
Phần này mình sẽ hướng dẫn các bạn dùng bash script để đẩy metric lên Prometheus thông qua Pushgateway. Pushgateway nó như 1 bộ nhớ tạm để chứa các metric và các metric này sẽ được Prometheus pull về định kỳ. Cụ thể mình sẽ hướng dẫn các bạn viết 1 đoạn script nhỏ để lấy thông tin CPU và Memory thông qua top của hệ thống, sau khi đẩy được metric lên Prometheus mình cũng sẽ hướng dẫn các bạn tạo 1 dashboard để chúng ta có 1 cái nhìn trực quan hơn.
1. Triển khai Prometheus
Hãy tạo thư mục lưu file config của Promtheus.
mkdir /home/prometheusTiếp theo bạn hãy tạo file config Promtheus /home/prometheus/prometheus.yml với nội dung như dưới. Chúng ta sẽ có 2 job prometheus và jenkins, với 192.168.13.205:8080 là ip address của jenkins và 8080 là port của nó.
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: [192.168.13.205:9090]
- job_name: 'jenkins'
metrics_path: /prometheus
static_configs:
- targets: [192.168.13.205:9091]Sau khi hoàn thành tạo các thu mục và file, bạn sẽ có cây thư mục như dưới.
.
├── prometheus
└── prometheus.ymlChúng ta chạy lệnh dưới để triển khai Prometheus, nhớ mount file config prometheus.yml vào container.
docker run -d -u root --name prometheus -p 9090:9090 -v /home/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheusKết quả sau khi khởi tạo xong chúng ta có kết quả, ở đây mình có thêm container gitlab được triển khai chung host với prometheus.
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
03c5619941de prom/prometheus "/bin/prometheus --c…" 49 seconds ago Up 47 seconds 0.0.0.0:9090->9090/tcp, :::9090->9090/tcp prometheusDo chưa triển khai Pushgateway nên trạng thái target của nó sẽ báo down.
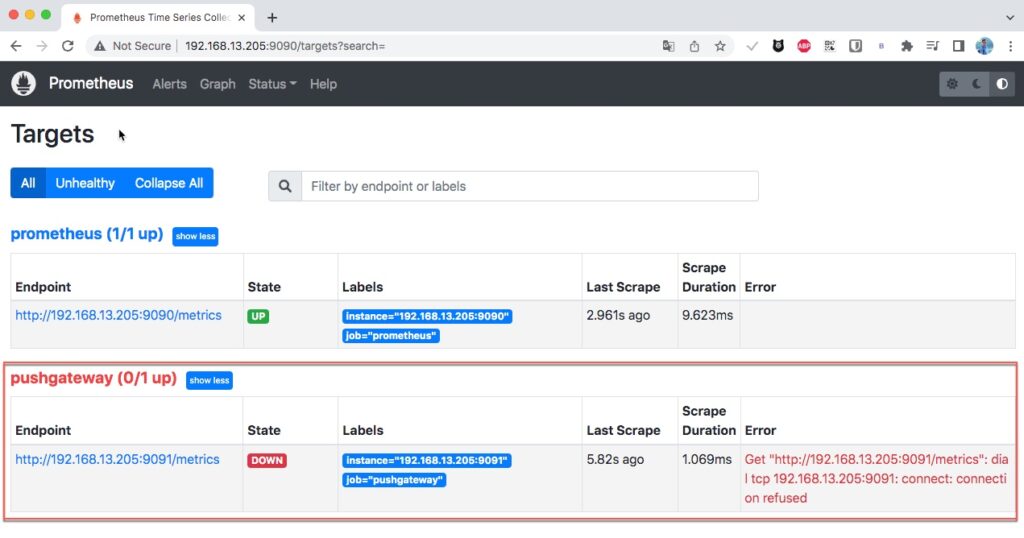
2. Triển khai Pushgateway
Chạy lệnh Docker Run để triển khai Pushgateway.
docker run -d -u root --name pushgateway -p 9091:9091 prom/pushgatewayXác nhận Pushgateway đã thực sự chạy thành công.
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8fa3517c6eab prom/pushgateway "/bin/pushgateway" 15 seconds ago Up 14 seconds 0.0.0.0:9091->9091/tcp, :::9091->9091/tcp pushgateway
03c5619941de prom/prometheus "/bin/prometheus --c…" 6 hours ago Up 2 minutes 0.0.0.0:9090->9090/tcp, :::9090->9090/tcp prometheusKết quả trong targets.
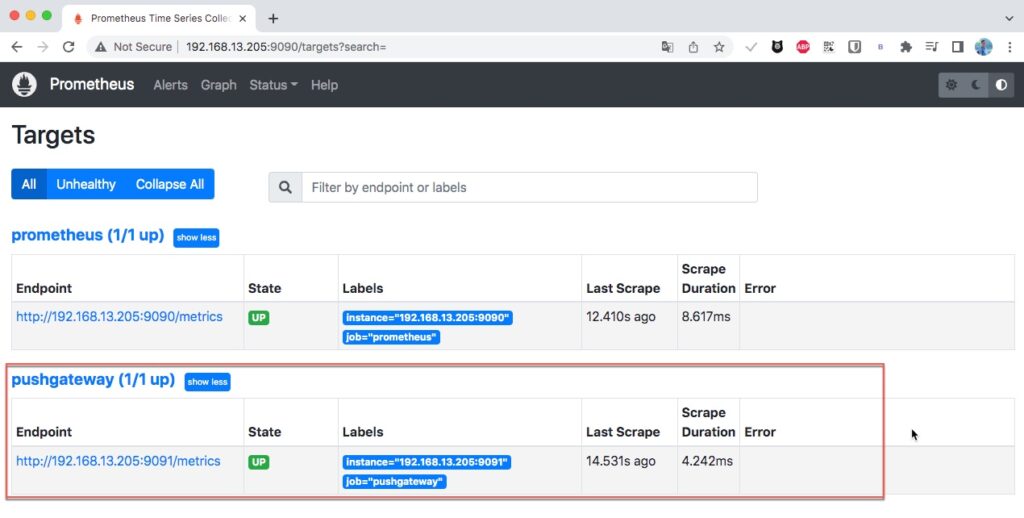
Chúng ta cũng có thể sử dụng trình duyệt để login vào Pushgateway theo url http://<pushgateway_ipaddr>:9091
3. Triển khai Grafana
Bước tiếp theo chúng ta triển khai Grafana để đưa thông tin metric đã lấy được từ Jenkins lên dashboard.
Hãy chạy lệnh dưới để tạo 1 container Grafana.
docker run -d -u root --name grafana -p 3000:3000 grafana/grafanaXác nhận Grafana đã triển khai thành công.
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8fa3517c6eab prom/pushgateway "/bin/pushgateway" 15 seconds ago Up 14 seconds 0.0.0.0:9091->9091/tcp, :::9091->9091/tcp pushgateway
744c9ab6dc1d grafana/grafana "/run.sh" 6 minutes ago Up 6 minutes 0.0.0.0:3000->3000/tcp, :::3000->3000/tcp grafana
03c5619941de prom/prometheus "/bin/prometheus --c…" 2 minutes ago Up 2 minutes 0.0.0.0:9090->9090/tcp, :::9090->9090/tcp prometheusDùng trình duyệt login vào url theo cú pháp http://<grafana_ipaddr>:3000
http://192.168.13.205:3000/Bạn sẽ có kết quả như dưới, hãy thực hiện tiếp các bước như hình để chúng ta thêm data source của Prometheus.
