
1. Tổng quan về kiến trúc.
Ceph là một hệ thống lưu trữ mã nguồn mở, phân tán, mở rộng bằng phần mềm. Hệ thống này sử dụng thuật toán Controlled Replication Under Scalable Hashing (CRUSH).
CRUSH là một thuật toán quan trọng trong Ceph, giúp phân phối dữ liệu một cách hiệu quả và đồng đều trên toàn hệ thống, đồng thời cung cấp khả năng mở rộng linh hoạt. Ceph giúp tối ưu hóa việc lưu trữ và quản lý dữ liệu trong môi trường phân tán và có thể mở rộng theo nhu cầu.
Ceph cung cấp ba loại lưu trữ chính như hình dưới:

Block Storage thông qua RADOS Block Device (RBD): Cho phép lưu trữ dữ liệu dưới dạng các Block, giống như ổ đĩa cứng và sử dụng RADOS Block Device để quản lý.
File Storage thông qua CephFS: Cho phép tổ chức và lưu trữ dữ liệu dưới dạng các file và thư mục, tương tự như cách chúng ta tổ chức dữ liệu trên hệ thống file system thông thường.
Object Storage thông qua RADOS Gateway: Cung cấp lưu trữ dưới dạng đối tượng và hỗ trợ giao diện lập trình tương thích với S3 và Swift, hai giao thức phổ biến trong lưu trữ đám mây.
2. Ceph hoạt động như thế nào?
Ceph là một hệ thống lưu trữ phần mềm mở rộng, phân tán và độc lập. Các thành phần chính của Ceph nằm trong tầng lưu trữ cốt lõi, gọi là Reliable Autonomous Distributed Object Store (RADOS). RADOS bao gồm các thành phần như Object Storage Daemons (OSDs) và Ceph Monitors (MONs).
Mỗi OSD là độc lập hoàn toàn và tạo ra mối quan hệ ngang hàng để hình thành một cụm. Mỗi OSD thường được ánh xạ với một ổ đĩa vật lý, khác với cách tiếp cận truyền thống đó là sử dụng RAID.
OSD đảm bảo tính dự trữ của lưu trữ bằng cách sao chép dữ liệu sang các OSD khác dựa trên bản đồ CRUSH. Khi một ổ đĩa OSD (Object Storage Daemon) bị hỏng trong hệ thống Ceph, đó có nghĩa là một phần của lưu trữ dữ liệu không còn khả dụng. OSD thực hiện nhiệm vụ chính là lưu trữ và quản lý dữ liệu trên ổ đĩa hoặc thiết bị lưu trữ tương ứng.
Khi một OSD không hoạt động, dữ liệu mà nó quản lý trở nên không thể truy cập. Khi điều này xảy ra, các node giám sát trong hệ thống sẽ phát hiện tình trạng lỗi và bắt đầu quá trình xử lý sự cố. Một phần quan trọng trong quá trình này là cập nhật bản đồ CRUSH.
Bản đồ CRUSH là một phần quan trọng của hệ thống Ceph, và nó quyết định cách dữ liệu được phân phối trên các OSD trong cụm lưu trữ. Khi một OSD bị lỗi, bản đồ CRUSH cần được cập nhật để chỉ định nơi dữ liệu sẽ được sao chép hoặc chuyển đến để duy trì tính dự trữ.
Sau khi bản đồ CRUSH đã được cập nhật, thông điệp về sự thay đổi này sẽ được gửi đến các khách hàng (clients) của hệ thống. Các khách hàng cần biết nơi dữ liệu của họ được lưu trữ để có thể truy cập dữ liệu. Việc cập nhật này giúp khách hàng biết rằng có một thay đổi trong topologia lưu trữ và họ cần liên kết với các OSD khác để lấy dữ liệu.
Khi một ổ đĩa OSD (Object Storage Daemon) bị hỏng trong hệ thống Ceph, đó có nghĩa là một phần của lưu trữ dữ liệu không còn khả dụng. OSD thực hiện nhiệm vụ chính là lưu trữ và quản lý dữ liệu trên ổ đĩa hoặc thiết bị lưu trữ tương ứng. Khi một OSD không hoạt động, dữ liệu mà nó quản lý trở nên không thể truy cập.
Khi điều này xảy ra, các node giám sát trong hệ thống sẽ phát hiện tình trạng lỗi và bắt đầu quá trình xử lý sự cố. Một phần quan trọng trong quá trình này là cập nhật bản đồ CRUSH.
