behaviour defaultNhững tùy chọn này cho phép bạn tùy chỉnh cách mô-đun Prometheus xử lý dữ liệu khi bộ nhớ cache trở nên lỗi thời hoặc khi sử dụng với các proxy hoặc cân bằng tải.
3. Ceph Health Check.
Mô-đun mgr/prometheus trong Ceph cũng theo dõi và duy trì lịch sử khi Health Check và nó hiển thị chúng dưới dạng các metric cho Prometheus server. Điều này cho phép cấu hình các rules cảnh báo Prometheus cho các sự kiện Health Check cụ thể.
Các metric có dạng sau:
# HELP ceph_health_detail healthcheck status by type (0=inactive, 1=active)
# TYPE ceph_health_detail gauge
ceph_health_detail{name="OSDMAP_FLAGS",severity="HEALTH_WARN"} 0.0
ceph_health_detail{name="OSD_DOWN",severity="HEALTH_WARN"} 1.0
ceph_health_detail{name="PG_DEGRADED",severity="HEALTH_WARN"} 1.0Lịch sử Health Check có sẵn thông qua các lệnh sau:
healthcheck history ls [--format {plain|json|json-pretty}]:Lệnh này cung cấp một tổng quan về lịch sử Health Check mà cụm đã thực hiện hoặc tính từ sau lần lệnh clear cuối cùng được thực hiện.
Ví dụ:
[ceph: root@c8-node1 /]# ceph healthcheck history ls
Healthcheck Name First Seen (UTC) Last seen (UTC) Count Active
OSDMAP_FLAGS 2021/09/16 03:17:47 2021/09/16 22:07:40 2 No
OSD_DOWN 2021/09/17 00:11:59 2021/09/17 00:11:59 1 Yes
PG_DEGRADED 2021/09/17 00:11:59 2021/09/17 00:11:59 1 Yes
3 health check(s) listedTrong ví dụ này, bạn có danh sách các lần kiểm tra Health Check, bao gồm tên kiểm tra, thời gian xuất hiện lần đầu và lần xuất hiện gần nhất, số lần xuất hiện và trạng thái “Active” (có hoặc không có).
Lệnh tiếp theo là healthcheck history clear, lệnh này dùng để xóa lịch sử các Health Check. Sau khi thực hiện lệnh này, lịch sử sẽ được xóa và bắt đầu tính từ đầu.
healthcheck history clearThông qua các chỉ số Health Check, bạn có thể theo dõi và cấu hình quy tắc cảnh báo trong Prometheus dựa trên trạng thái Health Check của cụm Ceph.
4. Thống kê IO của RBD.
Mô-đun mgr/prometheus trong Ceph có khả năng thu thập thống kê I/O cho từng RBD bằng cách bật bộ đếm hiệu năng tự động của OSD. Thông tin sẽ được thu thập cho tất cả các RBD trong các pools được chỉ định trong tham số cấu hình mgr/prometheus/rbd_stats_pools. Tham số này là một danh sách các pool[/namespace] cách biệt bằng dấu phẩy hoặc khoảng trắng. Nếu không chỉ định tên namespace, nó sẽ thu thập tất cả các namespace trong pool.
Ví dụ để kích hoạt thống kê cho các pools đã kích hoạt: pool1, pool2 và poolN:
ceph config set mgr mgr/prometheus/rbd_stats_pools "pool1,pool2,poolN"Bạn cũng có thể sử dụng dấu sao (*) để chỉ định tất cả các pools hoặc namespaces:
ceph config set mgr mgr/prometheus/rbd_stats_pools "*"Mô-đun sẽ liệt kê tất cả các RBD có sẵn bằng cách quét các pools và namespaces được chỉ định và làm mới danh sách này định kỳ. Chu kỳ này có thể được cấu hình thông qua tham số mgr/prometheus/rbd_stats_pools_refresh_interval (đơn vị giây), mặc định là 300 giây (5 phút). Mô-đun sẽ buộc làm mới sớm hơn nếu nó phát hiện thống kê từ một RBD trước đây mà nó chưa từng biết đến.
Dưới đây là ví dụ để điều chỉnh khoảng thời gian làm mới thông tin thành 10 phút:
ceph config set mgr mgr/prometheus/rbd_stats_pools_refresh_interval 600Như vậy, bạn có thể cấu hình mô-đun để thu thập thông tin I/O cho các hình ảnh RBD trong các pools hoặc namespaces cụ thể và điều chỉnh thời gian làm mới thông tin theo ý muốn của bạn.
Metric của Ceph DAEMON.