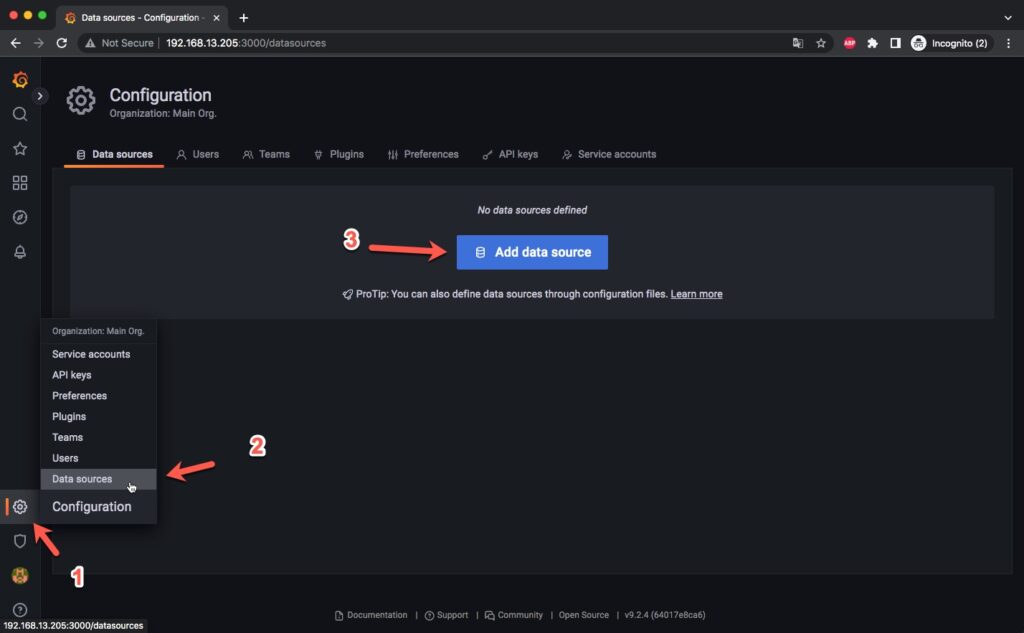
Chọn data source là Prometheus
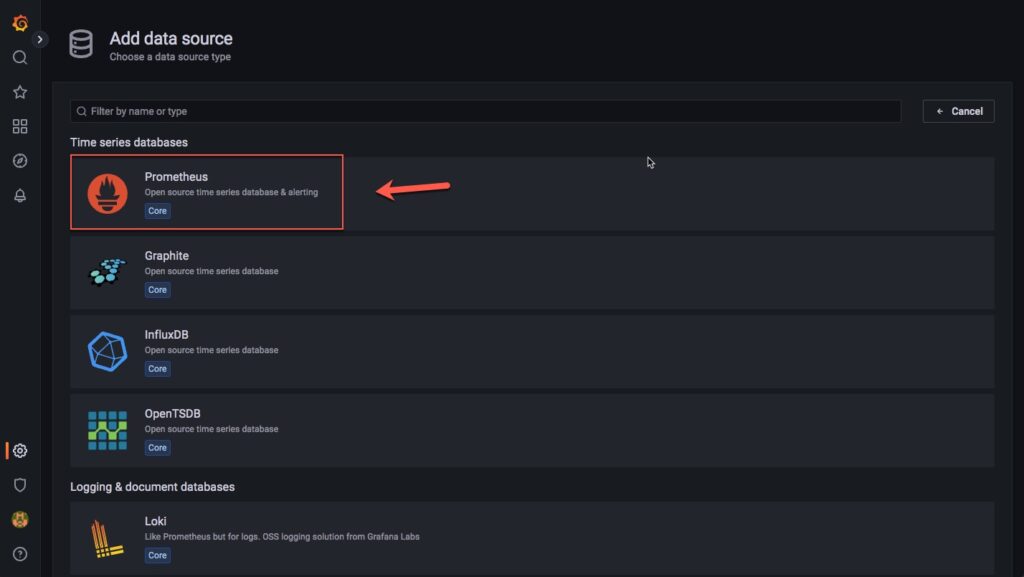
Tại mục name bạn hãy đặt tên bất kỳ cho nó, tại URL bạn điền url console của Prometheus.
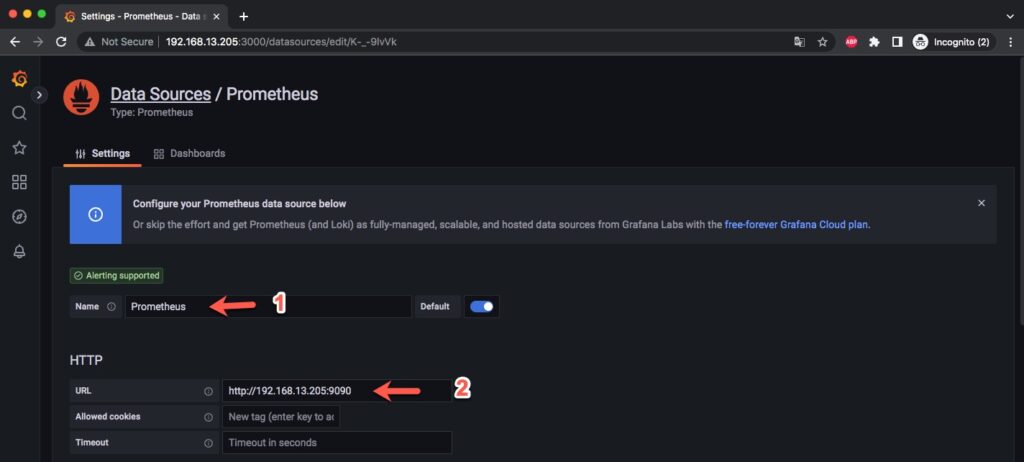
Sau khi hoàn thành 2 bước trên hãy kéo xuống dưới cùng và bấm Save & test. Nếu kết quả trả về Data source is working có nghĩ là data source đã được thêm thành công.
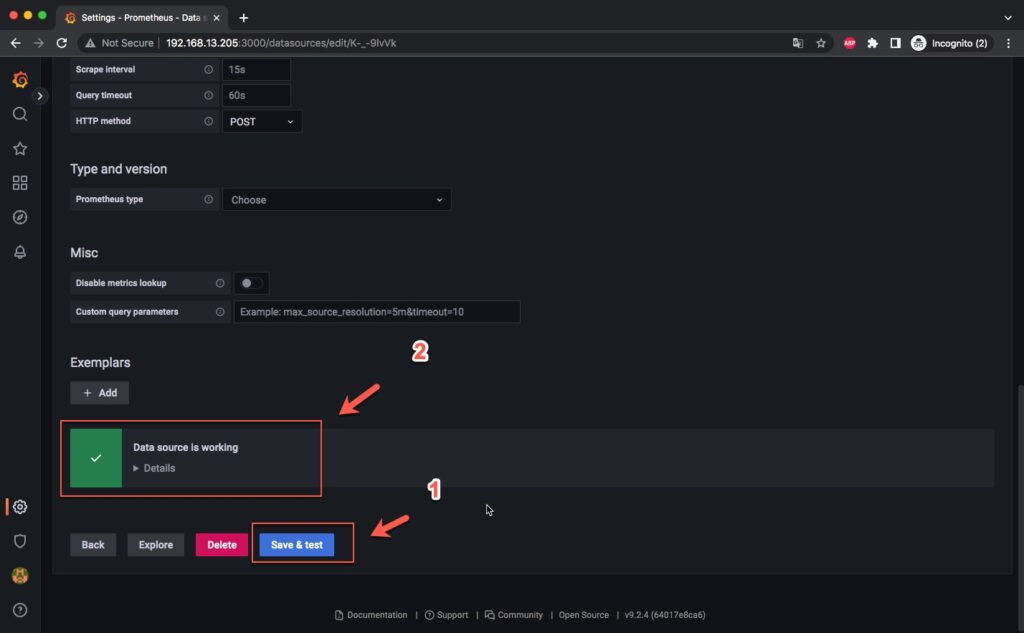
Sau khi thêm xong bạn sẽ có 1 data source Prometheus như dưới.