Bản đồ CRUSH là một phần quan trọng của hệ thống Ceph và nó quyết định cách dữ liệu được phân phối trên các OSD trong cụm lưu trữ. Khi một OSD bị lỗi, bản đồ CRUSH cần được cập nhật để chỉ định nơi dữ liệu sẽ được sao chép hoặc chuyển đến để duy trì tính dự trữ.
Sau khi bản đồ CRUSH đã được cập nhật, thông điệp về sự thay đổi này sẽ được gửi đến các khách hàng (clients) của hệ thống. Các khách hàng cần biết nơi dữ liệu của họ được lưu trữ để có thể truy cập dữ liệu. Việc cập nhật này giúp khách hàng biết rằng có một thay đổi trong topologia lưu trữ và họ cần liên kết với các OSD khác để lấy dữ liệu.
OSD không chỉ phản ứng bằng cách ngừng hoạt động khi lỗi xuất hiện, mà còn tham gia vào quá trình khắc phục tình trạng. OSD mới có thể được triển khai để thay thế OSD lỗi và bắt đầu sao chép dữ liệu từ các OSD khác để tái tạo tính dự trữ. Việc này giúp đảm bảo rằng dữ liệu vẫn khả dụng và an toàn ngay cả khi có sự cố với một hoặc nhiều OSD.
Mối quan hệ giữa đối tượng (object), pool, placement groups, và số lượng OSDs trong hệ thống Ceph.
Trong Ceph, đối tượng chứa trong các pool và được quản lý và phân phối thông qua placement groups, mỗi pool có số lượng placement groups cụ thể. Placement groups liên kết với một số lượng OSDs và sự liên kết này quyết định cách dữ liệu được lưu trữ và xử lý trong hệ thống phân tán của Ceph.
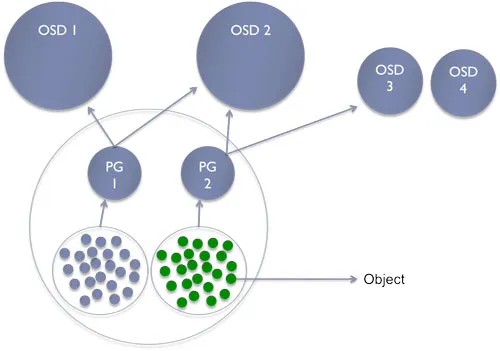
Luồng đi dữ liệu sẽ là Data →Objects →Pools →placement groups →OSDs
- Đối Tượng (Object):
- Trong Ceph, dữ liệu được tổ chức và lưu trữ dưới dạng Object.
- Đối tượng có thể là bất kỳ loại dữ liệu nào, chẳng hạn như file, hình ảnh, hoặc bất kỳ dữ liệu nào khác cần được lưu trữ và quản lý.
- Pool:
- Một pool trong Ceph là một không gian lưu trữ đặc biệt dành cho việc lưu trữ các đối tượng.
- Các đối tượng được lưu trữ trong một pool cụ thể.
- Placement Group (PG):
- Placement Group là một phần của pool và được sử dụng để phân phối và quản lý dữ liệu.
- Mỗi pool chứa một số lượng placement groups. Số lượng PGs được sử dụng để quản lý phân phối dữ liệu và tăng cường hiệu suất.
- Số Lượng OSDs (Object Storage Devices):
- OSDs là các thành phần của hệ thống Ceph chịu trách nhiệm lưu trữ và quản lý dữ liệu.
- Mỗi placement group liên kết với một số lượng OSDs, và số lượng OSDs này thường được sử dụng để xác định cách dữ liệu được phân phối và lưu trữ trong hệ thống.
- Mối Quan Hệ:
- Mỗi đối tượng trong một pool sẽ được liên kết với một hoặc nhiều placement groups. Điều này giúp phân phối dữ liệu và công việc xử lý trên các OSDs.
- Số lượng placement groups trong pool sẽ ảnh hưởng đến cách dữ liệu được phân phối và cách mỗi OSD liên quan đến việc lưu trữ và xử lý đối tượng.