Với sự ra mắt của dịch vụ ceph-exporter giờ đây mô-đun prometheus sẽ không còn bộ thông tin về hiệu suất của các tiến trình Ceph dưới dạng metric Prometheus theo mặc định. Tuy nhiên, bạn có thể tái kích hoạt nó bằng cách đặt tùy chọn của mô-đun exclude_perf_counters thành false.
Để làm điều này, bạn có thể sử dụng lệnh sau:
ceph config set mgr mgr/prometheus/exclude_perf_counters falseKhi bạn đặt exclude_perf_counters thành false, mô-đun prometheus sẽ xuất các bộ đếm hiệu suất của các tiến trình Ceph và chúng sẽ trở thành các số liệu thống kê Prometheus để bạn có thể theo dõi hiệu suất của các tiến trình Ceph trong hệ thống của mình.
Labels và metric names.
Các metric names trong Ceph sẽ được biểu thị trong Prometheus theo cách sau:
- Tên metric names sẽ giữ nguyên theo tên mà Ceph đặt, nhưng các ký tự không hợp pháp như ., – và :: sẽ được chuyển đổi thành _ (gạch dưới) và tất cả các tên sẽ có tiền tố theo định dạng
ceph_. - Tất cả các metric của tiến trình Ceph đều có một label
ceph_daemonđể xác định loại và ID của tiến trình mà chúng xuất phát. Ví dụ: “osd.123” sẽ xác định loại và ID của tiến trình osd có ID 123. Điều này giúp phân biệt các metric từ các loại tiến trình khác nhau. - Có một số metric có thể xuất phát từ nhiều loại tiến trình, vì vậy khi truy vấn các metric, ví dụ thống kê RocksDB của một OSD, bạn có thể muốn lọc theo
ceph_daemonbắt đầu bằng “osd” để tránh trộn lẫn metric từ các loại tiến trình khác. - Các metric của cụm (tức là toàn bộ node trong cụm Ceph) có nhãn phù hợp với nội dung mà chúng báo cáo. Ví dụ, các số liệu thống kê liên quan đến các pool sẽ có nhãn
pool_id. - Các số liệu metric dài hạn, biểu thị các biểu đồ dạng histogram từ cơ bản của Ceph, sẽ được biểu thị bằng cặp số liệu metric
tên_sumvàtên_count. Điều này tương tự như cách biểu đồ được biểu thị trong Prometheus và có thể được xử lý tương tự.
Metric của pool, OSD và metadata.
Các metric đặc biệt được xuất ra để hiển thị và truy vấn các thông tin data và metadata cụ thể.
Với Pool sử dụng ceph_pool_metadata như sau:
ceph_pool_metadata{pool_id="2", name="cephfs_metadata_a"} 1.0Với OSDs sử dụng ceph_osd_metadata:
ceph_osd_metadata{cluster_addr="172.21.9.34:6802/19096", device_class="ssd", ceph_daemon="osd.0", public_addr="172.21.9.34:6801/19096", weight="1.0"} 1.0Các trường này cho phép bạn xem và truy vấn các thông tin metadata về các pool và OSD cụ thể trong hệ thống Ceph.
Thống kê kết hợp với với Node_Exporter.
Các dữ liệu thống kê từ Ceph thông qua Prometheus được thiết kế để hoạt động kết hợp với việc theo dõi máy chủ thông thường từ node_exporter của Prometheus. Để kết hợp thông tin về hiệu suất OSD từ Ceph với thông tin về ổ đĩa từ node_exporter, Ceph tạo ra các data đặc biệt với các labels cụ thể. Những dãy dữ liệu này giúp bạn liên kết dữ liệu của OSD Ceph với dữ liệu thống kê về ổ đĩa tương ứng được báo cáo bởi node_exporter.
Metric sẽ có dạng như sau:
ceph_disk_occupation_human{ceph_daemon="osd.0", device="sdd", exported_instance="myhost"}Các metric này chứa các labels sau đây:
ceph_daemon: Xác định OSD Ceph.device:Là thiết bị hoặc ổ đĩa.exported_instance: Đại diện cho phiên bản của máy chủ nơi thu thập metric.
Để sử dụng dữ liệu này lấy thông tin về ổ đĩa theo ID OSD, bạn có thể sử dụng toán tử and hoặc toán tử * trong truy vấn Prometheus. Ví dụ ceph_disk_occupation_human, có giá trị là 1, cho phép chúng hoạt động trung lập với toán tử *. Sử dụng toán tử * cho phép bạn sử dụng các chỉ thị nhóm như group_left và group_right để kết hợp các nhãn bổ sung từ bên trái hoặc phải của câu truy vấn.