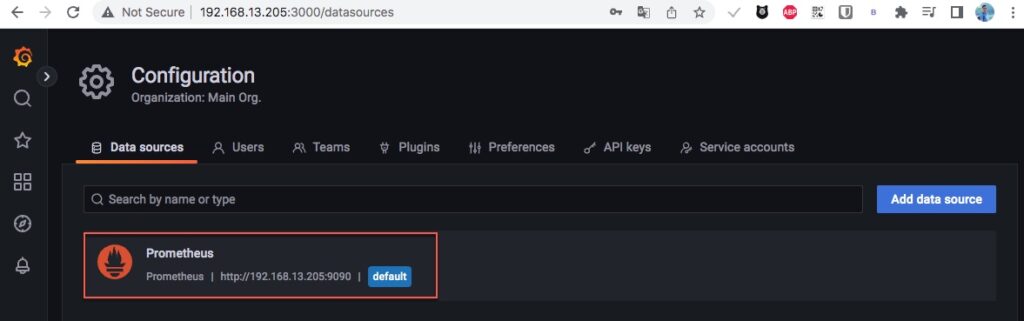
4. Viết script lấy metric
– Lấy thông tin cho CPU
Mình sẽ tạo 1 file có tên better-top và phân quyền thực thi cho nó.
touch better-top
chmod u+x better-top
vi better-topFile better-top sẽ có nội dung như dưới.
#!/bin/bash
z=$(ps aux)
while read -r z
do
var=$var$(awk '{print "cpu_usage{process=\""$11"\", pid=\""$2"\"}", $3z}');
done <<< "$z"
curl -X POST -H "Content-Type: text/plain" --data "$var
" http://192.168.13.205:9091/metrics/job/top/instance/machineGiờ mình sẽ chạy file better-top cứ 1 giây lặp lại 1 lần để lấy metric.
while sleep 1; do ./better-top; done;– Lấy thông tin cho Memory
Tạo file có tên memory-top-script và phân quyền thực thi cho nó.
touch memory-top-script
chmod u+x memory-top-script
vi memory-top-scriptFile memory-top-script sẽ có nội dung như dưới.
#!/bin/bash
z=$(ps aux)
while read -r z
do
var=$var$(awk '{print "memory_usage{process=\""$11"\", pid=\""$2"\"}", $4z}');
done <<< "$z"
curl -X POST -H "Content-Type: text/plain" --data "$var
" http://192.168.13.205:9091/metrics/job/top/instance/machineGiờ mình sẽ chạy file better-top cứ 1 giây lặp lại 1 lần để lấy metric
while sleep 1; do ./memory-top-script; done;Kết quả trên trang console của Pushgateway
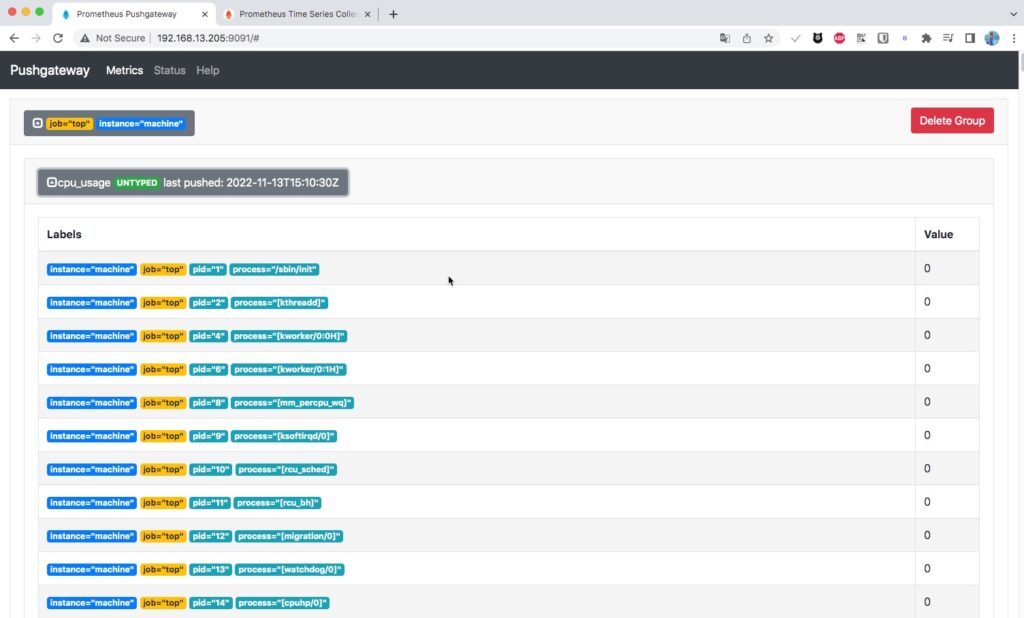
Đây là kết quả khi show metric trên Prometheus.
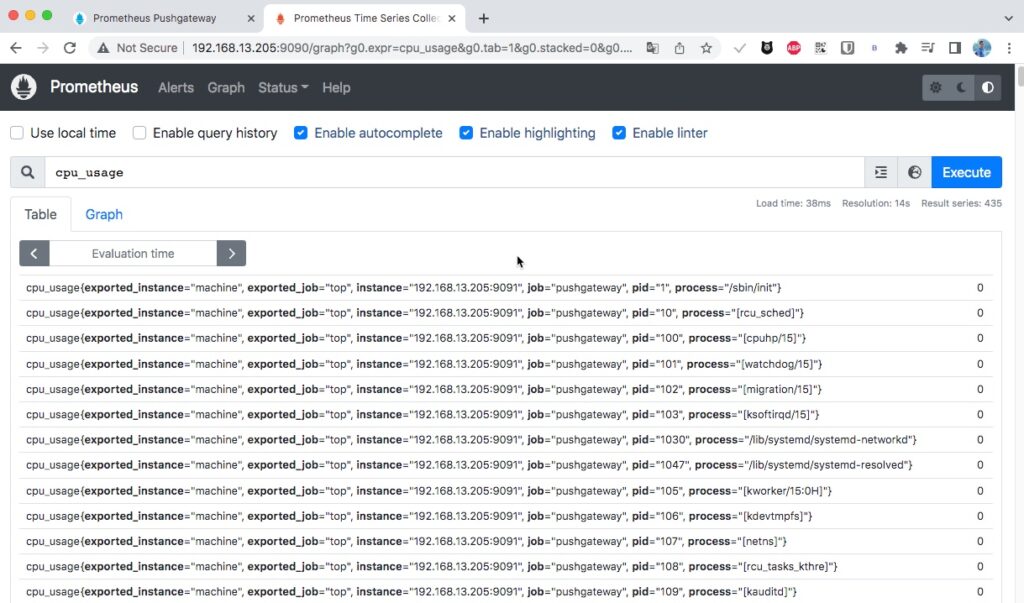
5. Đưa kết quả lên Grafana
Đầu tiên hãy tạo 1 dashboard mới.