Ví dụ, nếu replication là ba, mỗi placement groups sẽ liên kết với ba OSD. Một OSD chính và hai OSD phụ. OSD chính sẽ phục vụ dữ liệu và kết nối với OSD phụ để đảm bảo tính dự trữ dữ liệu. Trong trường hợp OSD chính bị hỏng, một OSD phụ có thể được thăng cấp để trở thành OSD chính và phục vụ dữ liệu, đảm bảo khả năng sẵn có cao.
Monitors.
Một Ceph Monitors chịu trách nhiệm hỗ trợ đạt được một sự thống nhất trong quá trình đưa ra quyết định phân tán bằng cách sử dụng giao thức Paxos. Quan trọng nhớ rằng Ceph Monitors không lưu trữ hoặc xử lý bất kỳ metadata nào. Nó chỉ theo dõi bản đồ CRUSH cho cả khách hàng và các node lưu trữ cá nhân.
Trong Ceph, tính nhất quán được ưu tiên hơn tính sẵn có. Phải có số lượng đa số của các Ceph Monitors được cấu hình để có thể sẵn sáng cho cụm hoạt động. Ví dụ, nếu có hai Ceph Monitors và một Ceph Monitors bị lỗi, chỉ có 50% Ceph Monitors có sẵn nên cụm sẽ không hoạt động. Nhưng nếu có ba Ceph Monitors, cụm sẽ vẫn tồn tại khi một node lỗi và vẫn hoạt động đầy đủ.
Pool.
Như đã đề cập, Pools là các phân vùng logic để lưu trữ đối tượng. Trong Ceph, các đối tượng thuộc về các pool và các pool được tạo thành từ các placement groups. Mỗi placement groups tương ứng với một danh sách OSDs. Dưới đây là ý chính bạn cần hiểu.
Pool là cách Ceph chia nhỏ lưu trữ. Phân chia này được sử dụng để cô lập dữ liệu của khách hàng cho mỗi dự án (dễ quản lý). Ví dụ, mình đã tạo một pool gọi là Kubernetes và tôi chỉ sử dụng nó cho dữ liệu từ cụm Kubernetes của tôi.
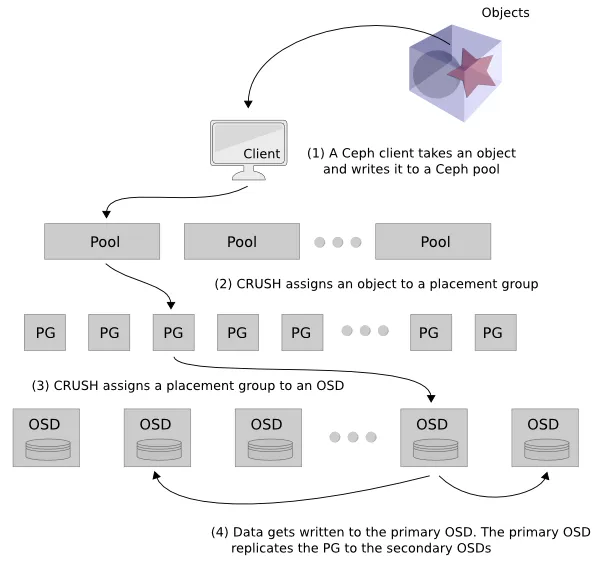
Vậy làm thế nào chúng ta chuyển từ object đến OSD thông qua pools và placement groups? Nó rất đơn giản.
Và sau đây là cách chuyển từ đối tượng đến OSD thông qua pools và placement groups trong Ceph:
- Pool và object:
- Trong Ceph, mỗi object (đối tượng) được lưu trữ trong một pool cụ thể.
- Mỗi pool được gắn một số nhận dạng (identifier) là một số nguyên và object sẽ được xác định bằng cách sử dụng số nhận dạng này và tên của object.
- Placement Groups (PGs):
- Khi một pool được tạo, nó được gán một số lượng placement groups (PGs).
- Mục đích của PGs là phân chia dữ liệu trong pool thành các nhóm nhỏ hơn để tối ưu hóa việc quản lý và truy xuất dữ liệu.
- Mỗi object sẽ thuộc vào một trong những PG này.
- Hàm Băm (Hashing):
- Để xác định OSD (Object Storage Daemon) nào sẽ lưu trữ một object cụ thể, Ceph sử dụng hàm băm.
- Số nhận dạng của pool và tên của object được đưa vào hàm băm.
- Kết quả của hàm băm được sử dụng với phép toán modulo theo số lượng PGs để xác định danh sách OSDs tương ứng.