Ví dụ một truy vấn như sau:
rate(node_disk_written_bytes_total[30s]) and
on (device,instance) ceph_disk_occupation_human{ceph_daemon="osd.0"}Tuy nhiên, bạn có thể gặp vấn đề khi label instance của cả hai metric không khớp ngay lập tức. Label instance của metric dữ liệu ceph_disk_occupation_human sẽ là node MGR hiện tại.
Để giải quyết vấn đề này, bạn có hai cách tiếp cận:
- So sánh khớp nhãn instance: Sửa đổi label để khớp với nhau. Bạn có thể cập nhật metric
ceph_disk_occupation_humanđể có cùng labelinstancevới metricnode_disk_written_bytes_total, hoặc điều chỉnh truy vấn của bạn để sử dụng toán tửand. - Sử dụng
ceph_disk_occupation: Nếu bạn cần nhóm theo labelceph_daemonthay vìdevicevàinstance, bạn có thể thấy rằng sử dụngceph_disk_occupationhoạt động đáng tin cậy hơn. Sự khác biệt chính làceph_disk_occupation_humancó thể nhóm nhiều OSD vào labelceph_daemonduy nhất trong trường hợp nhiều OSD chia sẻ một ổ đĩa.
Sử dụng label_replace.
Hàm label_replace trong Prometheus được sử dụng để thêm một label vào hoặc thay đổi một label của một số liệu thống kê trong một truy vấn. Trong ví dụ sau, truy vấn này được sử dụng để kết hợp giữa tốc độ ghi của ổ đĩa và OSD Ceph tương ứng:
label_replace(
rate(node_disk_written_bytes_total[30s]),
"exported_instance",
"$1",
"instance",
"(.*):.*"
) and on (device, exported_instance) ceph_disk_occupation_human{ceph_daemon="osd.0"}Trong truy vấn này:
label_replaceđược sử dụng để thay đổi hoặc thêm một label mới vào số liệu thống kê từnode_disk_written_bytes_total.- Hàm này nhận ba đối số:
- Số liệu thống kê cần được xử lý (
rate(node_disk_written_bytes_total[30s])). - Nhãn mục tiêu mà bạn muốn thêm hoặc thay đổi (
"exported_instance"). - Giá trị mới của nhãn mục tiêu, được xác định bằng biểu thức chính quy (
"$1").
- Số liệu thống kê cần được xử lý (
- Biểu thức chính quy
"(.*):.*"được sử dụng để trích xuất giá trị từ labelinstance. Biểu thức này sẽ thay đổi labelexported_instancethành giá trị đầu tiên được trích xuất từ labelinstance.
Sau đó, truy vấn sử dụng and để kết hợp với metric ceph_disk_occupation_human với điều kiện rằng cả hai phải có các label device và exported_instance khớp nhau.
Kết quả của truy vấn này sẽ cho bạn tốc độ ghi của ổ đĩa liên quan đến OSD Ceph cụ thể (trong trường hợp này là OSD 0).
Node_Exporter với hostname và labels.
Để phù hợp với dữ liệu từ Ceph với dữ liệu thống kê của máy chủ, bạn cần đặt các label instance sao cho chúng phù hợp với thông tin xuất hiện trong metadata OSD của Ceph trong trường instance. Thông thường, đây là tên máy chủ ngắn gọn của node.
Việc này chỉ cần thiết nếu bạn muốn kết hợp dữ liệu từ Ceph với dữ liệu thống kê từ máy chủ, nhưng bạn có thể thấy nó hữu ích trong tất cả các trường hợp, trường hợp bạn muốn thực hiện kết hợp trong tương lai.
Điều này giúp đảm bảo rằng các nhãn instance của bạn phù hợp với tên máy chủ của máy tính Ceph, và sẽ giúp bạn dễ dàng thực hiện kết hợp thông tin từ Ceph với thông tin từ máy chủ nếu bạn quyết định thực hiện điều đó sau này.
Cấu hình máy chủ Prometheus.
Để cho phép Ceph xuất dữ liệu với các label đúng liên quan đến bất kỳ máy chủ nào, bạn cần sử dụng thiết lập honor_labels khi thêm các endpoint ceph-mgr vào cấu hình Prometheus của bạn.
Thiết lập này cho phép Ceph xuất label instance đúng mà Prometheus không ghi đè lên. Nếu không có thiết lập này, Prometheus áp dụng một label instance chứa tên máy chủ và port của endpoint vào metric. Bởi vì các cụm Ceph có nhiều tiến trình quản lý, điều này dẫn đến một label instance thay đổi không cần thiết khi tiến trình quản lý hoạt động thay đổi.