Tiếp theo hãy tạo 1 panel mới
Chọn virtualization là Gauge, thực hiện thứ tự như hình dưới, ở dòng metric hãy sửu dụng phép tính sum(cpu_usage) để tính tổng phần trăm CPU đã được sử dụng.
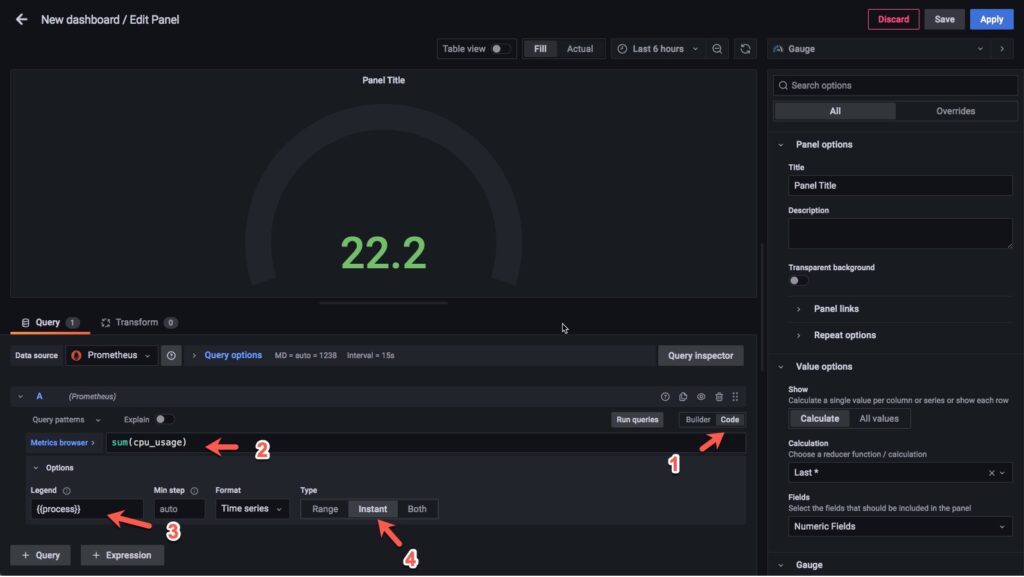
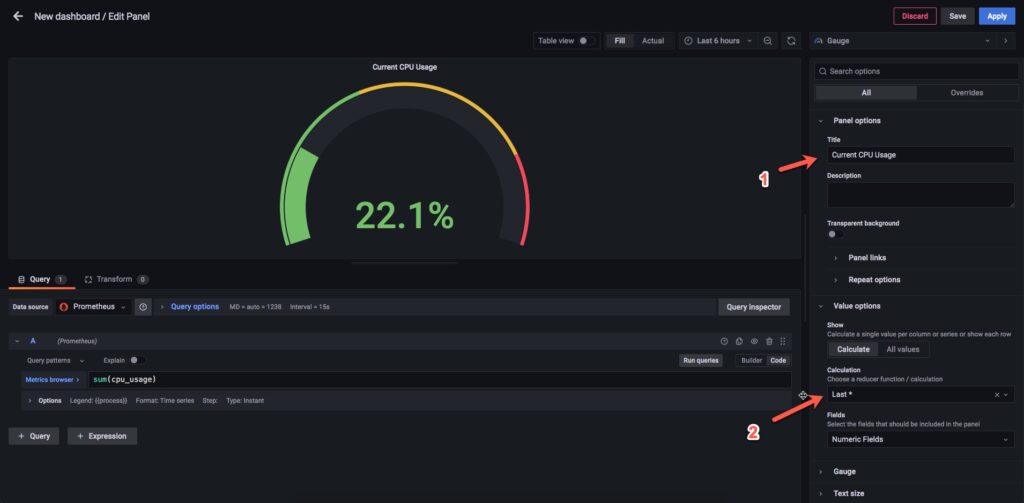
Đặt tên cho panel ở mục 1 và mở mục 2 hãy chọn last * để nếu grafana không lấy được giá trị gần nhất thì nó sẽ lấy giá trị cuối cùng để hiện lên dashboard
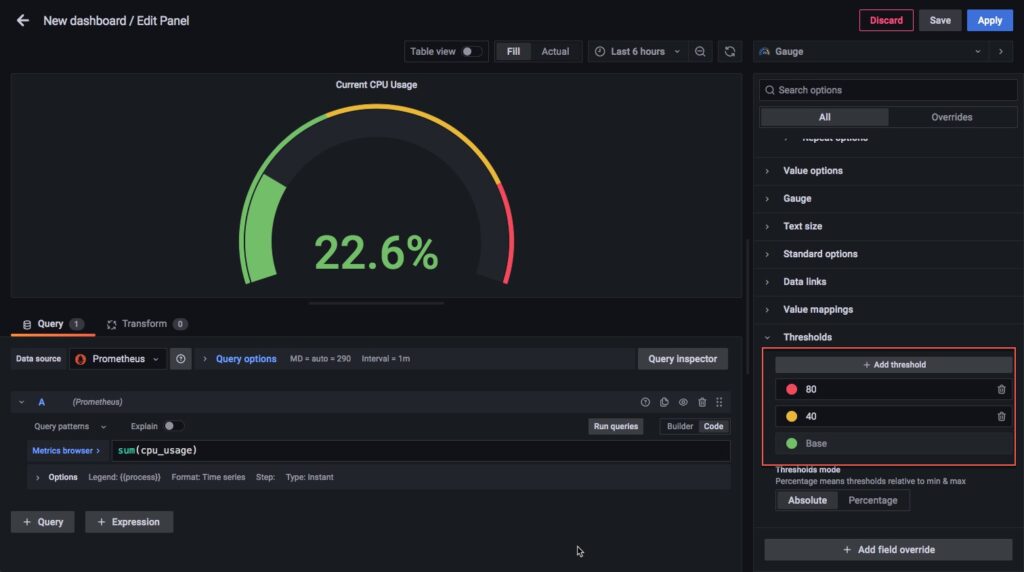
Set ngưỡng cảnh bảo ở đây nhé.
Phần này ta hiển thị phần trăm từ 0-100 như mục 1, 2. Sau khi setup thành công bạn sẽ có kết quả như ở mục 3.
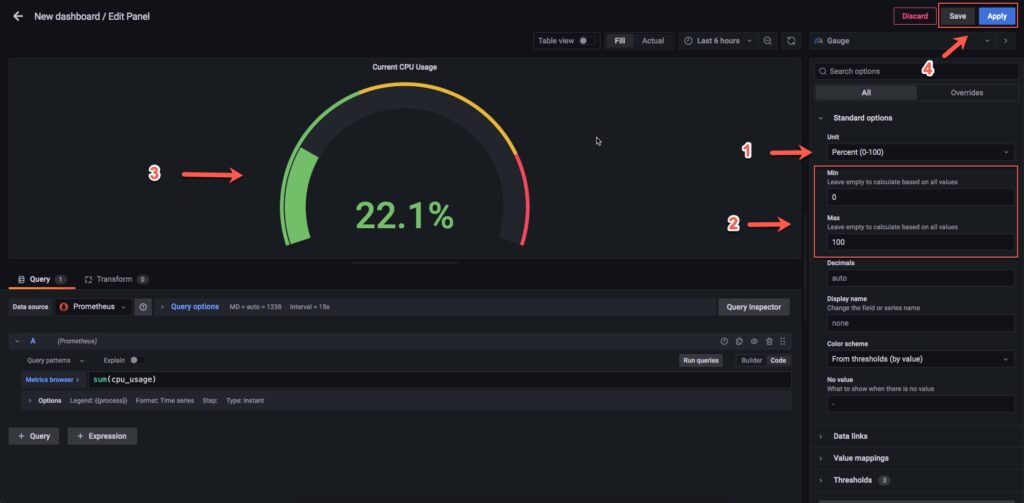
Kết quả sau khi bấm Apply và Save lại, bạn sẽ có 1 panel tên là Current CPU Usage như hình dưới.
