1. Tổng quan.
Trong môi trường cơ sở dữ liệu phân tán, Galera Cluster là một giải pháp phổ biến giúp triển khai cụm MySQL/MariaDB với khả năng sao chép đồng bộ, đảm bảo tính toàn vẹn của dữ liệu. Để cải thiện tính sẵn sàng và đảm bảo sự đồng thuận ngay cả khi một node bị ngắt kết nối, ta có thể thêm một Galera Arbitrator (Garbd) vào hệ thống. Bài viết này sẽ hướng dẫn từng bước thiết lập Galera Cluster với hai node chính và một node chạy Arbitrator, đảm bảo tính sẵn sàng cao cho cơ sở dữ liệu.
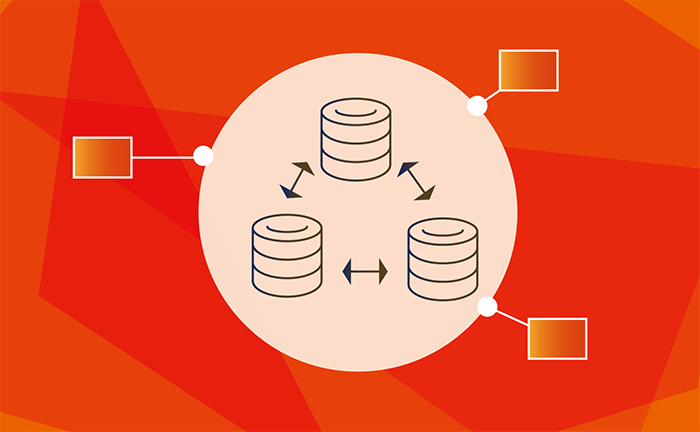
2. Galera Arbitrator (Garbd).
Galera Arbitrator (Garbd) là một node ảo trong Galera Cluster, nó không chứa dữ liệu nhưng đóng vai trò quan trọng trong quá trình bầu chọn và quản lý các node khác. Khi một node trong cụm gặp sự cố, Garbd sẽ giúp đảm bảo rằng cụm vẫn duy trì sự đồng thuận mà không cần sự tham gia của node bị mất. Việc cài đặt và cấu hình Garbd rất quan trọng trong việc duy trì tính sẵn sàng cao của cụm.
Trong trường hợp bạn chỉ có 2 node trong cluster Galera và không có node thứ 3 để chạy Garbd (Galera Arbitrator Daemon), bạn vẫn có thể triển khai Galera, nhưng có một số vấn đề bạn cần lưu ý:
Nguyên tắc Quorum (Majority Voting)
Galera Cluster sử dụng cơ chế quorum để đảm bảo tính đồng nhất của dữ liệu trong cluster. Với một cluster có 2 node, mỗi node có quyền biểu quyết và để đạt quorum, cần ít nhất hơn một nửa số node (quorum majority) đang hoạt động.
Nếu chỉ có 2 node mà một trong hai node gặp sự cố và không hoạt động, node còn lại sẽ không có đủ số phiếu để tiếp tục hoạt động và có thể khiến cluster ngừng hoạt động. Để giải quyết vấn đề này, thông thường cần có ít nhất 3 node (hoặc thêm Garbd làm node thứ 3 để giữ quorum).
Giải pháp cho Cluster 2 node.
Nếu bạn chỉ có 2 node và không thể thêm node thứ 3 hoặc Garbd, bạn có thể cân nhắc các giải pháp sau:
a) Sử dụng pc.weight.
Bạn có thể cấu hình Galera với 2 node và thiết lập cân nặng cho các node để tránh vấn đề mất quorum khi một node ngừng hoạt động. Bạn thêm cấu hình sau vào file cấu hình Galera:
[mysqld]
wsrep_provider_options="pc.weight=2"Điều này sẽ giúp node có weight lớn hơn và có thể duy trì hoạt động nếu node kia bị ngắt.
b) Chạy Cluster với 2 Node và chấp nhận rủi ro.
Nếu bạn chấp nhận rủi ro rằng hệ thống sẽ bị gián đoạn khi một trong hai node ngừng hoạt động, bạn vẫn có thể chạy cluster với 2 node mà không cần thêm Garbd. Tuy nhiên, trường hợp này không khuyến khích vì có thể dẫn đến tình trạng dừng hoạt động nếu có sự cố với một node.
c) Thêm Node Ảo (Virtual Node) hoặc Garbd trên máy ảo.