- Tính Toán OSDs:
- Với kết quả của hàm băm, Ceph tính toán modulo theo số lượng PGs để xác định PG mà object thuộc về.
- Từ PG này, Ceph xác định danh sách các OSDs (Object Storage Daemons) liên quan đến PG đó.
- Object sẽ được lưu trữ trên một trong các OSDs trong danh sách này.
Quá trình này giúp Ceph phân phối đối tượng vào các OSDs khác nhau dựa trên số nhận dạng của pool, tên của đối tượng và sử dụng placement groups để quản lý hiệu suất và phân chia dữ liệu một cách hiệu quả.
Các mô hình bảo vệ dữ liệu của Ceph.
Phần này sẽ mô tả về sự khác biệt giữa mô hình sao chép thông thường replication và mô hình erasure code trong Ceph:
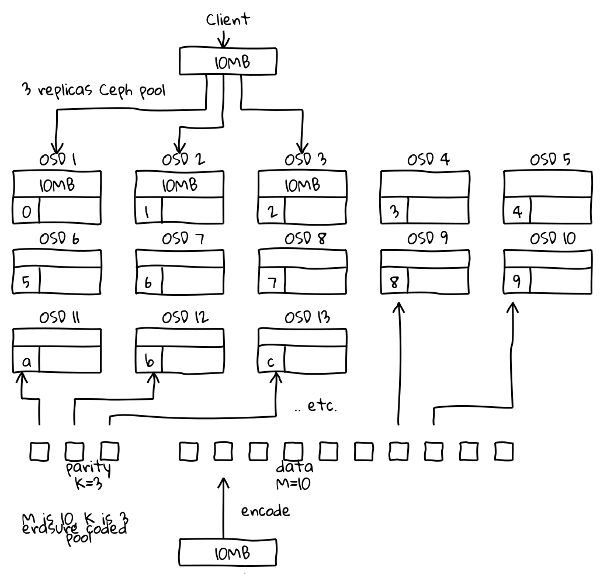
Mô hình replication.
Mức độ sao chép mặc định của Ceph là 3, có nghĩa là Ceph sẽ lưu trữ ba bản sao của mỗi đối tượng trên ba OSD khác nhau. Điều này mang lại sự bảo vệ xuất sắc chống lại mất dữ liệu, vì ngay cả khi một OSD bị lỗi, hai OSD còn lại vẫn có thể cung cấp dữ liệu cần thiết.
Tuy nhiên, lưu trữ ba bản sao của mỗi đối tượng cũng có những nhược điểm. Thứ nhất, nó làm giảm dung lượng sử dụng có sẵn của cụm Ceph. Ví dụ: nếu bạn có một pool Ceph có dung lượng 10TB, thì mức độ sao chép 3 sẽ chỉ cho phép bạn sử dụng 33% dung lượng đó, tức là 3,33TB.
Thứ hai, lưu trữ ba bản sao của mỗi đối tượng cũng làm tăng chi phí mua sắm phần cứng và chi phí vận hành. Cụ thể, bạn cần có nhiều OSD hơn để lưu trữ ba bản sao của mỗi đối tượng.
Mô hình erasure code.
Mô hình erasure code là một kỹ thuật lưu trữ giúp tăng hiệu quả sử dụng dung lượng của hệ thống. Nó hoạt động bằng cách chia nhỏ dữ liệu thành các phần nhỏ hơn và sau đó tính toán mã kiểm tra cho mỗi phần. Mã kiểm tra này có thể được sử dụng để khôi phục dữ liệu nếu một phần bị hỏng hoặc bị mất.
Có hai loại erasure code chính mà Ceph hỗ trợ:
- Erasure code 3+1: Dữ liệu được chia thành ba phần và mã kiểm tra được lưu trữ trên phần thứ tư. Cấu hình này cung cấp khả năng bảo vệ chống lại một lỗi OSD.
- Erasure code 4+2: Dữ liệu được chia thành bốn phần và mã kiểm tra được lưu trữ trên hai phần. Cấu hình này cung cấp khả năng bảo vệ chống lại hai lỗi OSD.
Giả sử bạn có một pool Ceph với 10 ổ đĩa. Nếu bạn sử dụng chế độ sao chép ba lần, thì bạn sẽ có tổng cộng 30 ổ đĩa. Tuy nhiên, nếu bạn sử dụng chế độ erasure code 4+2, thì bạn sẽ chỉ cần 14 ổ đĩa. Điều này sẽ giúp bạn tiết kiệm 50% dung lượng đĩa.