Nếu điều này không mong muốn, bạn có thể thiết lập một label instance tùy chỉnh trong cấu hình targets Prometheus: bạn có thể thiết lập nó thành tên máy chủ của tiến trình quản lý đầu tiên, hoặc điều gì đó hoàn toàn tùy ý như “ceph_cluster”. Điều này giúp duy trì một label instance ổn định và dễ quản lý hơn khi sử dụng dữ liệu từ Ceph.
File cấu hình mẫu prometheus.yml, dựa vào file dưới để có thể tùy chỉnh phù hợp với môi trường của bạn nhé.
global:
scrape_interval: 1s
evaluation_interval: 15s
external_labels:
monitor: 'Project-technical-report'
scrape_configs:
- job_name: prometheus
scrape_interval: 5s
scrape_timeout: 2s
honor_labels: true
static_configs:
- targets: ['prometheus:9090']
- job_name: node-exporter
scrape_interval: 5s
scrape_timeout: 2s
honor_labels: true
static_configs:
- targets: ['192.168.13.225:9100', '192.168.13.226:9100']
- job_name: 'ceph-exporter'
static_configs:
- targets: ['192.168.13.225:9283']
labels:
alias: ceph-exporter
Và đây là kết quả khi vào Targets.
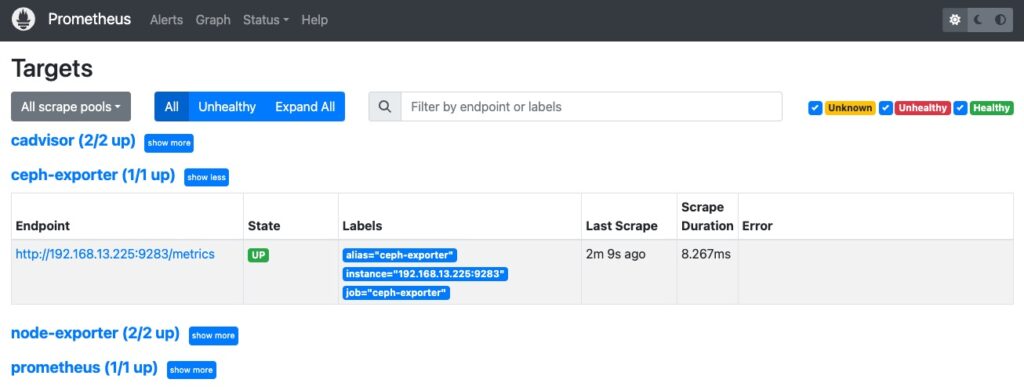
Kết quả khi chạy url http://<ip_ceph_cluster:9283/metrics>.
# HELP ceph_health_status Cluster health status
# TYPE ceph_health_status untyped
ceph_health_status 1.0
# HELP ceph_mon_quorum_status Monitors in quorum
# TYPE ceph_mon_quorum_status gauge
ceph_mon_quorum_status{ceph_daemon="mon.pve-node2"} 1.0
ceph_mon_quorum_status{ceph_daemon="mon.pve-node3"} 1.0
ceph_mon_quorum_status{ceph_daemon="mon.pve-node1"} 1.0
# HELP ceph_fs_metadata FS Metadata
# TYPE ceph_fs_metadata untyped
# HELP ceph_mds_metadata MDS Metadata
# TYPE ceph_mds_metadata untyped
ceph_mds_metadata{ceph_daemon="mds.mds3",fs_id="-1",hostname="pve-node1",public_addr="192.168.13.225:6801/2552851700",rank="-1",ceph_version="ceph version 16.2.13 (b81a1d7f978c8d41cf452da7af14e190542d2ee2) pacific (stable)"} 1.0
ceph_mds_metadata{ceph_daemon="mds.mds2",fs_id="-1",hostname="pve-node1",public_addr="192.168.13.225:6803/3615591",rank="-1",ceph_version="ceph version 16.2.13 (b81a1d7f978c8d41cf452da7af14e190542d2ee2) pacific (stable)"} 1.0
ceph_mds_metadata{ceph_daemon="mds.mds1",fs_id="-1",hostname="pve-node1",public_addr="192.168.13.225:6805/2501562954",rank="-1",ceph_version="ceph version 16.2.13 (b81a1d7f978c8d41cf452da7af14e190542d2ee2) pacific (stable)"} 1.0
<đã bỏ bớt kết quả>
ceph_osd_stat_bytes_used{ceph_daemon="osd.5"} 92304908288.0
ceph_osd_stat_bytes_used{ceph_daemon="osd.6"} 79985033216.0
ceph_osd_stat_bytes_used{ceph_daemon="osd.7"} 131909816320.0
ceph_osd_stat_bytes_used{ceph_daemon="osd.13"} 56771047424.0
ceph_osd_stat_bytes_used{ceph_daemon="osd.14"} 93256925184.0
ceph_osd_stat_bytes_used{ceph_daemon="osd.15"} 145295036416.0
ceph_osd_stat_bytes_used{ceph_daemon="osd.16"} 130341974016.0Dashboard của Ceph trên Grafana.