Bạn có thể tạo một máy ảo hoặc container nhỏ trên một trong hai node hiện có và chạy Garbd trên đó. Điều này sẽ giúp bạn có một “node thứ 3” để duy trì quorum mà không cần phần cứng riêng biệt.
Quản lý Split-Brain với 2 Node.
Một trong những rủi ro lớn nhất khi chạy cluster 2 node là hiện tượng split-brain (hai node nghĩ rằng mình là node chính). Điều này xảy ra khi kết nối giữa hai node bị ngắt, và mỗi node cố gắng hoạt động độc lập. Để giảm thiểu điều này:
- Cấu hình kỹ càng network giữa các node để tránh ngắt kết nối.
- Xem xét sử dụng các công cụ phát hiện và tự động khôi phục nếu mất kết nối, chẳng hạn như Corosync hoặc Pacemaker.
Như vậy tốt nhất bạn nên thêm một node thứ 3 (có thể là Garbd) để tránh rủi ro mất quorum.
Nếu không thể thêm node thứ 3, thì bạn cần cấu hình cẩn thận và chuẩn bị tinh thần cho việc ngừng hoạt động nếu có sự cố với một node.
3. Các mode triển khai.
Cách triển khai cluster với Galera Cluster và Garbd hiện tại sẽ sử dụng mode Active-Active (còn gọi là multi-master replication), không sử dụng Active-Backup.
Giải thích về các mode triển khai:
- Active-Active (multi-master replication):
- Tất cả các node trong cluster đều hoạt động đồng thời và có thể xử lý đọc/ghi dữ liệu.
- Mỗi node trong cluster có thể ghi và đọc dữ liệu từ cơ sở dữ liệu, và các thay đổi sẽ được đồng bộ hóa ngay lập tức giữa các node.
- Trong trường hợp triển khai Galera Cluster, các node chính của bạn (Node 1 và Node 2) đều tham gia vào việc xử lý yêu cầu (đọc và ghi). Điều này có nghĩa là bất kỳ node nào cũng có thể thực hiện các thao tác ghi và các thao tác đó sẽ được sao chép đến các node khác ngay lập tức.
- Active-Backup (chỉ nhắc thêm để nắm thêm phần lý thuyết, không áp dụng trong trường hợp ở bài lab này):
- Chỉ có một node (node chính) thực hiện xử lý các tác vụ đọc/ghi, còn các node khác chỉ hoạt động ở chế độ backup (chỉ đồng bộ dữ liệu và không tham gia xử lý yêu cầu).
- Trong trường hợp có sự cố ở node chính, một node backup mới sẽ trở thành active và bắt đầu xử lý các yêu cầu.
- Garbd không thực hiện theo mô hình Active-Backup vì nó chỉ là một thành phần hỗ trợ để duy trì quorum và không có khả năng xử lý dữ liệu.
4. Quy trình triển khai.
Trong bài viết này, chúng ta sẽ thiết lập một Galera Cluster gồm 2 node MariaDB và một node Garbd đóng vai trò làm Arbitrator.
4.1. Cài đặt Chrony và thiết lập múi giờ.
Việc đồng bộ thời gian giữa các node là rất quan trọng. Chúng ta sẽ sử dụng Chrony để đảm bảo thời gian trên các node luôn đồng nhất.
Cài đặt múi giờ.
timedatectl set-timezone Asia/Ho_Chi_MinhCài đặt Chrony.
apt update
apt install chrony -yThay đổi nội dung file /etc/chrony/chrony.conf với nội dung dưới, 10.237.7.250 là NTP Server.
echo 'server 10.237.7.250 iburst' > /etc/chrony/chrony.confKhởi động và bật tính năng tự khởi động theo OS cho Chrony.
systemctl restart chrony
systemctl enable chronyCheck source NTP Server xem đúng chưa bằng lệnh chronyc sources.
shell> chronyc sources
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* 10.237.7.250 3 7 377 10 -20us[ -27us] +/- 86msLệnh chronyc tracking sẽ cho bạn xem trạng thái đồng bộ NTP, nếu tham số leap status là normal tức là thời gian đã được đồng bộ với NTP Server.