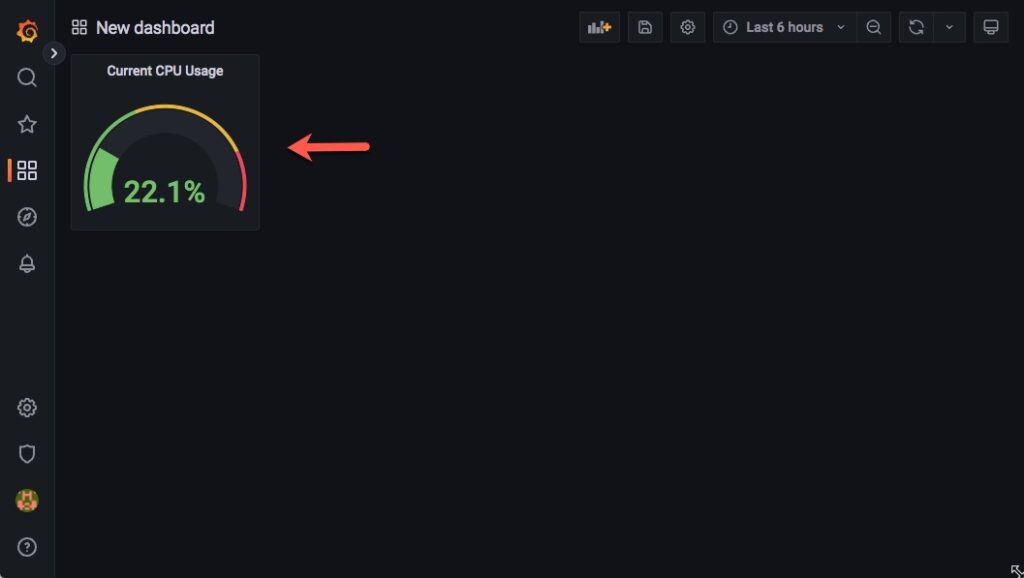
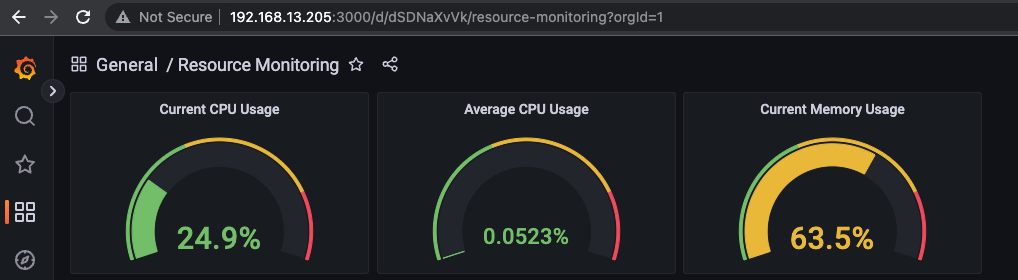
Áp dụng tương tự cho Average CPU Usage và Current Memory Usage ta được kết quả như sau.
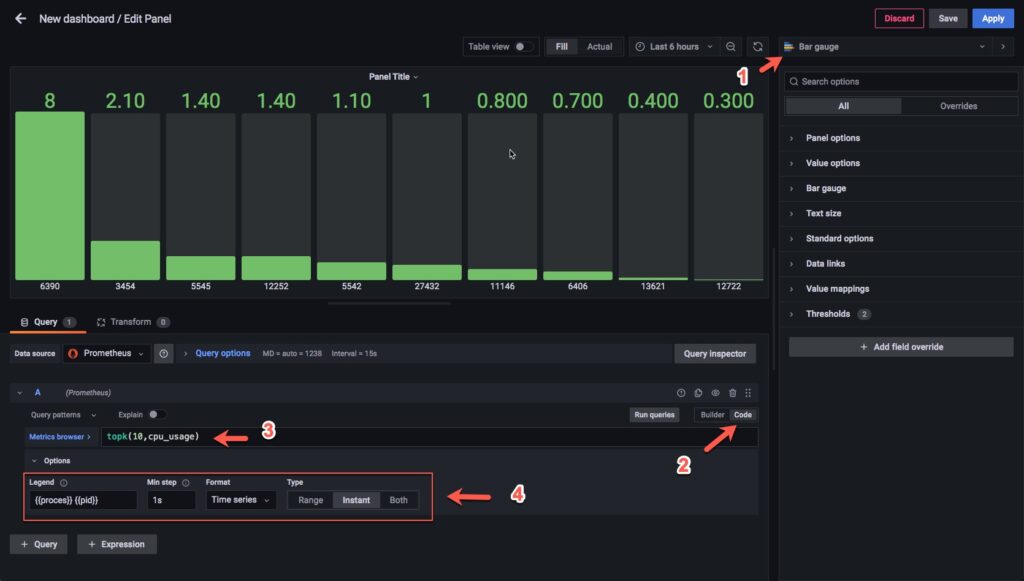
Tiếp theo mình sẽ tạo 1 panel mới để hiện thị top 10 services sử dụng CPU nhiều nhất, lần này mình sẽ lựa chọn virtualization là Bar gauge. Bạn hãy setup thứ tự như hình dưới nhé.
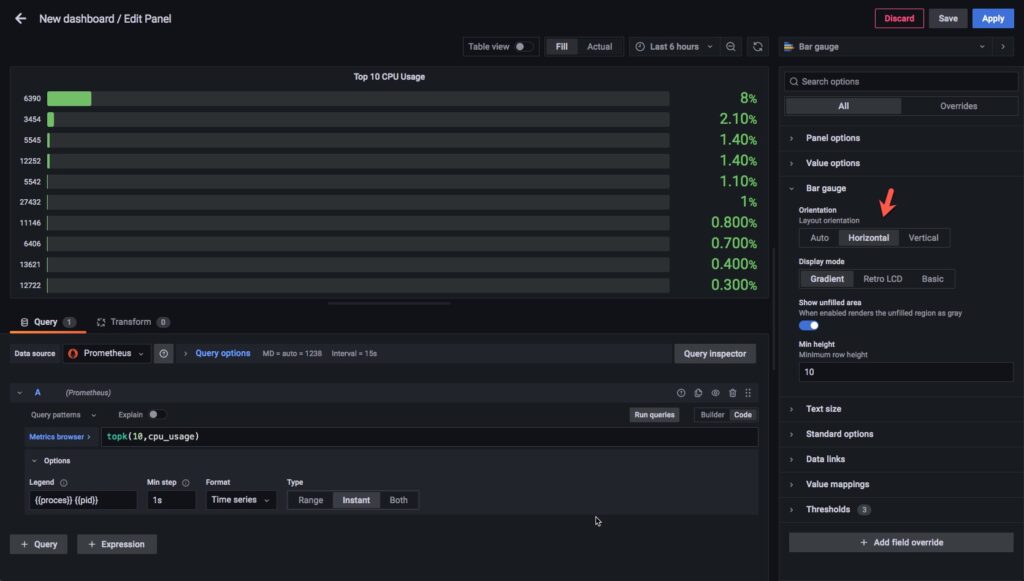
Mình sẽ chọn kiểu hiển thi là Horizontal.