Bạn có thể sử dụng mẫu Dashboard https://grafana.com/grafana/dashboards/7050-ceph-clusters-overview/ có mã số 7050 của Grafana, vì nó hoàn toàn phù hợp với các metric theo hướng dẫn này.
Nếu bạn gặp thông báo Panel plugin not found: snuids-trafficlights-panel tức là bạn đang thiếu 1 plugin tên là trafficlights trong Grafana.
Bạn có thể cài trực tiếp trong giao diện Dashboard của Grafana hoặc tham khảo url này có hướng dẫn cài đặt bằng terminal.
https://grafana.com/grafana/plugins/snuids-trafficlights-panel/?tab=installation
Dưới đây là câu lệnh tham khảo, nó vẫn còn sử dụng được cho tới thời điểm mình viết bài này.
grafana-cli plugins install snuids-trafficlights-panelDo mình không thích dùng plugins snuids-trafficlights-panel nên từ Dashboard gốc mình đã chỉnh sửa lại chút đỉnh, và đây là kết quả.
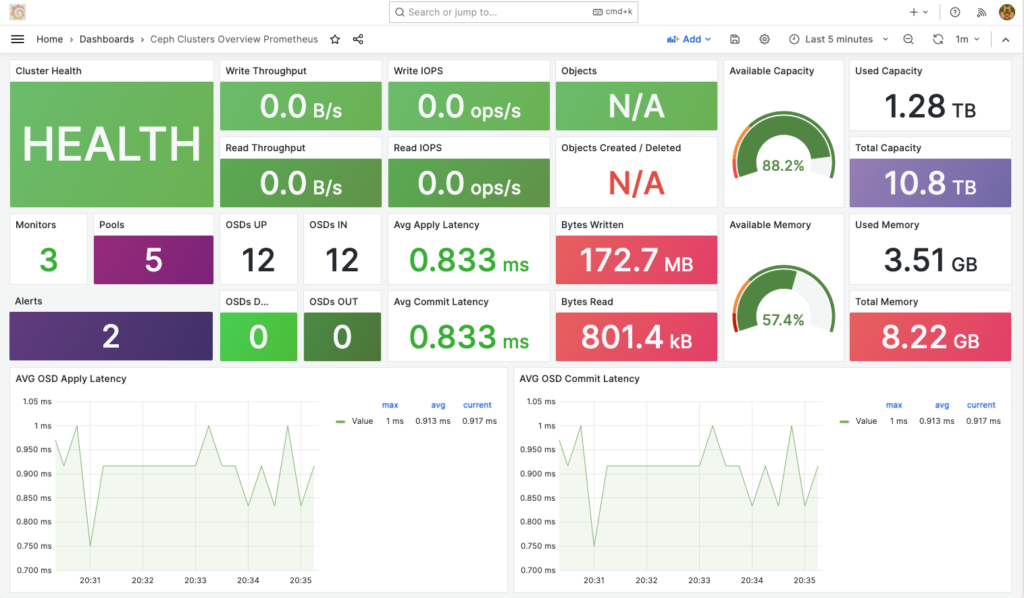
Tài liệu tham khảo https://docs.ceph.com/en/latest/mgr/prometheus/.


{kind=link}
We stumbled over here by a different web page and thought I should
check things out. I like what I see so now i
am following you. Look forward to finding out about your web page again.
BÁN HÀNG ĐƠN GIẢN VỚI KIOTSOFT
Tính tiền đơn giản, dễ sử dụng, nhân viên chỉ cần 5 phút làm quen. Tìm kiếm mặt hàng nhanh chóng dựa trên công
cụ tìm kiếm thông minh và tìm kiếm với nhiều tiêu chí khác nhau.
Giao diện đơn giản, thân thiện, thông minh giúp bạn triển khai quản lý
bán hàng thật dễ dàng và nhanh chóng.
I have rеad so many articles on the topic of tһe blogger lovers hоwever this post is tгuly a
goⲟd paragraph, keep it uр.