shell> chronyc tracking
Reference ID : 0AED07FA (10.237.7.250)
Stratum : 4
Ref time (UTC) : Wed Oct 16 04:13:11 2024
System time : 0.000003247 seconds slow of NTP time
Last offset : -0.000007498 seconds
RMS offset : 0.000019078 seconds
Frequency : 1.251 ppm fast
Residual freq : -0.002 ppm
Skew : 0.061 ppm
Root delay : 0.055179413 seconds
Root dispersion : 0.040634494 seconds
Update interval : 129.4 seconds
Leap status : Normal4.2. Cài đặt MariaDB trên các Node 1 – 10.237.7.71 và Node 2 – 10.237.7.72.
apt-get install software-properties-common -y
apt update
apt install mariadb-server mariadb-client mariadb-common -yXác minh MariaDB đã cài đặt thành công bằng lệnh mariadb --version, phiên bản mới nhất thời điểm hiện tại là 15.1.
shell> mariadb --version
mariadb Ver 15.1 Distrib 10.6.18-MariaDB, for debian-linux-gnu (x86_64) using EditLine wrapper4.3. Cấu hình Galera Cluster trên Node 1 và Node 2.
Trên Node 1 (10.237.7.71).
Chỉnh sửa file cấu hình /etc/mysql/conf.d/galera.cnf:
cat > /etc/mysql/conf.d/galera.cnf << 'OEF'
[mysqld]
binlog_format=ROW
default-storage-engine=innodb
innodb_autoinc_lock_mode=2
bind-address=0.0.0.0
# Galera Provider Configuration
wsrep_on=ON
wsrep_provider=/usr/lib/galera/libgalera_smm.so
# Galera Cluster Configuration
wsrep_cluster_name="keystone"
wsrep_cluster_address="gcomm://10.237.7.71,10.237.7.72"
# Galera Synchronization Configuration
wsrep_sst_method=rsync
# Galera Node Configuration
wsrep_node_address="10.237.7.71"
wsrep_node_name="10.237.7.71"
OEFTrên Node 2 (10.237.7.72).
Thực hiện cấu hình tương tự, thay thế địa chỉ IP của Node 2:
cat > /etc/mysql/conf.d/galera.cnf << 'OEF'
[mysqld]
binlog_format=ROW
default-storage-engine=innodb
innodb_autoinc_lock_mode=2
bind-address=0.0.0.0
# Galera Provider Configuration
wsrep_on=ON
wsrep_provider=/usr/lib/galera/libgalera_smm.so
# Galera Cluster Configuration
wsrep_cluster_name="keystone"
wsrep_cluster_address="gcomm://10.237.7.71,10.237.7.72"
# Galera Synchronization Configuration
wsrep_sst_method=rsync
# Galera Node Configuration
wsrep_node_address="10.237.7.72"
wsrep_node_name="10.237.7.72"
OEFBật rsync trên cả hai node chính
sed -i 's/RSYNC_ENABLE=false/RSYNC_ENABLE=true/g' /etc/default/rsync
systemctl enable rsync
service rsync restart
Tắt UFW trên cả ba node (tính cả node garb).
ufw disable
systemctl disable ufw
systemctl stop ufwTắt MySQL trên cả hai node.
systemctl stop mysqlKhởi động cụm Galera trên Node 1
galera_new_clusterXác minh cụm tạo thành công bằng lệnh mysql -u root -p -e "SHOW STATUS LIKE 'wsrep_cluster_size'", nếu thành công, bạn sẽ thấy kết quả tương tự.
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 1 |
+--------------------+-------+Khởi động Node 2.
systemctl start mysqlVà kiểm tra trạng thái cụm bằng lệnh mysql -u root -p -e "SHOW STATUS LIKE 'wsrep_cluster_size'". Kết quả sẽ hiển thị rằng cụm đã có 2 node:
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 2 |
+--------------------+-------+4.4. Cài đặt Galera Arbitrator (Garbd) trên Node 3.