Vẫn như phần trên mình sẽ lựa chọn kiểu hiện thị là phần trăm, nếu bạn có lựa chọn như mình thì hãy setup như hình dưới.
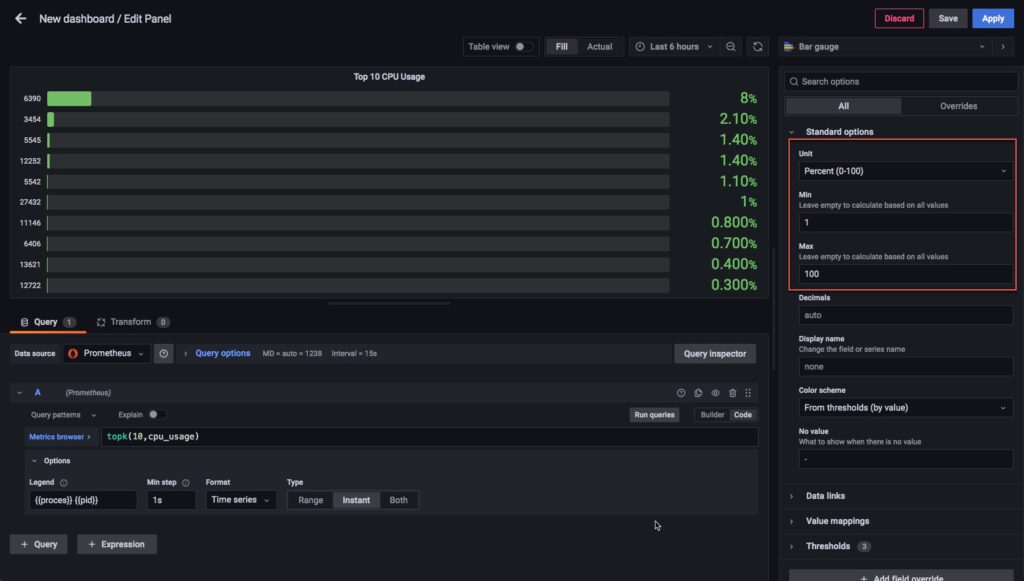
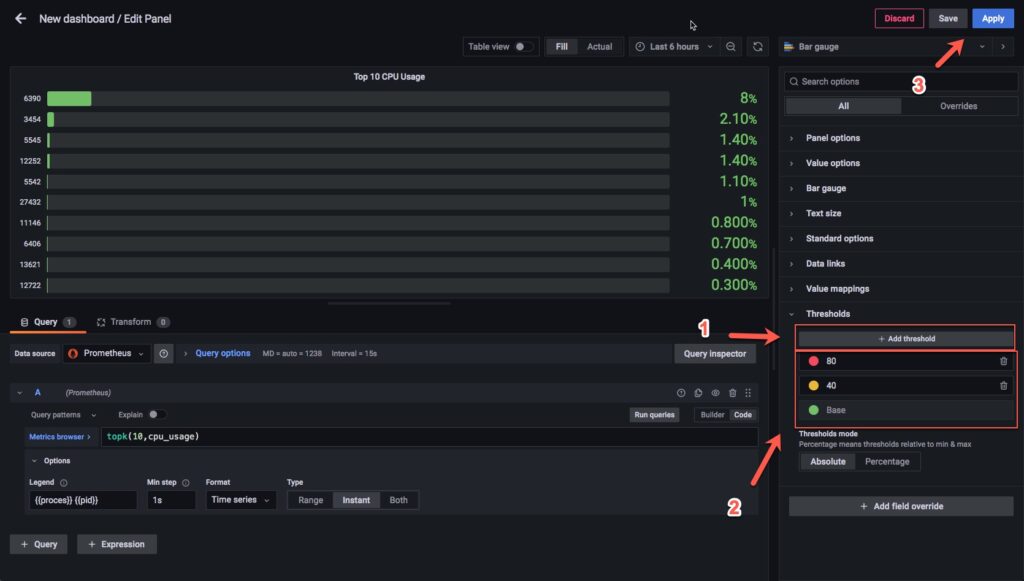
Phần này mình sẽ hiện cảnh báo khi có service sử dụng vượt ngưỡng.
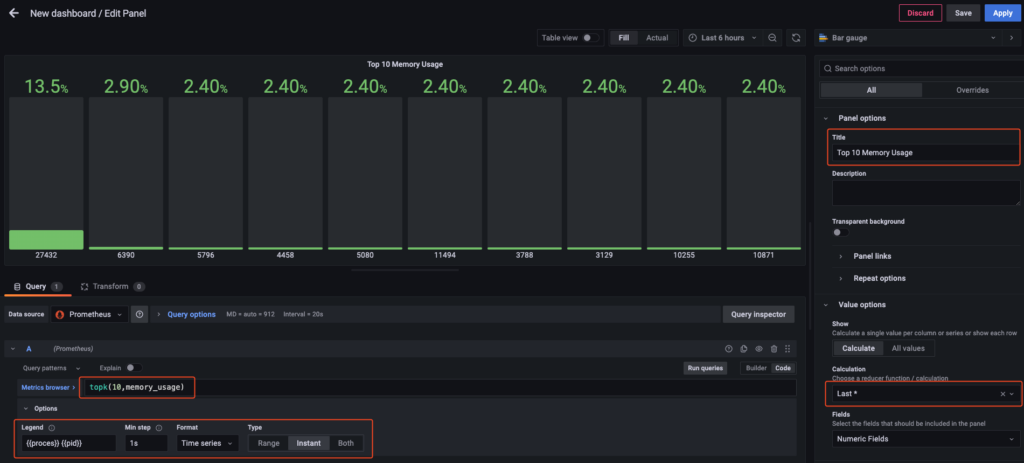
Áp dụng tương tự cho Memory, hãy setup theo hình dưới và nhớ chọn last * để nếu grafana không lấy được giá trị gần nhất thì nó sẽ lấy giá trị cuối cùng để hiện lên dashboard.
Phần này ta hiển thị phần trăm từ 0-100.
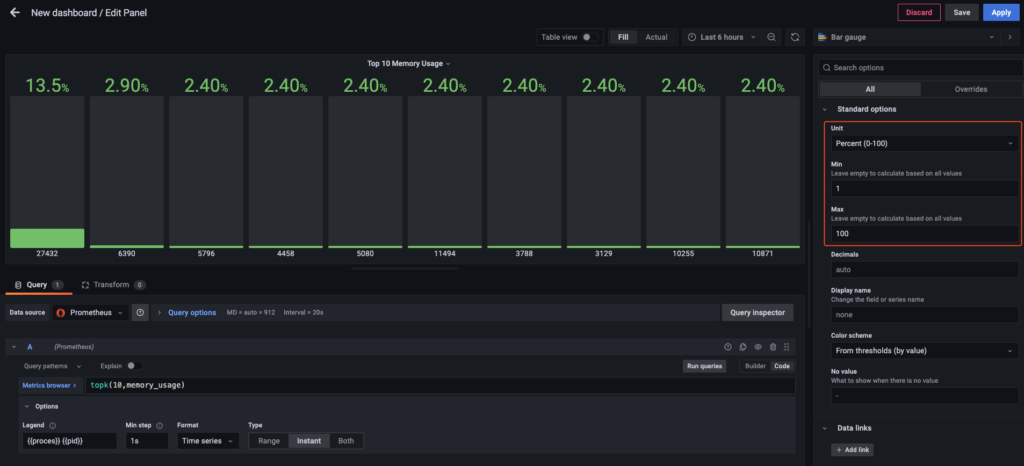
Và cuối cùng là cài đặt ngưỡng cảnh báo cho Memory.