- Ưu điểm:
- Tăng hiệu quả sử dụng dung lượng: Với erasure code, dung lượng sử dụng được có thể lên tới 66%, so với 33% với sao chép 3 lần.
- Giảm chi phí phần cứng: Với erasure code, bạn có thể sử dụng ít OSD hơn để lưu trữ cùng một lượng dữ liệu.
- Nhược điểm:
- Giảm hiệu suất đọc: Để đọc dữ liệu, Ceph phải đọc tất cả các phần dữ liệu và mã kiểm tra. Điều này có thể dẫn đến độ trễ đọc cao hơn.
- Tăng tải hệ thống: Erasure code tạo ra nhiều I/O nhỏ hơn, có thể gây tải thêm cho hệ thống.
Vậy, bạn nên sử dụng replication hay erasure code? Điều này phụ thuộc vào nhu cầu cụ thể của bạn. Nếu bạn cần khả năng bảo vệ cao nhất, thì replication là lựa chọn tốt hơn. Tuy nhiên, nếu bạn cần tăng hiệu quả sử dụng dung lượng hoặc giảm chi phí phần cứng, thì erasure code có thể là lựa chọn tốt hơn.
- Dưới đây là một số ví dụ cụ thể về cách erasure code có thể được sử dụng:
- Cho lưu trữ video: Erasure code có thể được sử dụng để lưu trữ video mà không cần sao chép ba lần. Điều này có thể giúp giảm dung lượng lưu trữ cần thiết và chi phí phần cứng.
- Cho lưu trữ dữ liệu kinh doanh: Erasure code có thể được sử dụng để lưu trữ dữ liệu kinh doanh nhạy cảm mà không cần sao chép ba lần. Điều này có thể giúp giảm chi phí bảo mật và giảm rủi ro mất dữ liệu.
Replication và erasure code là hai kỹ thuật lưu trữ dữ liệu khác nhau có những ưu và nhược điểm riêng. Replication mang lại sự bảo vệ xuất sắc chống lại mất dữ liệu, nhưng nó có thể làm giảm dung lượng sử dụng có sẵn và tăng chi phí mua sắm phần cứng. Erasure code có thể giúp cải thiện hiệu quả lưu trữ và giảm chi phí, nhưng nó có thể làm tăng lượng I/O nhỏ và thời gian đọc lại.
Để lựa chọn kỹ thuật lưu trữ phù hợp, bạn cần cân nhắc các nhu cầu cụ thể của mình. Nếu bạn cần bảo vệ dữ liệu của mình khỏi mất mát, thì replication là một lựa chọn tốt. Nếu bạn cần cải thiện hiệu quả lưu trữ hoặc giảm chi phí, thì erasure code có thể là một lựa chọn tốt hơn.
3. Lên kế hoạch triển khai Ceph.
RAM
RAM là một trong những yếu tố quan trọng nhất đối với hiệu suất của một cụm Ceph. Ceph sử dụng RAM để lưu trữ các dữ liệu tạm thời, chẳng hạn như các bản sao dữ liệu, các bản ghi nhật ký và các chỉ mục.
Theo khuyến nghị của Ceph, mỗi OSD HDD cần có ít nhất 3GB RAM và mỗi OSD SSD cần có ít nhất 5GB RAM. Tuy nhiên, số lượng RAM thực tế cần thiết sẽ phụ thuộc vào các yếu tố sau:
- Số nhóm đặt chỗ (PG) trên mỗi OSD.
- Kích thước dữ liệu đang được lưu trữ.
- Loại hoạt động I/O (như đọc, ghi hoặc xóa).
Về cơ bản, càng có nhiều PG trên mỗi OSD thì cần càng nhiều RAM. PG là đơn vị cơ bản của dữ liệu trong Ceph. Mỗi đối tượng được lưu trữ trong một hoặc nhiều PG. Số lượng PG trên mỗi OSD được xác định bởi các tham số cấu hình của Ceph.
Kích thước dữ liệu cũng ảnh hưởng đến mức sử dụng RAM. Dữ liệu lớn hơn sẽ cần nhiều RAM hơn để lưu trữ.