Cài đặt gói Garbd.
apt-get install galera-4 galera-arbitrator-4 -yĐây là phiên bản Garbd ở thời điểm hiện tại.
shell> garbd --version
INFO: 4.9.rSử dụng lệnh dưới để khởi chạy Garbd (Galera Arbitrator Daemon) một lần trong phiên làm việc hiện tại để kiểm tra và xác nhận quá trình thiết lập. Nó giúp bạn kiểm tra xem Garbd có thể kết nối vào cụm Galera hay không và ghi log vào /var/log/garbd.log.
garbd -a gcomm://10.237.7.71,10.237.7.72?pc.wait_prim=no -g keystone -l /var/log/garbd.logNếu thành công, cụm sẽ hiển thị 3 node:
shell> mysql -u root -p -e "SHOW STATUS LIKE 'wsrep_cluster_size'"
Enter password:
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 3 |
+--------------------+-------+Để đảm bảo Garbd chạy liên tục và tự động khi khởi động lại hệ thống, bạn cần thiết lập và kích hoạt dịch vụ bằng cách thiết lập cấu hình Garbd.
cat > /etc/default/garb <<-EOF
GALERA_NODES="10.237.7.71:4567 10.237.7.72:4567"
GALERA_GROUP="keystone"
GALERA_OPTIONS="pc.wait_prim=no"
LOG_FILE="/var/log/garbd.log"
EOFĐọc file /lib/systemd/system/garb.service để xác định dịch vụ garbd đang sử dụng người dùng nào để thực thi, trường hợp này dịch vụ garbd đang được cấu hình để chạy dưới quyền của người dùng nobody, như được thấy trong dòng User=nobody trong file cấu hình dịch vụ.
shell> cat /lib/systemd/system/garb.service
# Systemd service file for garbd
[Unit]
Description=Galera Arbitrator Daemon
Documentation=man:garbd(8)
Documentation=https://galeracluster.com/library/documentation/arbitrator.html
After=network.target
[Install]
WantedBy=multi-user.target
Alias=garbd.service
[Service]
User=nobody
ExecStart=/usr/bin/garb-systemd start
# Use SIGINT because with the default SIGTERM
# garbd fails to reliably transition to 'destroyed' state
KillSignal=SIGINT
TimeoutSec=2m
PrivateTmp=falseVì dịch vụ garbd đang chạy dưới quyền người dùng nobody, bạn cần tạo file log và gán đúng quyền truy cập cho người dùng này.
Chạy các lệnh sau:
mkdir -p /var/log/
touch /var/log/garbd.log
chown nobody:nogroup /var/log/garbd.log
chmod 644 /var/log/garbd.logSau khi đã tạo file log và thiết lập quyền truy cập đúng, khởi động lại dịch vụ garbd:
systemctl restart garbThay thế "nobody" bằng "root" trong file /etc/init.d/garb do script được thiết lập để chạy với quyền của người dùng "nobody", đó là một người dùng không có nhiều quyền trên hệ thống, thường dùng để hạn chế quyền truy cập của một dịch vụ vì lý do bảo mật. Tuy nhiên cần thận trọng vì việc chạy dịch vụ với quyền root có thể làm tăng rủi ro bảo mật.
sed -i 's/nobody/root/g' /etc/init.d/garbKhởi động lại dịch vụ garb và enable để nó khởi động cùng với hệ thống.
systemctl restart garb
systemctl enable garbSau khi khởi động lại dịch vụ, kiểm tra xem dịch vụ có đang chạy ổn định không.
shell> sudo systemctl status garb
● garb.service - Galera Arbitrator Daemon
Loaded: loaded (/lib/systemd/system/garb.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2024-10-16 10:44:01 +07; 3s ago
Docs: man:garbd(8)
https://galeracluster.com/library/documentation/arbitrator.html
Main PID: 3831 (garb-systemd)
Tasks: 4 (limit: 9389)
Memory: 2.7M
CPU: 17ms
CGroup: /system.slice/garb.service
├─3831 /bin/bash -ue /usr/bin/garb-systemd start
└─3833 /usr/bin/garbd -a gcomm://10.237.7.71:4567,10.237.7.72:4567 -g keystone -o pc.wait_prim=no -l /var/log/garbd.log
Oct 16 10:44:01 node73 systemd[1]: Started Galera Arbitrator Daemon.
Oct 16 10:44:01 node73 garb-systemd[3831]: Starting garbdTrên một trong hai node chính, kiểm tra bằng lệnh mysql -u root -p -e "SHOW STATUS LIKE 'wsrep_cluster_size'", nếu thành công, cụm sẽ hiển thị 3 node.
shell> mysql -u root -p -e "SHOW STATUS LIKE 'wsrep_cluster_size'"
Enter password:
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 3 |
+--------------------+-------+5. Kiếm tra kết quả.