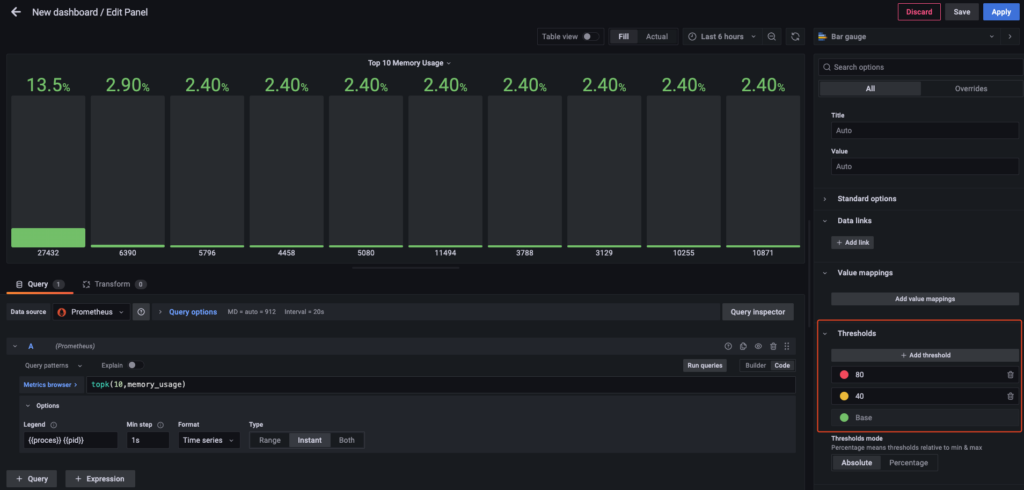
Và chúng ta có kết quả như dưới.
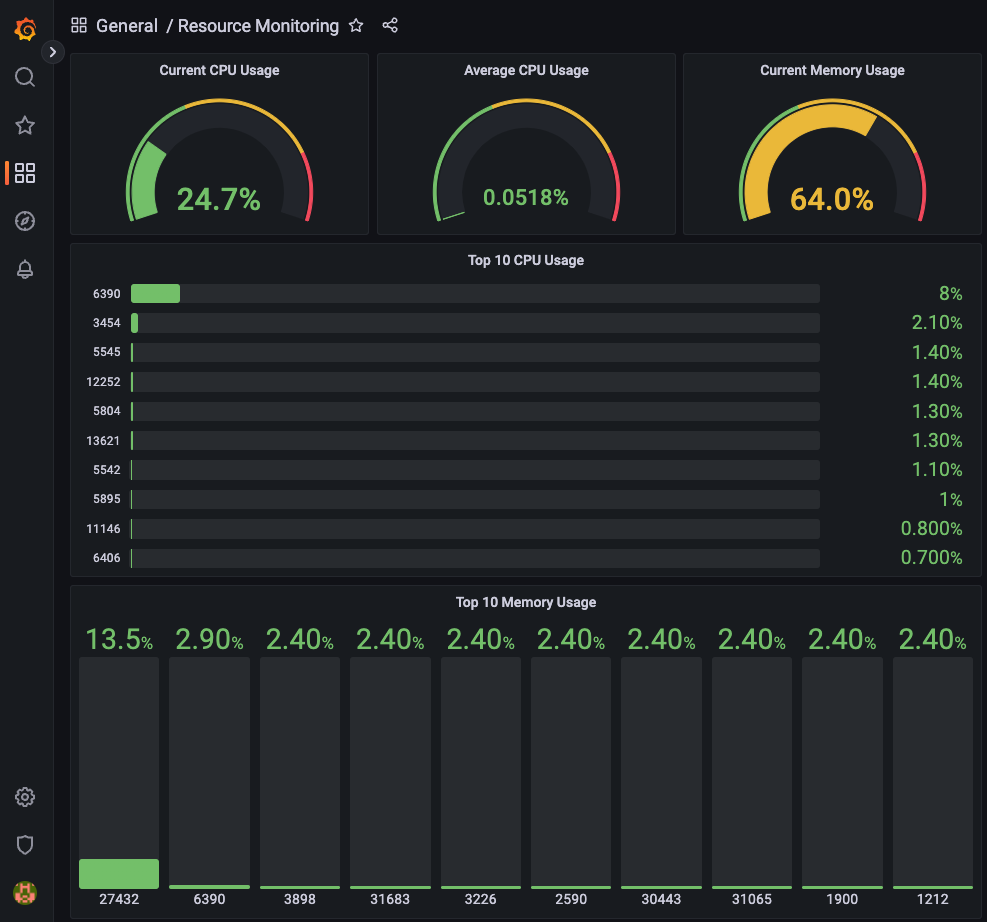
Tiếp theo nếu dashboard của bạn đang ít thì bạn có thể thiết kế thêm 1 virtualization Time series hiển thị top 10 CPU như sau.
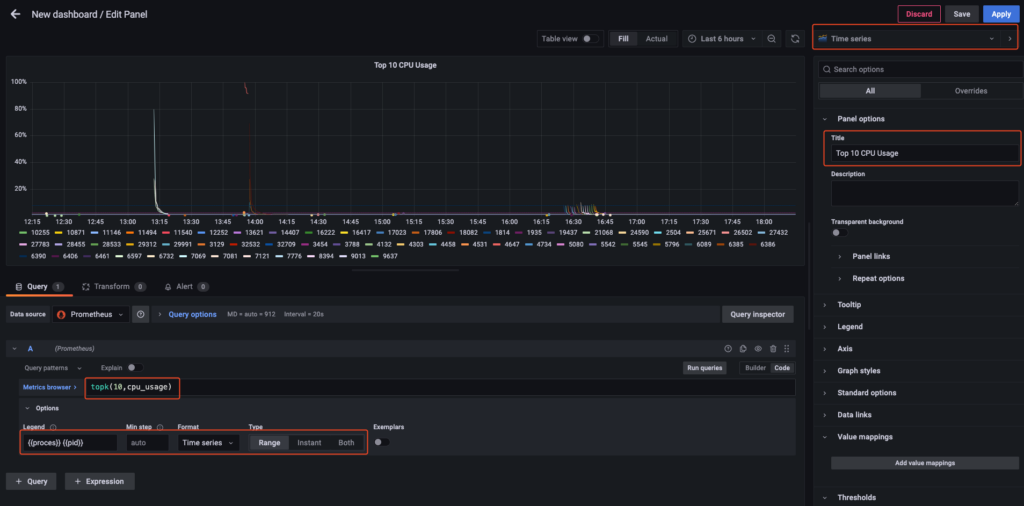
Phần này mình vẫn để hiển thị phần trăm từ 0-100.