Loại hoạt động I/O cũng ảnh hưởng đến mức sử dụng RAM. Các hoạt động I/O lớn hơn sẽ cần nhiều RAM hơn để xử lý.
Để đảm bảo rằng các OSD có đủ RAM, bạn nên đặt mục tiêu là 200 PG/OSD. Điều này sẽ giúp đảm bảo rằng các OSD sẽ có ít nhất 4GB RAM, ngay cả khi đang xử lý các hoạt động I/O lớn.
CPU
CPU cũng là một yếu tố quan trọng đối với hiệu suất của một cụm Ceph. Ceph sử dụng CPU để xử lý các hoạt động I/O, chẳng hạn như đọc, ghi và xóa.
Theo khuyến nghị của Ceph, mỗi OSD cần có ít nhất 1 GHz CPU. Tuy nhiên, số lượng CPU thực tế cần thiết sẽ phụ thuộc vào các yếu tố sau:
- Lượng I/O đang được xử lý.
- Kích thước I/O.
Càng có nhiều I/O đang được xử lý thì cần càng nhiều CPU. I/O lớn hơn cũng cần nhiều CPU hơn để xử lý.
Nếu CPU của các OSD không đủ, thì các OSD có thể bị lỗi thời và bị loại khỏi cụm. Điều này có thể dẫn đến mất dữ liệu hoặc suy giảm hiệu suất của cụm.
Disk
Ổ đĩa là nơi lưu trữ dữ liệu thực tế trong Ceph. Hiệu suất của ổ đĩa là một yếu tố quan trọng đối với hiệu suất tổng thể của cụm.
Theo khuyến nghị của Ceph, bạn nên tránh sử dụng các ổ HDD quá lớn. Các ổ HDD lớn hơn không nhất thiết sẽ cung cấp hiệu suất tốt hơn.
Các khuyến nghị về ổ đĩa cho Ceph như sau:
- 7.2k: 70-80 IOPS/4k (nhẹ)
- 10k: 120-150 IOPS/4k (trung bình)
- 15k: Dùng SSD cho nhu cầu cao
Thay vào đó, bạn nên tập trung vào việc sử dụng các ổ HDD có tốc độ vòng quay cao (7.2k hoặc 10k) và IOPS cao.
Nếu bạn cần hiệu suất cao nhất, bạn nên sử dụng SSD. SSD có IOPS cao hơn nhiều so với HDD và có thể cung cấp hiệu suất tốt hơn đáng kể cho các ứng dụng đòi hỏi nhiều I/O.
Các mẹo khác
Ngoài các mẹo về RAM, CPU và ổ đĩa, bạn cũng nên lưu ý đến các yếu tố sau khi lên kế hoạch triển khai Ceph:
- Network: Ceph sử dụng mạng để truyền dữ liệu giữa các OSD. Bạn nên sử dụng network riêng, băng thông cao (10GbE trở lên) cho cụm Ceph.
- Monitoring: Bạn nên theo dõi sức khỏe và hiệu suất của các OSD liên tục. Điều này sẽ giúp bạn phát hiện và khắc phục các vấn đề tiềm ẩn.
- Điều chỉnh: Bạn có thể tinh chỉnh cấu hình Ceph để phù hợp với nhu cầu và phần cứng cụ thể của mình.
- Kiểm tra: Bạn nên kiểm tra kỹ lưỡng cụm Ceph trước khi triển khai trong thực tế. Điều này sẽ giúp bạn đảm bảo rằng cụm hoạt động bình thường.
Dưới đây là bản tóm tắt các điểm chính để thiết kế cụm Ceph thành công, tập trung vào các hoạt động thường xuyên, không phải lưu trữ số lượng lớn dữ liệu không hoạt động:
Ưu tiên hiệu suất (IOPS) hơn dung lượng:
- Chọn nhiều ổ đĩa nhỏ hơn thay vì ít ổ đĩa lớn.
- Sử dụng mạng 10 Gb tối thiểu.
Chọn phần cứng phù hợp:
- Nghiên cứu và thử nghiệm kỹ lưỡng trước khi sử dụng.
- Tránh sử dụng ổ SSD thông thường (ví dụ SSD dành cho laptop, PC) trong môi trường sản xuất.
- Không dùng bộ điều khiển RAID ở chế độ Write-Back mà không có bảo vệ bằng pin
(Chế độ Write-Back là một cấu hình RAID trong đó dữ liệu được ghi vào bộ nhớ đệm trước khi được ghi vào ổ đĩa vật lý. Điều này có thể cải thiện hiệu suất ghi).