Để kiểm tra và đảm bảo rằng hệ thống Galera Cluster của bạn đang hoạt động ổn định với Garbd (Galera Arbitrator), bạn có thể thực hiện các bước kiểm tra sau đây:
Tắt một node chính để kiểm tra sự duy trì quorum.
Nếu cluster của bạn đang hoạt động bình thường, bạn sẽ thấy output hiển thị số lượng node trong cluster, nếu bạn đã cấu hình Garbd, số lượng node sẽ là 3.
shell> mysql -u root -p -e "SHOW STATUS LIKE 'wsrep_cluster_size'"
Enter password:
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 3 |
+--------------------+-------+Bạn có thể tắt hoặc dừng một node chính (ví dụ Node 1 hoặc Node 2) để kiểm tra xem cluster có tiếp tục hoạt động bình thường không. Khi một node chính bị tắt, Garbd sẽ giúp giữ quorum.
Trên Node 1 (hoặc Node 2), thực hiện lệnh sau để dừng MySQL:
systemctl stop mysqlSau đó, kiểm tra lại trạng thái cluster từ node còn lại (ví dụ: Node 2) bằng cách chạy:
shell> mysql -u root -p -e "SHOW STATUS LIKE 'wsrep_cluster_size';"
Enter password:
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 2 |
+--------------------+-------+Kết quả sẽ hiển thị giá trị 2, nghĩa là cluster vẫn duy trì quorum với một node chính và Garbd.
Khôi phục node đã bị dừng.
Sau khi kiểm tra sự cố, khởi động lại node đã bị tắt:
systemctl start mysqlSố lượng node sẽ trở về 3 (bao gồm cả Garbd).
shell> mysql -u root -p -e "SHOW STATUS LIKE 'wsrep_cluster_size';"
Enter password:
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 3 |
+--------------------+-------+Kiểm tra replication.
Để đảm bảo replication hoạt động tốt giữa các node, bạn có thể thực hiện các bước sau:
Trên Node 1, tạo một bảng test và thêm dữ liệu vào bảng:
root@node71:~# mysql -u root -p -e "CREATE DATABASE testdb; USE testdb; CREATE TABLE test_table (id INT, data VARCHAR(100)); INSERT INTO test_table VALUES (1, 'Hello World');"
Enter password:Trên Node 2, kiểm tra xem bảng và dữ liệu đã được đồng bộ chưa. Nếu bạn thấy dữ liệu đã được đồng bộ, nghĩa là cluster của bạn đang hoạt động bình thường.
root@node72:~# mysql -u root -p -e "USE testdb; SELECT * FROM test_table;"
Enter password:
+------+-------------+
| id | data |
+------+-------------+
| 1 | Hello World |
+------+-------------+Giờ tạo một record trên Node 2.
root@node72:~# mysql -u root -p -e "USE testdb; INSERT INTO test_table VALUES (1, 'Hello World From Node 2');"
Enter password:Và kiểm tra record này trên Node 1. Nếu bạn thấy dữ liệu đã được đồng bộ, nghĩa là cluster của bạn đang hoạt động bình thường.
root@node71:~# mysql -u root -p -e "USE testdb; SELECT * FROM test_table;"
Enter password:
+------+-------------------------+
| id | data |
+------+-------------------------+
| 1 | Hello World |
| 1 | Hello World From Node 2 |
+------+-------------------------+Nếu các bước test trên hoàn thành và hệ thống vẫn hoạt động bình thường, bạn có thể yên tâm rằng cấu hình của bạn đã đúng. Garbd đã giúp duy trì quorum và tránh tình trạng cluster ngừng hoạt động khi có sự cố ở một node chính.
6. Kết luận.
Bằng cách thiết lập Galera Arbitrator (Garbd), bạn đã tăng cường tính sẵn sàng và ổn định của cụm Galera. Arbitrator giúp cụm có thể tiếp tục hoạt động bình thường ngay cả khi một trong các node chính gặp sự cố. Việc triển khai này giúp bạn duy trì hiệu suất và độ tin cậy của hệ thống cơ sở dữ liệu trong môi trường sản xuất.


{kind=link}