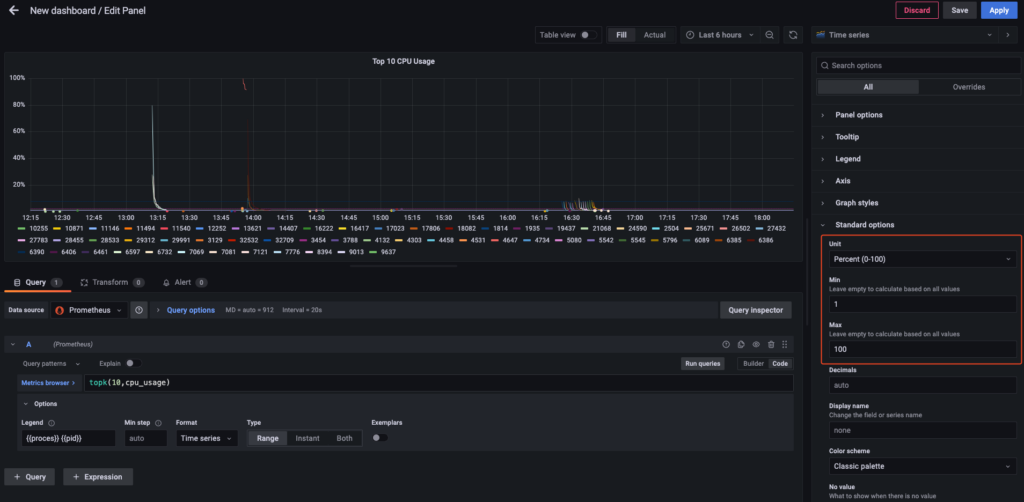
Cài đặt ngưỡng cảnh báo cho pannel mới.
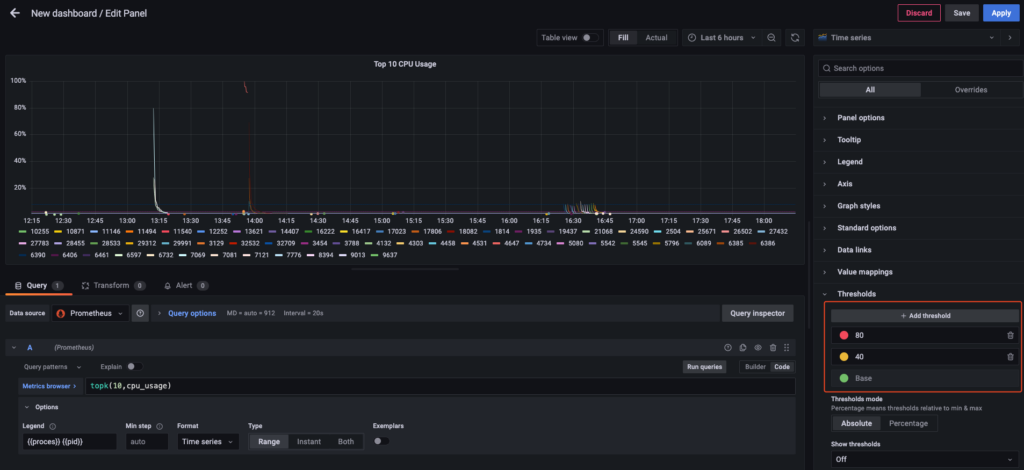
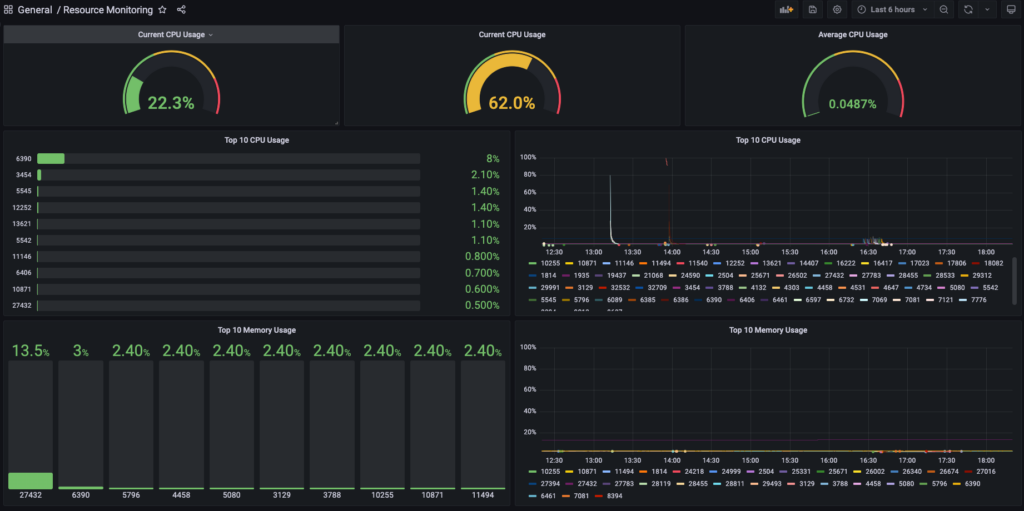
Làm tương tự cho phần Memory bạn sẽ có 1 dashboard hiển thị thông tin resource của CPU và Memory như dưới.
Và đây là kết quả khi mình thử test sử dụng CPU và Ram. Bạn có thể tham khảo 1 số cách test của mình ở phần dưới.
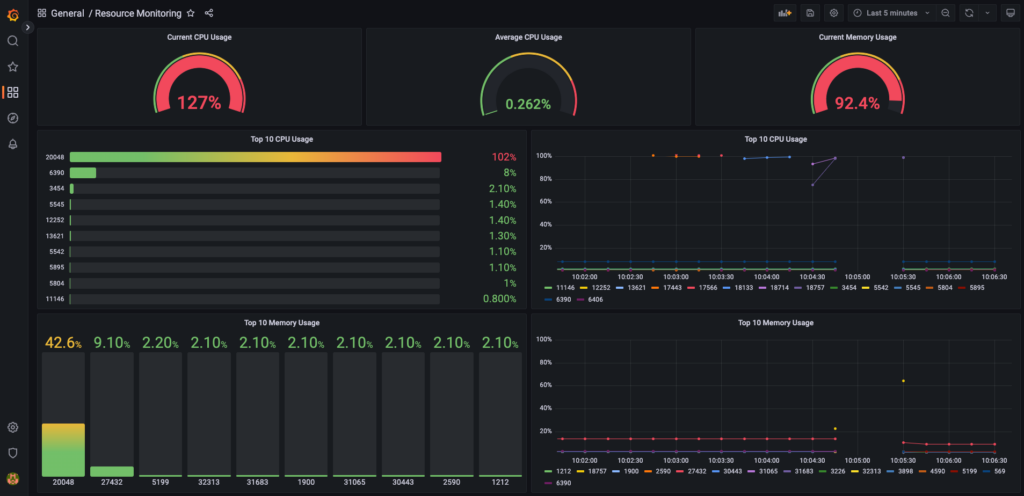
5. Cách test kết quả
– Test CPU
sha1sum /dev/zero $– Test memory
tail /dev/zero– Mình sẽ cài đặt Stress để test kết quả
sudo apt install stress -y - sử dụng CPU trong 15 giây và sử dụng 4 core
$ stress --cpu 4 --timeout 15
stress: info: [29562] dispatching hogs: 4 cpu, 0 io, 0 vm, 0 hdd
stress: info: [29562] successful run completed in 15s- Sử dụng I/O
$ stress --io 4
stress: info: [30329] dispatching hogs: 0 cpu, 4 io, 0 vm, 0 hdd- Sử dụng Memory
$ stress -m 7 --timeout 15
stress: info: [30757] dispatching hogs: 0 cpu, 0 io, 7 vm, 0 hdd
stress: info: [30757] successful run completed in 15s- Sử dụng số lượng Memory cụ thể
$ stress --vm 2 --vm-bytes 128M --vm-hang 10
stress: info: [31207] dispatching hogs: 0 cpu, 0 io, 2 vm, 0 hdd

{kind=link}