Không sử dụng tùy chọn “no barrier mount” với Filestore.
Filestore là một dịch vụ lưu trữ file qua network (NFS). Tùy chọn “no barrier mount” cho phép các ứng dụng ghi dữ liệu trực tiếp vào ổ đĩa mà không cần đợi các hoạt động I/O trước đó được hoàn thành. Điều này có thể cải thiện hiệu suất cho các ứng dụng có khối lượng I/O cao, nhưng nó cũng có thể dẫn đến mất dữ liệu nếu ứng dụng bị lỗi đột ngột.
Với Filestore, tùy chọn “no barrier mount” không được khuyến nghị sử dụng trong môi trường sản xuất. Lý do là Filestore sử dụng các giao thức đồng bộ hóa để đảm bảo dữ liệu được ghi đồng thời vào tất cả các ổ đĩa trong nhóm. Nếu bạn sử dụng tùy chọn “no barrier mount”, các giao thức này sẽ không được kích hoạt và dữ liệu có thể bị mất nếu ứng dụng bị lỗi.
Để tránh mất dữ liệu, bạn nên sử dụng tùy chọn “barrier mount” với Filestore. Tùy chọn này sẽ đảm bảo rằng dữ liệu được ghi đồng thời vào tất cả các ổ đĩa trước khi được trả về cho ứng dụng.
Dưới đây là một số ví dụ về các ứng dụng có thể gặp phải vấn đề nếu sử dụng tùy chọn “no barrier mount” với Filestore:
- Các ứng dụng xử lý dữ liệu thời gian thực, chẳng hạn như hệ thống giám sát và hệ thống phân tích.
- Các ứng dụng tạo bản sao lưu dữ liệu, chẳng hạn như máy chủ sao lưu và các ứng dụng lưu trữ đám mây.
- Các ứng dụng có thể bị lỗi đột ngột, chẳng hạn như ứng dụng do người dùng viết.
Để hủy no barrier mount, bạn cần thay đổi tùy chọn mount_options trong file fstab. Ví dụ trên Ubuntu, bạn có thể sử dụng lệnh sau để thay đổi tùy chọn mount_options:
sudo nano /etc/fstabTìm và thay đổi tùy chọn mount_options thành “barrier=on”. Ví dụ:
//cephfs/my-filestore /mnt/cephfs ext4 defaults,_netdev,noatime,nobarrier,ceph.filestore.quota.enable=true 0 0Thay đổi tùy chọn thành “barrier=on” sau đó lưu file và khởi động lại hệ thống của bạn.
Sau khi khởi động lại, Ceph sẽ được gắn với tùy chọn barrier=on. Điều này sẽ đảm bảo rằng dữ liệu được ghi đồng thời vào tất cả các ổ đĩa trong nhóm.
Để kiểm tra xem tùy chọn barrier đã được bật hay chưa, bạn có thể sử dụng lệnh sau:
mount -lTìm và kiểm tra xem tùy chọn mount_options có bao gồm “barrier=on” hay không.
Tránh cấu hình pool có kích thước 2 hoặc min_size 1.
Một nhóm (pool) trong Ceph là một tập hợp các ổ đĩa được sử dụng để lưu trữ dữ liệu. Kích thước của một nhóm là số lượng ổ đĩa tối thiểu cần thiết để nhóm hoạt động bình thường.
Với cấu hình nhóm có kích thước 2 hoặc min_size 1, một nhóm chỉ cần có 2 ổ đĩa hoạt động để hoạt động bình thường. Điều này có nghĩa là nếu một ổ đĩa trong nhóm bị lỗi, nhóm sẽ vẫn hoạt động, nhưng sẽ chỉ còn lại 1 ổ đĩa hoạt động.
Tình trạng này có thể gây ra các vấn đề sau:
- Thiếu khả năng phục hồi: Nếu ổ đĩa hoạt động còn lại bị lỗi, tất cả dữ liệu trong nhóm sẽ bị mất.
- Giảm hiệu suất: Khi nhóm chỉ có 1 ổ đĩa hoạt động, hiệu suất của nhóm sẽ giảm đáng kể.
Để tránh các vấn đề này, bạn nên tránh cấu hình nhóm có kích thước 2 hoặc min_size 1. Thay vào đó, bạn nên sử dụng kích thước nhóm tối thiểu là 3 hoặc min_size 2.
Với cấu hình này, nhóm sẽ có ít nhất 3 ổ đĩa hoạt động, ngay cả khi một ổ đĩa bị lỗi. Điều này sẽ giúp đảm bảo khả năng phục hồi và hiệu suất của nhóm.
Dưới đây là một số ví dụ về các ứng dụng mà bạn nên tránh sử dụng cấu hình nhóm có kích thước 2 hoặc min_size 1:
- Các ứng dụng yêu cầu khả năng phục hồi cao, chẳng hạn như các ứng dụng lưu trữ dữ liệu quan trọng.
- Các ứng dụng có khối lượng I/O cao, chẳng hạn như các ứng dụng xử lý dữ liệu thời gian thực.
Nếu bạn không chắc chắn liệu ứng dụng của mình có cần khả năng phục hồi cao hay không, bạn nên tham khảo tài liệu của nhà cung cấp ứng dụng.
Không thay đổi tùy chọn cấu hình nếu không hiểu rõ.
Bạn không nên thay đổi tùy chọn cấu hình nếu bạn không hiểu rõ tác động của chúng. Các tùy chọn cấu hình Ceph có thể ảnh hưởng đến hiệu suất, khả năng phục hồi và tính bảo mật của cụm của bạn.
Trước khi thay đổi bất kỳ tùy chọn cấu hình nào, bạn nên dành thời gian để nghiên cứu và hiểu tác động của chúng. Bạn có thể tìm hiểu thông tin về các tùy chọn cấu hình Ceph trong tài liệu chính thức của Ceph.
Dưới đây là một số ví dụ về các tùy chọn cấu hình Ceph có thể ảnh hưởng đến hiệu suất, khả năng phục hồi và tính bảo mật của cụm:
- Kích thước nhóm: Kích thước nhóm xác định số lượng ổ đĩa tối thiểu cần thiết để nhóm hoạt động bình thường. Kích thước nhóm lớn hơn sẽ cải thiện khả năng phục hồi nhưng có thể làm giảm hiệu suất.
- Cơ chế đồng bộ hóa: Cơ chế đồng bộ hóa xác định cách dữ liệu được đồng bộ hóa giữa các ổ đĩa trong nhóm. Cơ chế đồng bộ hóa có hiệu quả hơn sẽ cải thiện hiệu suất nhưng có thể làm giảm khả năng phục hồi.
- Chế độ ghi: Chế độ ghi xác định cách dữ liệu được ghi vào ổ đĩa. Chế độ ghi nhiều lần sẽ cải thiện khả năng phục hồi nhưng có thể làm giảm hiệu suất.
Nếu bạn không chắc chắn liệu thay đổi tùy chọn cấu hình có ảnh hưởng đến cụm của mình như thế nào, bạn nên tham khảo ý kiến của chuyên gia.
Ceph Block Devices và Object Storage không cần MDS.
MDS là một thành phần trong Ceph File System (CephFS) được sử dụng để lưu trữ và quản lý metadata của File System. Metadata bao gồm thông tin như tên file, quyền sở hữu file và thời gian sửa đổi file.
Ceph Block Devices và Object Storage không sử dụng hệ thống file truyền thống và do đó không cần MDS. Chúng sử dụng các phương thức lưu trữ dữ liệu khác nhau.
Ceph Block Devices cung cấp các khối lưu trữ thô (raw storage blocks) cho các máy chủ. Các khối này được sử dụng để tạo các hệ thống file như ext4 hoặc xfs. Hệ thống file này sẽ chịu trách nhiệm quản lý metadata của riêng nó, không cần MDS.
Ceph Object Storage lưu trữ dữ liệu dưới dạng các đối tượng (objects). Mỗi đối tượng có một định danh duy nhất (ID) và một tập hợp các thuộc tính (metadata) được lưu trữ cùng với đối tượng đó. Ceph Object Storage không cần MDS vì nó lưu trữ metadata cùng với dữ liệu trong mỗi đối tượng.
Đảm bảo an toàn và sẵn sàng.
- Thực hiện thử nghiệm mất điện.
- Có kế hoạch sao lưu và khôi phục dữ liệu thống nhất.
- Sử dụng tối thiểu 3 monitor, 2 manager và 3 OSD để dự phòng và HA Availability.


{kind=link}